






最近在学习UFLDL Tutorial,这是一套关于无监督学习的教程。在此感觉Andrew Ng做的真的是非常认真。下面把我的代码贴出来,方便大家学习调试。所有代码已经过matlab调试通过。
Self-Taught Learning and Unsupervised Feature Learning练习
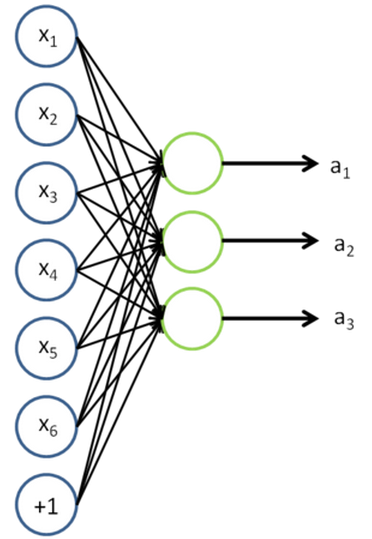
这一章实际上是把Sparse Autoencoder和Softmax Regression两章中的代码结合起来。所以在做这一章练习之前,必须把前面章节的练习做了。本章把mnist数据库中数字5-9当做无标记图像,用来训练稀疏编码的第一层权值。训练完毕后把这些权值保存起来。作为基。接下来让数字0-4通过这组基,相当于预处理后的数据。然后对预处理后的数据用Softmax Regression做有监督学习,训练出第二层权值。如下图,原始输入为x,提取特征后得到a,再把a作为softmax的输入进行训练并分类即可。
代码编写
首先把需要的之前的一些.m文件拷过来。
Step 0. 参数设置。无需编写。
Step 1. 读取mnist数据。无需编写。
Step 2. 用Sparse Autoencoder训练第一层权重。代码:
% 该段代码参考Sparse Autoencoder中train.m的代码(UFLDL给出)
addpath minFunc/
options.Method = 'lbfgs';
options.maxIter = 400; % Maximum number of iterations of L-BFGS to run
options.display = 'on';
visibleSize = size(unlabeledData,1);
[opttheta, cost] = minFunc( @(p) sparseAutoencoderCost(p, ...
visibleSize, hiddenSize, ...
lambda, sparsityParam, ...
beta, unlabeledData), ...
theta, options);
sampleN = size(data,2); %样本数
activation = sigmoid(W1*data + repmat(b1,1,sampleN)); %用Sparse Autoencoder得到的基预处理数据Step 4. 训练Softmax分类器。代码:
options2.maxIter = 100; %Softmax训练迭代次数
[inputSize,sampleN] = size(trainFeatures); %[输入维数,样本数]
[softmaxModel] = softmaxTrain(inputSize, numLabels, lambda, trainFeatures, trainLabels, options2); %训练Softmax分类器Step 5. 测试Softmax分类器。代码:
[pred] = softmaxPredict(softmaxModel, testFeatures); %测试Softmax分类器
下面我们将分别绘出Sparse Autoencoder迭代次数10,100,400的图像及准确率。Softmax训练统一迭代100次。

上图准确率:96.60%

上图准确率:97.33%

上图准确率:98.16%
可以看到通过Sparse Autoencoder的无监督学习,第一层权重很好地提取了笔迹信息。注意我们使用的Sparse Autoencoder的网络结构是784-200-784,Softmax的网络结构是784-200-10。按照UFLDL的说法,如果Softmax层用784-(784+200)-10的网络结构,即联合新特征和原始输入,会得到更好的效果。
小结
这一章难度不大。把Sparse Autoencoder和Softmax组合起来即可。本章的方法与普通神经网络方法的区别在于,普通神经网络需要labeled数据,而本章的方法可以用unlabeled的数据。而现实中labeled数据是很少的,这是本章方法优点所在。另外诸如稀疏因子beta,权值正则项lamda等是UFLDL帮我们定好的。实际应用中调节这些参数也是一个比较重要的内容。














 5989
5989











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









