







声明:本文转自数数1234的博客
在竞赛中,遇到大数据时,往往读文件成了程序运行速度的瓶颈,需要更快的读取方式。相信几乎所有的C++学习者都在cin机器缓慢的速度上栽过跟头,于是从此以后发誓不用cin读数据。还有人说Pascal的read语句的速度是C/C++中scanf比不上的,C++选手只能干着急。难道C++真的低Pascal一等吗?答案是不言而喻的。一个进阶的方法是把数据一下子读进来,然后再转化字符串,这种方法传说中很不错,但具体如何从没试过,因此今天就索性把能想到的所有的读数据的方式都测试了一边,结果是惊人的。
竞赛中读数据的情况最多的莫过于读一大堆整数了,于是我写了一个程序,生成一千万个随机数到data.txt中,一共55MB。然后我写了个程序主干计算运行时间,代码如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
最简单的方法就算写一个循环scanf了,代码如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 1
可是效率如何呢?在我的电脑Linux平台上测试结果为2.01秒。接下来是cin,代码如下
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
出乎我的意料,cin仅仅用了6.38秒,比我想象的要快。cin慢是有原因的,其实默认的时候,cin与stdin总是保持同步的,也就是说这两种方法可以混用,而不必担心文件指针混乱,同时cout和stdout也一样,两者混用不会输出顺序错乱。正因为这个兼容性的特性,导致cin有许多额外的开销,如何禁用这个特性呢?只需一个语句std::iOS::sync_with_stdio(false);,这样就可以取消cin于stdin的同步了。程序如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
取消同步后效率究竟如何?经测试运行时间锐减到了2.05秒,与scanf效率相差无几了!有了这个以后可以放心使用cin和cout了。
接下来让我们测试一下读入整个文件再处理的方法,首先要写一个字符串转化为数组的函数,代码如下
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
把整个文件读入一个字符串最常用的方法是用fread,代码如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
上述代码有着惊人的效率,经测试读取这10000000个数只用了0.29秒,效率提高了几乎10倍!掌握着种方法简直无敌了,不过,我记得fread是封装过的read,如果直接使用read,是不是更快呢?代码如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
测试发现运行时间仍然是0.29秒,可见read不具备特殊的优势。到此已经结束了吗?不,我可以调用linux的底层函数mmap,这个函数的功能是将文件映射到内存,是所有读文件方法都要封装的基础方法,直接使用mmap会怎样呢?代码如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
经测试,运行时间缩短到了0.25秒,效率继续提高了14%。到此为止我已经没有更好的方法继续提高读文件的速度了。回头测一下Pascal的速度如何?结果令人大跌眼镜,居然运行了2.16秒之多。程序如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
为确保准确性,我又换到Windows平台上测试了一下。结果如下表:
方法/平台/时间(秒)
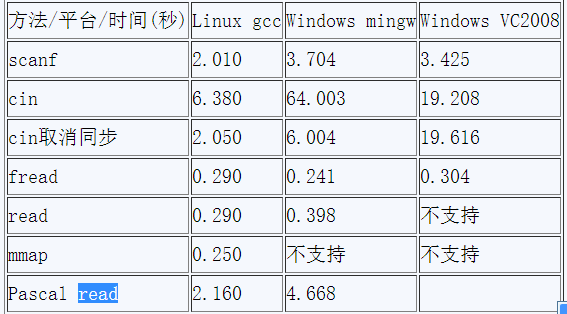
从上面可以看出几个问题
Linux平台上运行程序普遍比Windows上快。
Windows下VC编译的程序一般运行比MINGW(MINimal Gcc for Windows)快。
VC对cin取消同步与否不敏感,前后效率相同。反过来MINGW则非常敏感,前后效率相差8倍。
read本是linux系统函数,MINGW可能采用了某种模拟方式,read比fread更慢。
Pascal程序运行速度实在令人不敢恭维。
通过cin.tie与sync_with_stdio加速输入输出,可以将cin的速度接近scanf的速度,但具体要更具编译器的情况。
tie
tie是将两个stream绑定的函数,空参数的话返回当前的输出流指针。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
输出:
- 1
- 1
sync_with_stdio
这个函数是一个“是否兼容stdio”的开关,C++为了兼容C,保证程序在使用了std::printf和std::cout的时候不发生混乱,将输出流绑到了一起。
应用
在ACM里,经常出现数据集超大造成 cin TLE的情况。这时候大部分人(包括原来我也是)认为这是cin的效率不及scanf的错,甚至还上升到C语言和C++语言的执行效率层面的无聊争论。其实像上文所说,这只是C++为了兼容而采取的保守措施。我们可以在IO之前将stdio解除绑定,这样做了之后要注意不要同时混用cout和printf之类。
在默认的情况下cin绑定的是cout,每次执行 << 操作符的时候都要调用flush,这样会增加IO负担。可以通过tie(0)(0表示NULL)来解除cin与cout的绑定,进一步加快执行效率。
如下所示:
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
下面介绍最快的读取方法,将读入的直接转换为字符串 但一般题目很少卡这个,除非出题人故意卡你读入,这时候就需要开挂了….
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
结论:输出时尽量使用cout,输入时尽量使用scanf.
cin cout效率没scanf printf高为何用
主要有以下几个原因:
1.流输入输出对于基本类型来说使用很方便,不用手写格式控制字符串。
2.对于标准库的一些class来说,显然重载操作符也比自己写格式控制字符串要方便很多。
3.对于复杂的格式可以进行自定义操作符。
4.可读性更好(这个很多人有不同意见,见仁见智了)。
其实原理上来说流操作的效率比printf/scanf函数族更高,因为是在编译期确定操作数类型和调用的输出函数,不用在运行期解析格式控制字符串带来额外开销。不过标准流对象cin/cout为了普适性,继承体系很复杂,所以在对象的构造等方面会影响效率,因此总体效率比较低。如果根据特定的场景进行优化,效率可以更高一点。
C++中cin,cout是不是效率不如scanf,printf
十分正确,如果你是做io比赛的或者是做acm的,尽量不要用cin,cout,你试试打印99999999就知道,它们之间速度大概相差10几倍















 1364
1364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









