






小问题可能存在大问题,希望大神帮忙解答
求大神帮忙解决同样的代码:
setMaster("local")可以运行,但是设置成setMaster("local[3]")或setMaster("local[*]")则报错。
一、Spark中本地运行模式
Spark中本地运行模式有3种,如下
(1)local 模式:本地单线程运行;
(2)local[k]模式:本地K个线程运行;
(3)local[*]模式:用本地尽可能多的线程运行。
二、读取的数据如下
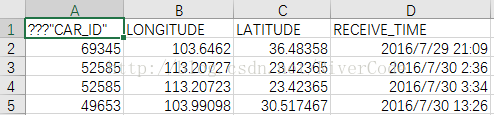
三、牵扯数组越界代码如下
val pieces = line.replaceAll("\"" , "")
val carid = pieces.split(',')(0)
val lngstr = pieces.split(',')(1)
val latstr = pieces.split(',')(2)
var lng=BigDecimal(0)
var lat=BigDecimal(0)
try {
lng = myround(BigDecimal(lngstr), 3)
lat = myround(BigDecimal(latstr), 3)
}catch {
case e: NumberFormatException => println(".....help......"+lngstr+"....."+latstr)
}四、遇到的local、local[k]、local[*]问题
Spark 中Master初始化如下:
val sparkConf = new SparkConf().setMaster("local").setAppName("count test")问题描述如下:
代码其他部门没有改动,只是改变setMaster(),则出现不同结果:
(1)如果 setMaster()写成setMaster("local"),代码正确运行;
(2)如果写成 setMaster("local[3]")则报错;
(3)如果写成 setMaster("local[*]")则报错,且与(2)中报错内容一样;
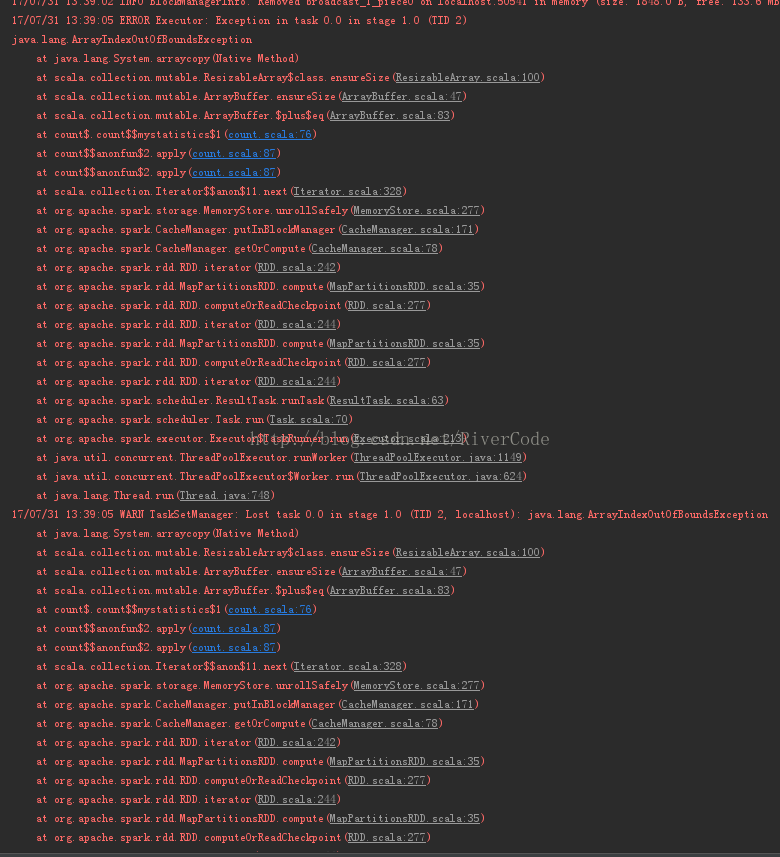
且 setMaster("local[3]")报错内容与setMaster("local[*]")报错内容一样,报错内容如下:
17/07/31 13:39:01 INFO HadoopRDD: Input split: file:/E:/data/gps201608.csv:0+7683460
17/07/31 13:39:02 INFO BlockManagerInfo: Removed broadcast_1_piece0 on localhost:50541 in memory (size: 1848.0 B, free: 133.6 MB)
17/07/31 13:39:05 ERROR Executor: Exception in task 0.0 in stage 1.0 (TID 2)
java.lang.ArrayIndexOutOfBoundsException
at java.lang.System.arraycopy(Native Method)
at scala.collection.mutable.ResizableArray$class.ensureSize(ResizableArray.scala:100)
at scala.collection.mutable.ArrayBuffer.ensureSize(ArrayBuffer.scala:47)
at scala.collection.mutable.ArrayBuffer.$plus$eq(ArrayBuffer.scala:83)
at count$.count$$mystatistics$1(count.scala:76)
at count$$anonfun$2.apply(count.scala:87)
