







机器学习(一)
感知机
感知机(perceptron)作为机器学习中最最基本也是最最简单的一个模型,其重要性不言而喻。首先感知机是一个二分类的线性模型,二分类表示输出结果只有两个,一般用y={-1,+1}表示,+1表示正例,-1表示负例;线性则表示可以用一个分离超平面将输入空间的实例划分为两类,投影到二维空间即表示用一条直线将输入样本进行划分,如图:
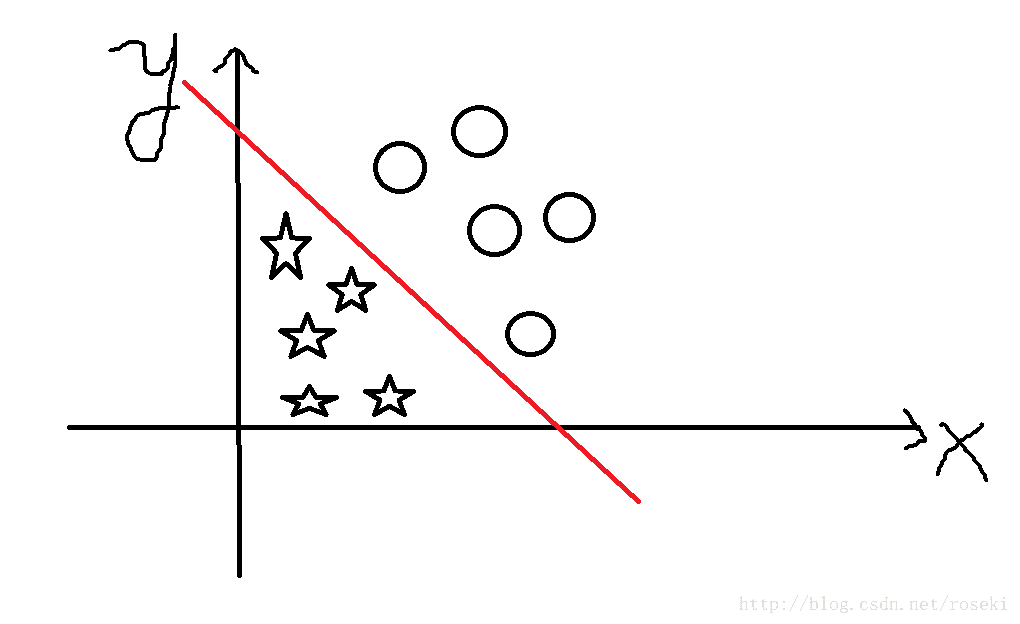
其中红色即我们所要求的感知机模型,为一条直线。
感知机模型定义的输入空间到输出空间的函数为:
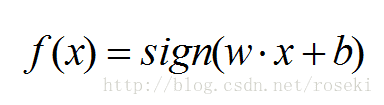
其中x表示输入特征,w表示权重,b表示偏值,sign函数为:
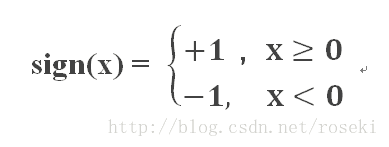
也就是说,当大于等于0时,感知机将x判别为+1类,当小于0时,判别为-1类。由此可见,感知机其实就是找到一个合适的w与b,使得输入x后通过sign函数能够将其正确划分。因此我们的目的就是找到一个正确的分离超平面。(因为现实中输入大多数是多维的)
应用中,我们先随机初始化w与b,然后根据损失函数进行优化,最后得到感知机模型。感知机的损失函数考虑的是误分类点到分离超平面的总距离,意思就是说我们有一个还未训练好的超平面,首先找出误分类点,然后计算这些所有误分类点到超平面的距离,如图所示:
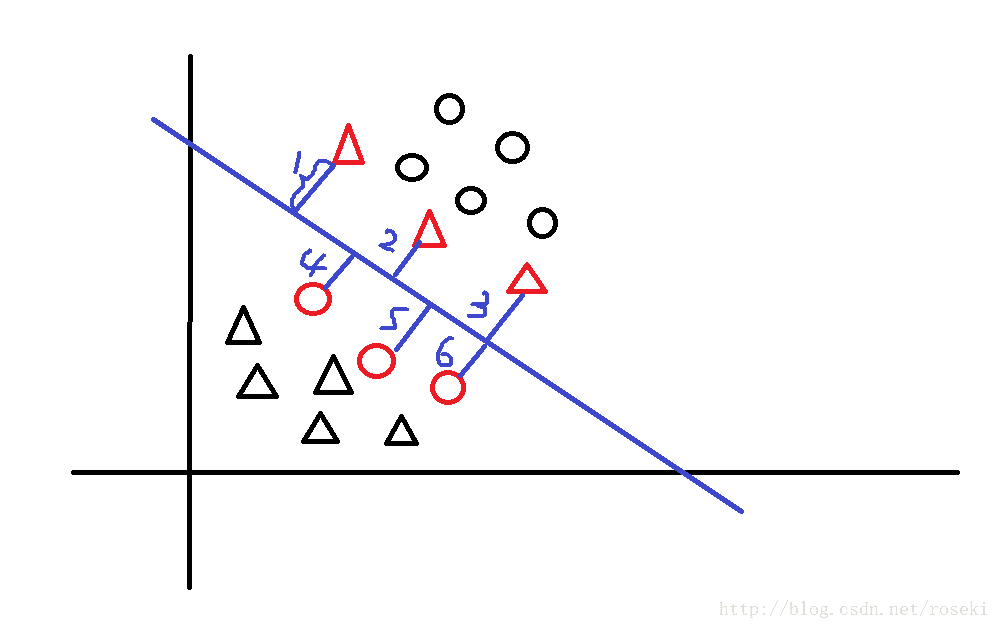
其中红色样本表示误分类点,蓝色直线表示分离超平面,1,2,3,4,5,6分别表示误分类点到超平面的距离,我们要做的就是将这6个距离求和加起来。
其中分离超平面为:
