




 本文介绍PDF文件解析的基本概念、PDFMiner工具的使用方法及解析过程,包括PDF文件结构、解析流程、布局分析等内容。同时提供示例代码帮助理解如何利用PDFMiner从PDF文件中提取文本信息。
本文介绍PDF文件解析的基本概念、PDFMiner工具的使用方法及解析过程,包括PDF文件结构、解析流程、布局分析等内容。同时提供示例代码帮助理解如何利用PDFMiner从PDF文件中提取文本信息。
原文地址: http://euske.github.io/pdfminer/programming.html
软件版本:pdfminer-20140328
翻译:robolinux
时间:20150110
-----------------------------------------------------------------------------------------------------------
概览:
PDF格式不是规范格式. 尽管它被叫做"PDF文档", 但并不像word或者html文档。PDF的表现更像一张图片。PDF更像是在一张纸的各个准确的位置上把内容都摆放出来。大部分情况下,没有逻辑结构,比如句子或段落,并且不能自适应页面大小的调整。PDFMiner尝试通过猜测它们的布局来重建它们的结构,但是不保证一定能工作。我知道这样很难看,但是,PDF确实不够规范。
更多关于PDF内部结构的技术详情,请见《如何手工提取PDF内容》。
http://www.youtube.com/watch?v=k34wRxaxA_c
http://www.youtube.com/watch?v=_A1M4OdNsiQ
http://www.youtube.com/watch?v=sfV_7cWPgZE
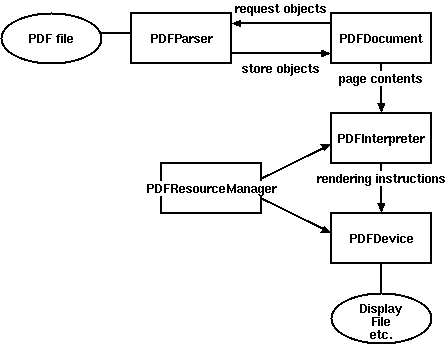
由于PDF文件有如此大和复杂的结构,完整解析PDF文件很费时费力。好吧,大多数PDF工作中,很多模块是不需要加进来的。因此 PDFMiner 采用了一个懒惰分析的策略,就是只分析所需要的部分。解析时候,至少需要2个核心类,PDFParser 和 PDFDocument。这两个模块配合其他模块来使用。
PDFParser 从文件中获取数据
PDFDocument 存储文档数据结构到内存中
PDFPageInterpreter 解析page内容
PDFDevice 把解析到的内容转化为你需要的东西
PDFResourceManager存储共享资源,例如字体或图片
下图显示了PDFMiner中各个类之间的关系。
基本用法:
下面是解析pdf的一个典型方法:
#!/usr/bin/python
#--*-- coding:utf-8 --*--
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage
from pdfminer.pdfpage import PDFTextExtractionNotAllowed
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.pdfdevice import PDFDevice
from pdfminer.layout import LAParams
from pdfminer.converter import PDFPageAggregator
password = ''
#打开pdf文件
fp = open('test.pdf','rb')
#从文件句柄创建一个pdf解析对象
parser = PDFParser(fp)
#创建pdf文档对象,存储文档结构
document = PDFDocument(parser,password)
#创建一个pdf资源管理对象,存储共享资源
rsrcmgr = PDFResourceManager()
#创建一个device对象
device = PDFDevice(rsrcmgr)
#创建一个解释对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
#处理包含在文档中的每一页
for page in PDFPage.create_pages(document):
interpreter.process_page(page)
通过布局分析:
#!/usr/bin/python
#--*-- coding:utf-8 --*--
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage
from pdfminer.pdfpage import PDFTextExtractionNotAllowed
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.pdfdevice import PDFDevice
from pdfminer.layout import LAParams
from pdfminer.converter import PDFPageAggregator
password = ''
#打开pdf文件
fp = open('test.pdf','rb')
#从文件句柄创建一个pdf解析对象
parser = PDFParser(fp)
#创建pdf文档对象,存储文档结构
document = PDFDocument(parser,password)
#创建一个pdf资源管理对象,存储共享资源
rsrcmgr = PDFResourceManager()
laparams = LAParams()
#创建一个device对象
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
#创建一个解释对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
#处理包含在文档中的每一页
for page in PDFPage.create_pages(document):
interpreter.process_page(page)
layout = device.get_result()
下图显示了这些对象之间的关系。
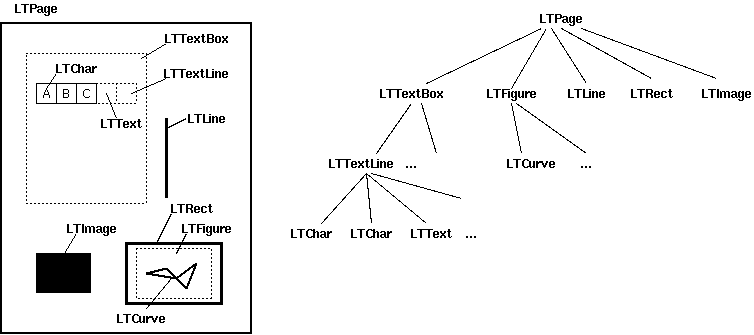
LTPage
代表一个完整的页面。可以包含子对象,例如LTTextBox,LTFigure,LTImage,LTRect,LTCurve和LTLine.LTTextBox
它包含 LTTextLine 对象的列表
代表一组被包含在矩形区域中的文本
需要注意的是,该box是根据几何学分析得到的,并不一定准确地表现为该文本的逻辑范围
get_text()方法可以返回文本内容
LTTextLine
包含一个LTChar对象的列表,表现为单行文本
字符表现为一行或一列,取决于文本书写方式
get_text()方法返回文本内容
LTChar / LTAnno
代表一个在文本中的真实的字母,作为一个unicode字符串
LTChar 对象有真实的分隔符
LTAnno 对象没有,是虚拟分隔符,按照两个字符之间的关系,布局分析器插入虚拟分隔符
LTFigure
代表一个被PDF Form对象使用的区域
pdf form适用于目前的图表(present figures)或者页面中植入的另一个pdf文档图片。LTFigure对象可以递归
LTImage
代表一个图形对象。可以是JPEG或者其他格式,但PDFMiner目前没有花太多精力在图形对象上。
LTLine
代表一根直线。用来分割文本或图表(figures)。
LTRect
代表一个矩形。
用来框住别的图片或者图表。
LTCurve
代表一个贝塞尔曲线。
也可以从下面URL获得更多完整的示例。
http://denis.papathanasiou.org/?p=343
PDFMiner支持访问文档目录的功能。
#!/usr/bin/python
#--*-- coding:utf-8 --*--
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
password = ''
fp = open('PURCHASE ORDER-62142.pdf','rb')
parser = PDFParser(fp)
document = PDFDocument(parser,password)
outlines = document.get_outlines()
for (level,title,dest,a,se) in outlines:
print (level, title)PDF文档没有目录时会报:
raise PDFNoOutlines
pdfminer.pdfdocument.PDFNoOutlines
一些pdf文档使用页号作为目录指向,另外的文档则使用页号和页面中的物理位置。由于pdf文档没有逻辑结构,并且不支持从外部指向页内对象,所以没有办法准确告知这些目录指向文本的哪一部分。

















 1511
1511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