at count$$anonfun$2.apply(count.scala:87)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:328)
at org.apache.spark.storage.MemoryStore.unrollSafely(MemoryStore.scala:277)
at org.apache.spark.CacheManager.putInBlockManager(CacheManager.scala:171)
at org.apache.spark.CacheManager.getOrCompute(CacheManager.scala:78)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:242)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:277)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:244)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:277)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:244)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:63)
at org.apache.spark.scheduler.Task.run(Task.scala:70)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:213)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
17/07/31 13:39:05 WARN TaskSetManager: Lost task 0.0 in stage 1.0 (TID 2, localhost): java.lang.ArrayIndexOutOfBoundsException
at java.lang.System.arraycopy(Native Method)
at scala.collection.mutable.ResizableArray$class.ensureSize(ResizableArray.scala:100)
at scala.collection.mutable.ArrayBuffer.ensureSize(ArrayBuffer.scala:47)
at scala.collection.mutable.ArrayBuffer.$plus$eq(ArrayBuffer.scala:83)
at count$.count$$mystatistics$1(count.scala:76)
at count$$anonfun$2.apply(count.scala:87)
at count$$anonfun$2.apply(count.scala:87)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:328)
at org.apache.spark.storage.MemoryStore.unrollSafely(MemoryStore.scala:277)
at org.apache.spark.CacheManager.putInBlockManager(CacheManager.scala:171)
at org.apache.spark.CacheManager.getOrCompute(CacheManager.scala:78)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:242)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:277)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:244)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:277)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:244)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:63)
