







线性表(上)中只介绍了链式存储的单链表。单链表有许多的局限性,本篇分析能改善这些局限性的操作。
1.循环链表
循环链表的操作很简单,只需要把单链表的最后一个结点的指针域指向表头结点即可,如下所示。
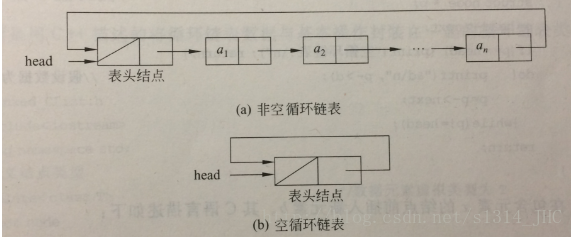
下面用一个程序把循环链表的基本操作串起来,代码比较长,因此把代码上传到CSDN下载中,进行了详细注释,并在Win32环境下编译成功,需要的可以下载。接下来就解释各个函数的功能。
建立新的空循环链表(构造函数实现):
template <class T>
linked_CList<T>::linked_CList()
{
node<T> *p;
p=new node<T>; //申请一个表头结点
p->d=0; p->next=p;
head=p;
return;
}
插入操作(在元素x之前插入元素b,图见线性表(上)):
template <class T>
void linked_CList<T>::ins_linked_CList(T x, T b)
{
node<T> *p, *q;
p=new node<T>; //申请一个新结点
p->d=b; //置新结点的数据域
q=head;
while ((q->next!=head)&&(((q->next)->d)!=x)) //不是空链表并且不是x之前的结点
q=q->next; //寻找包含元素x的前一个结点q
p->next=q->next; q->next=p; //新结点p插入到结点q之后
return;
}
删除操作(删除元素x,图见线性表(上) ):
template <class T>
int linked_CList<T>::del_linked_CList(T x)
{
node<T> *p, *q;
q=head;
while ((q->next!=head)&&(((q->next)->d)!=x))
q=q->next; //寻找包含元素x的前一个结点q
if (q->next==head) return(0); //循环链表中无删除的元素
p=q->next; //得到包含x的结点
q->next=p->next; //删除q的下一个结点p
delete p; //释放结点p的存储空间
return(1);
}
总体的代码流程如下,实现了创建、插入、删除与遍历的功能。
#include "linked_Clist.h"
int main()
{
linked_CList<int> s;
cout <<"第1次扫描输出循环链表s中的元素:" <<endl;
s.prt_linked_CList();
s.ins_linked_CList(10,10); //在包含元素10的结点前插入新元素10
s.ins_linked_CList(10,20); //在包含元素10的结点前插入新元素20
s.ins_linked_CList(10,30); //在包含元素10的结点前插入新元素30
s.ins_linked_CList(40,40); //在包含元素40的结点前插入新元素40
cout <<"第2次扫描输出循环链表s中的元素:" <<endl;
s.prt_linked_CList();
if (s.del_linked_CList(30))
cout <<"删除元素:30" <<endl;
else
cout <<"循环链表中无元素:30" <<endl;
if (s.del_linked_CList(50))
cout <<"删除元素:50" <<endl;
else
cout <<"循环链表中无元素:50" <<endl;
cout <<"第3次扫描输出循环链表s中的元素:" <<endl;
s.prt_linked_CList();
return 0;
}
2.双向链表(了解)
与单链表相比,双向链表只是多了一个前驱结点,如下所示。
双向链表的尾指针指向head指针后,就构成了
双循环链表。与第一节的单循环链表类似,双循环链表在实现时多考虑前驱指针即可,故不赘述。
总结:线性表上界主要比较的是时间性能与空间性能。在对整体线性表进行简要介绍之后,可以引出另外一个比较概念,即
存储密度。结点的存储密度越高,存储的效率就越高。顺序表只存储元素,因此存储密度是1,而链表还需存储它的后继指针(双向链表还要考虑前驱指针)。存储数据的效率只有1/2甚至1/3.并且在C++中还有矢量数组的概念,其长度不是固定不变的,这也大大提高了顺序存储结构的灵活性。














 722
722











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









