









关于堆数据结构的时间复杂度分析有点疑问,一直没想清楚为啥是线性的,
这次把算法导论里求得思想和大家分享下~~
这里讨论的都是二叉树!
算法导论假定array 是1开始的 已知a[1..n]
假定叶子高度为0,根高度为树高度
?O(nlogn)
O(h)
这个就是我之前提到的,估计时间复杂度不够准确,虽然建堆复杂度确实低于O(nlogn) 但是由于很多节点的高度较低,因此可以获得更准确的渐进复杂度:
首先有一些notation,结论均在n个结点的树前提下
1.n个节点的树,高度为O(logn),准确计算公式h=下界(log2(n)) (下标1开始计算的)
2.对于高度为h的节点,执行FilterDown的时间复杂度为O(h):从当前节点向下比较,交换和比较的次数最多为2*h
3.高度为h层,至多有上届(n/(2^(h+1)))个结点:2^(上界(log2n)-h)推到得出
建堆的时间复杂度:
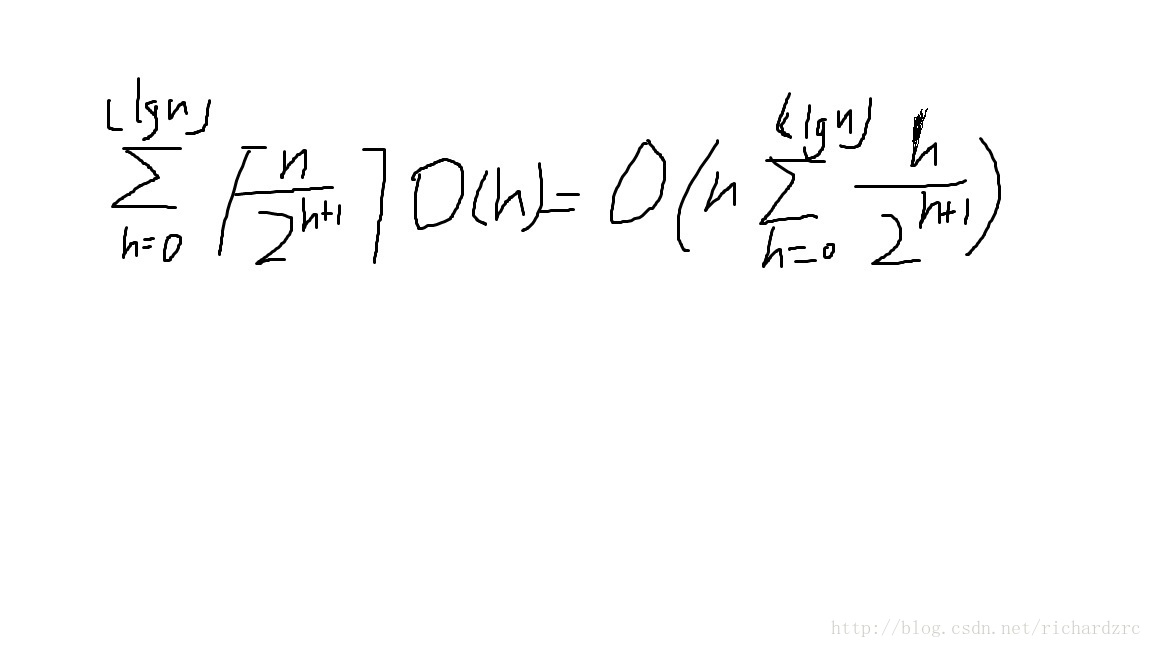
用一个等差乘等比数列的求和公式可以算出:
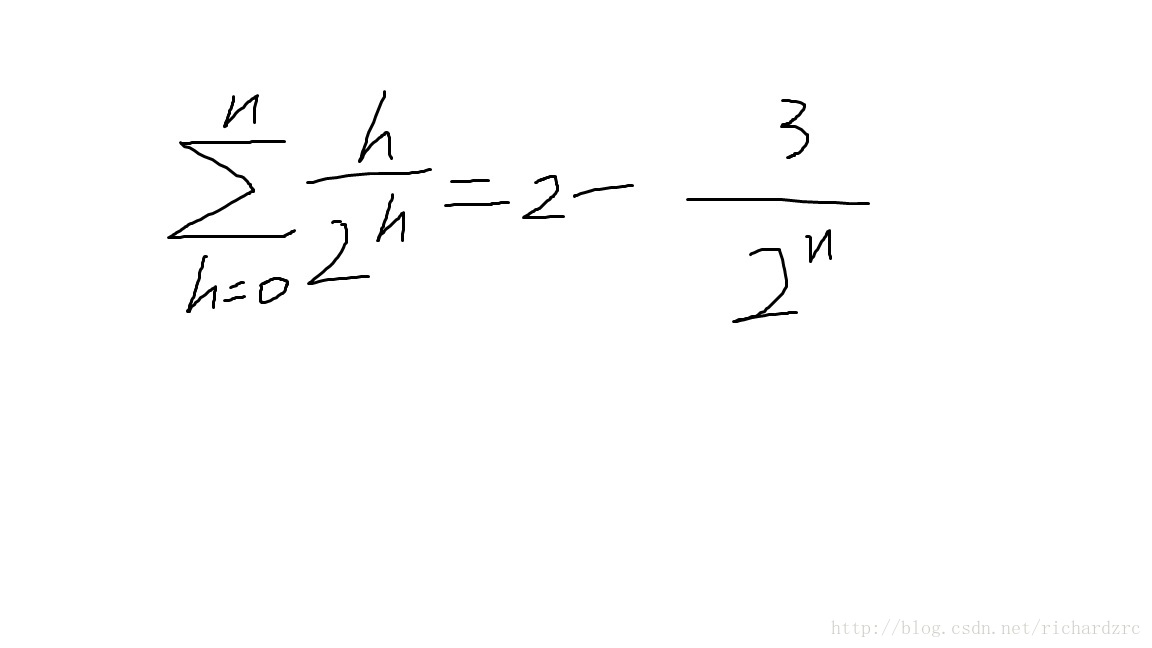
今天看到一篇N个数求第K大的数的问题,想到更精确的时间复杂度是O(4n),因为FilterDown里面的每一轮循环最多有4次操作,这也可以另一方面说明虽说线性,但是操作次数也会比较多
这次把算法导论里求得思想和大家分享下~~
这里讨论的都是二叉树!