at org.apache.spark.scheduler.Task.run(Task.scala:70)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:213)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
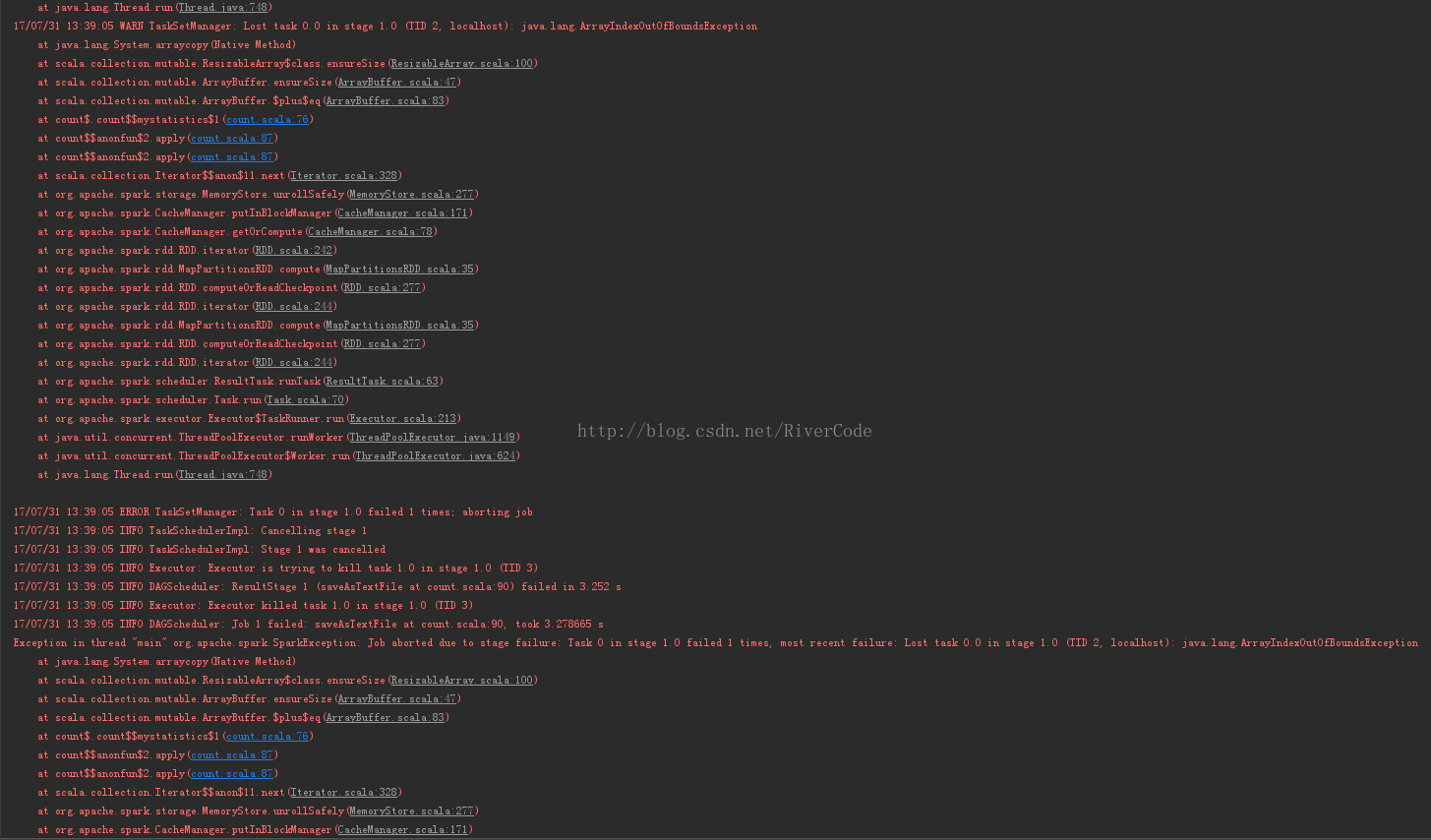
17/07/31 13:39:05 ERROR TaskSetManager: Task 0 in stage 1.0 failed 1 times; aborting job
17/07/31 13:39:05 INFO TaskSchedulerImpl: Cancelling stage 1
17/07/31 13:39:05 INFO TaskSchedulerImpl: Stage 1 was cancelled
17/07/31 13:39:05 INFO Executor: Executor is trying to kill task 1.0 in stage 1.0 (TID 3)
17/07/31 13:39:05 INFO DAGScheduler: ResultStage 1 (saveAsTextFile at count.scala:90) failed in 3.252 s
17/07/31 13:39:05 INFO Executor: Executor killed task 1.0 in stage 1.0 (TID 3)
17/07/31 13:39:05 INFO DAGScheduler: Job 1 failed: saveAsTextFile at count.scala:90, took 3.278665 s
Exception in thread "main" org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 1.0 failed 1 times, most recent failure: Lost task 0.0 in stage 1.0 (TID 2, localhost): java.lang.ArrayIndexOutOfBoundsException
at java.lang.System.arraycopy(Native Method)
at scala.collection.mutable.ResizableArray$class.ensureSize(ResizableArray.scala:100)
at scala.collection.mutable.ArrayBuffer.ensureSize(ArrayBuffer.scala:47)
at scala.collection.mutable.ArrayBuffer.$plus$eq(ArrayBuffer.scala:83)
at count$.count$$mystatistics$1(count.scala:76)
at count$$anonfun$2.apply(count.scala:87)
at count$$anonfun$2.apply(count.scala:87)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:328)
at org.apache.spark.storage.MemoryStore.unrollSafely(MemoryStore.scala:277)