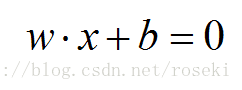
点到平面的距离公式为:
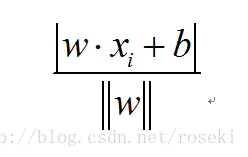
其中xi为空间中的点,为w的L2范数。
现在考虑误分类点到平面的距离,对于误分类点,当时w.x+b>0时,感知机将其判别为-1类,即y= -1;反之当<0时,判别为+1类,即y=1。因此误分类点在距离公式中|w.x+b|,可表示为 -y(w.x+b),(y始终等于1或者-1,且对于误分类点来说,始终成立),则某一个误分类点到平面的距离为:
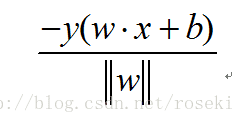
所有的误分类点到平面的距离为:
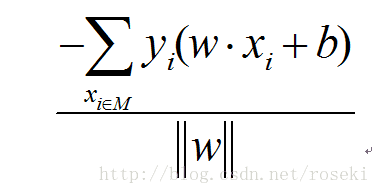
M为误分类点集合,||w||因为为常数,可以不考虑,去掉后就得到了感知机的损失函数:
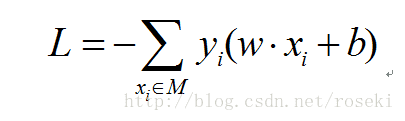
当误分类点越少,这个距离就越小,因此我们的目标就变成最小化该损失函数。优化过程为随机选取一个误分类点(一个!), 利用梯度下降法更新w与b:
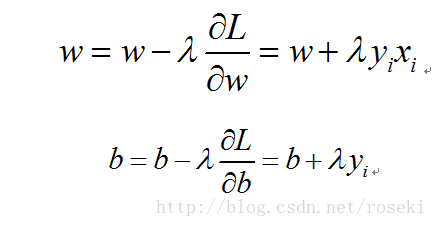
其中ƛ为学习率,不停如此迭代就可以最小化损失函数。
值得注意一点的是感知机对w,b以及ƛ的初始值敏感,不同初始值优化后可能对应不同的最优分离超平面,因此感知机的解不是唯一固定的,如果加上一些约束条件,即可得到唯一超平面,这就是线性SVM的思考方法。以后总结。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