算法导论假定array 是1开始的 已知a[1..n]
假定叶子高度为0,根高度为树高度
?O(nlogn)
void CreatHeap(int* a, int n)
{
for i=[logn]->1//logn 次loop
FilterDown(i);
}O(h)
void FilterDown(int i)//MaxHeap
{
int x=a[i];
while(not to end)
{
j=2*i;
if((j+1)>n)//判断a[j+1]是否存在
break;
else
{
if(a[j]<a[j+1])
j++;
}
if(a[i]<a[j])
a[i]=a[j];
i=j;
}
a[j]=x;
}这个就是我之前提到的,估计时间复杂度不够准确,虽然建堆复杂度确实低于O(nlogn) 但是由于很多节点的高度较低,因此可以获得更准确的渐进复杂度:
首先有一些notation,结论均在n个结点的树前提下
1.n个节点的树,高度为O(logn),准确计算公式h=下界(log2(n)) (下标1开始计算的)
2.对于高度为h的节点,执行FilterDown的时间复杂度为O(h):从当前节点向下比较,交换和比较的次数最多为2*h
3.高度为h层,至多有上届(n/(2^(h+1)))个结点:2^(上界(log2n)-h)推到得出
建堆的时间复杂度:
用一个等差乘等比数列的求和公式可以算出:
将下界(logn)带入之后,可以得到结论:
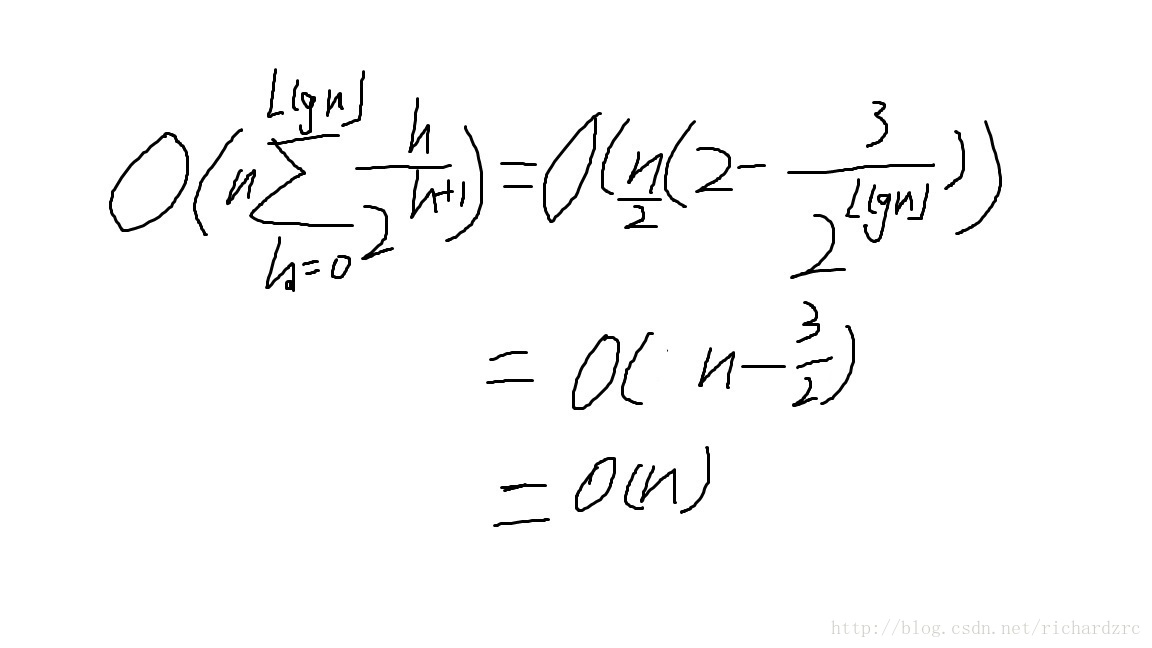
今天看到一篇N个数求第K大的数的问题,想到更精确的时间复杂度是O(4n),因为FilterDown里面的每一轮循环最多有4次操作,这也可以另一方面说明虽说线性,但是操作次数也会比较多














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









