









一. 使用一个Block
把一个block分成N个thread, 和N个block, 每个block只有一个thread相比, 编程有两点不同:
1. add<<<N,1>>>(dev_a,dev_b,dev_c)改为add<<<1,N>>>(dev_a,dev_b,dev_c)
2. 寻址用的是threadIdx.x, 不是blockIdx.x
使用一个block, 分成N个thread做两个向量的相加:
#include "../common/book.h"
#define N 10
__global__ void add(int *a, int *b, int *c)
{
int tid=threadIdx.x;
if(tid<N)
c[tid]=a[tid]+b[tid];
}
int main(void)
{
int a[N], b[N], c[N];
int *dev_a, *dev_b, *dev_c;
//allocate the memory on GPU
HANDLE_ERROR(cudaMalloc( (void**)&dev_a, N*sizeof(int)));
HANDLE_ERROR(cudaMalloc( (void**)&dev_b, N*sizeof(int)));
HANDLE_ERROR(cudaMalloc( (void**)&dev_c, N*sizeof(int)));
//fill the array a and b on CPU
for (int i=0; i<N; i++)
{
a[i]=i;
b[i]=i*i;
}
//copy the array a and b to GPU
HANDLE_ERROR(cudaMemcpy(dev_a,
a,
N*sizeof(int),
cudaMemcpyHostToDevice));
HANDLE_ERROR(cudaMemcpy(dev_b,
b,
N*sizeof(int),
cudaMemcpyHostToDevice));
//
add<<<1,N>>>(dev_a,dev_b,dev_c);
//
HANDLE_ERROR(cudaMemcpy(c,
dev_c,
N*sizeof(int),
cudaMemcpyDeviceToHost));
//display the result
for (int i=0; i<N; i++)
{
printf("%d +%d = %d \n", a[i], b[i], c[i]);
}
//free the device memory.
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
return 0;
}
2. 使用多个Block
maxThreadsPerBlock限制了每一个block使用的thread数量.
所以如果thread不够用, 就要使用多个block.
CUDA允许创建2-D的block阵列.
每个block可以创建3-D的thread阵列.
1. 寻址方式的改变
如果创建1-D的block阵列和1-D的thread阵列.
thread寻址方式就是:
int tid = threadIdx.x + blockIdx.x * blockDim.x;
blockDim是built-in 变量. 存储的是每个block中每个维度上thread的个数, 缺省值为1.
而gridDim存储的是grid中每个维度上block的个数.
2. kernel launch方法的改变
kernel launch方法就改成了:
add<<<(N+127)/128, 128>>>( dev_a, dev_b, dev_c );
使用多个block处理513长度的数组相加:
#include "../common/book.h"
#define N 513
__global__ void add(int *a, int *b, int *c)
{
int tid=threadIdx.x + blockIdx.x * blockDim.x;
if(tid<N)
c[tid]=a[tid]+b[tid];
}
int main(void)
{
int a[N], b[N], c[N];
int *dev_a, *dev_b, *dev_c;
//allocate the memory on GPU
HANDLE_ERROR(cudaMalloc( (void**)&dev_a, N*sizeof(int)));
HANDLE_ERROR(cudaMalloc( (void**)&dev_b, N*sizeof(int)));
HANDLE_ERROR(cudaMalloc( (void**)&dev_c, N*sizeof(int)));
//fill the array a and b on CPU
for (int i=0; i<N; i++)
{
a[i]=i;
b[i]=i;
}
//copy the array a and b to GPU
HANDLE_ERROR(cudaMemcpy(dev_a,
a,
N*sizeof(int),
cudaMemcpyHostToDevice));
HANDLE_ERROR(cudaMemcpy(dev_b,
b,
N*sizeof(int),
cudaMemcpyHostToDevice));
//
add<<<(N+127)/128,128>>>(dev_a,dev_b,dev_c);
//
HANDLE_ERROR(cudaMemcpy(c,
dev_c,
N*sizeof(int),
cudaMemcpyDeviceToHost));
//display the result
for (int i=0; i<N; i++)
{
printf("%d +%d = %d \n", a[i], b[i], c[i]);
}
//free the device memory.
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
return 0;
}输出:
3. 使用多个block多个threads生成波纹图
#include "../common/book.h"
#include "../common/gpu_anim.h"
#include "../common/cpu_anim.h"
#define DIM 512
struct DataBlock{
unsigned char *dev_bitmap;
CPUAnimBitmap *bitmap;
};
//clean up memory allocated on the GPU
void cleanup(DataBlock *d)
{
cudaFree(d->dev_bitmap);
}
__global__ void kernel(unsigned char *ptr, int ticks)
{
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
float fx = x - DIM/2;
float fy = y - DIM/2;
float d = sqrtf(fx * fx + fy * fy);
unsigned char grey = (unsigned char)(128.0f + 127.0f * cos(d/10.0f - ticks/7.0f)/(d/10.0f + 1.0f));
//bitmap 四个通道赋值
ptr[offset*4 + 0] = grey;
ptr[offset*4 + 1] = grey;
ptr[offset*4 + 2] = grey;
ptr[offset*4 + 3] = 255;
}
void generate_frame(DataBlock *d, int ticks)
{
// block和thread阵列都是2-D的.
dim3 blocks(DIM/16,DIM/16);
dim3 threads(16,16);
//没有输入数组或者图像, 所以没有向device拷贝的步骤.
kernel<<<blocks,threads>>>(d->dev_bitmap, ticks);
HANDLE_ERROR(cudaMemcpy(d->bitmap->get_ptr(),
d->dev_bitmap,
d->bitmap->image_size(),
cudaMemcpyDeviceToHost));
}
int main(void)
{
DataBlock data;
CPUAnimBitmap bitmap(DIM,DIM, &data);
data.bitmap = &bitmap;
HANDLE_ERROR(cudaMalloc( (void**)&data.dev_bitmap,
bitmap.image_size() ) );
bitmap.anim_and_exit( (void (*)(void*, int))generate_frame,
(void (*)(void*))cleanup);
}输出动画:
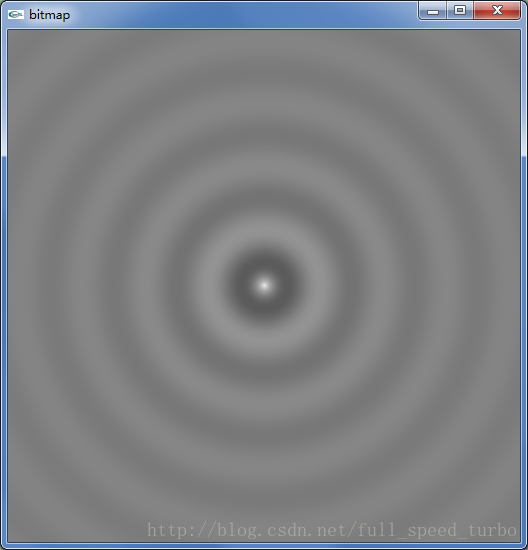














 3101
3101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