at org.apache.spark.CacheManager.putInBlockManager(CacheManager.scala:171)
at org.apache.spark.CacheManager.getOrCompute(CacheManager.scala:78)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:242)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:277)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:244)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:277)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:244)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:63)
at org.apache.spark.scheduler.Task.run(Task.scala:70)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:213)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
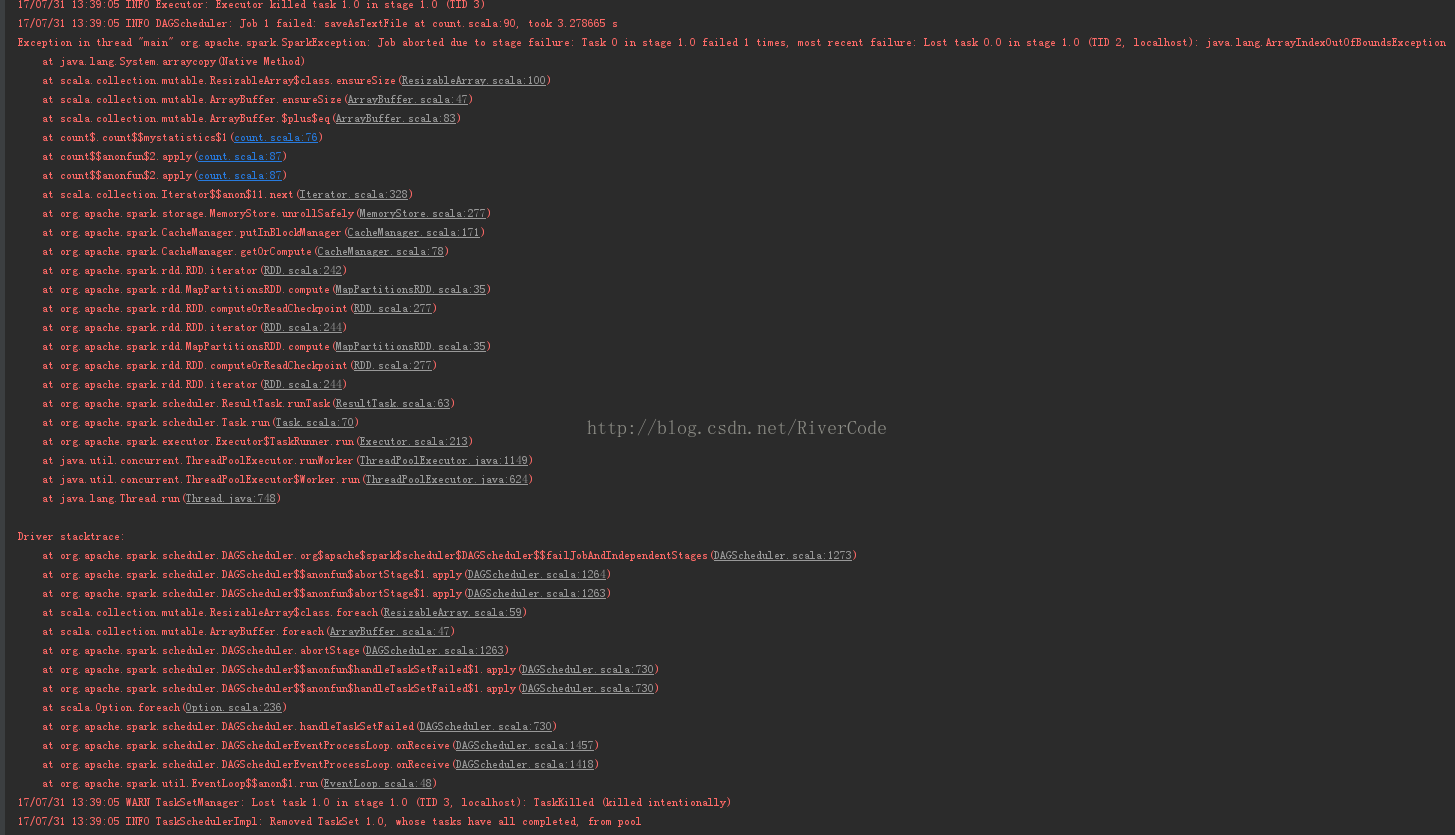
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:1273)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1264)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1263)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1263)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:730)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:730)
at scala.Option.foreach(Option.scala:236)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:730)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1457)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1418)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:48)
17/07/31 13:39:05 WARN TaskSetManager: Lost task 1.0 in stage 1.0 (TID 3, localhost): TaskKilled (killed intentionally)
17/07/31 13:39:05 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
17/07/31 13:39:05 INFO SparkContext: Invoking stop() from shutdown hook
五、奇怪问题
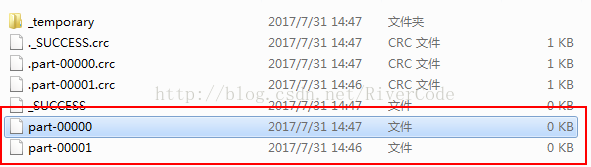
过了一段时间,我什么也没动,发现把Master设置成local[3]可以运行,生成2个结果文件,但都为空,如下图所示:














 3211
3211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









