







刚学了下多线程的下载,可能是初次接触的原因吧,理解起来觉得稍微有点难。所以想写一篇博客来记录下,加深自己理解的同时,也希望能够帮到一些刚接触的小伙伴。由于涉及到网络的传输,那么就会涉及到http协议。建议在读本文之前您对http协议有一定的了解。
线程可以通俗的理解为下载的通道,一个线程就是文件下载的一个通道,多线程就是同时打开了多个通道对文件进行下载。当服务器提供下载服务时,用户之间共享带宽,在优先级相同的情况下,总服务器会对总下载线程进行平均分配。我们平时用的迅雷下载就是多线程下载。
多线程的下载大致可以分为如下几个步骤:
1: 获取目标文件的大小(totalSize)
按照常识,我们在下载一个文件之前,通常情况下是要知道该文件的大小,这样才好在本地留好足量的空间来存储,免得出现还未下载完,存储空间就爆了的情况。为了方便代码的演示,本文在本地tomcat服务器的webapps/ROOT目录下新建一个test.txt的文件,里面存储了0123456789这10字节的数据。
2: 确定要开启几个线程(threadCount)
需要的文件在服务器上,那我们要开通几个通道去下载呢?一般情况下这是由CPU去决定的,但是CPU开启线程的数目也是有限的,不是想开几个线程就开几个线程。所开线程的最大数量=(CPU核数+1),例如你的CPU核数为4,那么电脑最多可以开启5条线程。为了方便代码演示,本文的threadCount=3
3: 计算平均每个线程需要下载多少个字节的数据(blockSize)
理想情况下多线程下载是按照平均分配原则的,即:单线程下载的字节数等于文件总大小除以开启的线程总条数,当不能整除时,则最后开启的线程将剩余的字节一起下载。例如:本文中的totalSize=10,threadCount=3,则前两个开启的线程下载3KB的数据,第三个开启的线程需要下载(3+1)KB的数据。
4:计算各个线程要下载的字节范围。
平时我们做项目讲究分工明确,同理多线程下载也需要明确各个下载的字节范围,这样才能将文件高效、快速、准确的下载下来。即在下载过程中,各个线程都要明确自己的开始索引(startIndex)和结束索引(endIndex)。
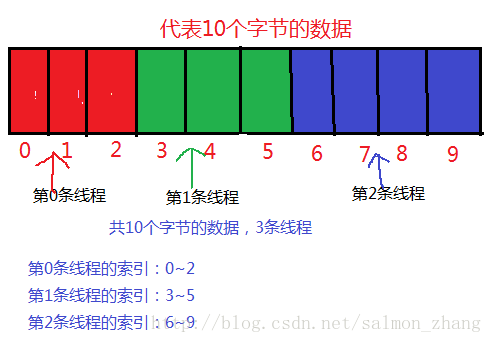
从上图我们可以总结出一个公式:
startIndex = threadId乘以blockSize;
endIndex = (threadId+1)乘以blockSize-1;
如果是最后一条线程,那么结束索引为:
endIndex = totalSize - 1;
5: 使用for循环开启3个子线程
//每次循环启动一条线程下载
for(int threadId=0; threadId<3;threadId++){
/**
* 计算各个线程要下载的字节范围
*/
//开始索引
int startIndex = threadId * blockSize;
//结束索引
int endIndex = (threadId+1)* blockSize-1;
//如果是最后一条线程(因为最后一条线程可能会长一点)
if(threadId == (threadCount -1)){
endIndex = totalSize -1;
}
/**
* 启动子线程下载
*/
new DownloadThread(threadId,startIndex,endIndex).start();
}
6:获取各个线程的目标文件的开始索引和结束索引的范围。
告诉服务器,只要目标段的数据,这样就需要通过Http协议的请求头去设置(range:bytes=0-499 )
connection.setRequestProperty("range", "bytes="+startIndex+"-"+endIndex);
7:使用RandomAccessFile随机文件访问类。创建一个RandomAccessFile对象,将返回的字节流写到文件指定的范围
此处有个注意事项:让RandomAccessFile对象写字节流之前,需要移动RandomAccessFile对象到指定的位置开始写。
raf.seek(startIndex);
以上就是多线程下载的大致步骤。代码如下:
package com.example;
import java.io.InputStream;
import java.io.RandomAccessFile;
import java.net.HttpURLConnection;
import java.net.URL;
public class DownloadTest {
private static final String path = "http://localhost:8080/test.txt";
public static void main(String[] args) throws Exception {
/**
* 1.获取目标文件的大小
*/
int totalSize = new URL(path).openConnection().getContentLength();
System.out.println("目标文件的总大小为:"+totalSize+"B");
/**
*2. 确定开启几个线程
*开启线程的总数=CPU核数+1;例如:CPU核数为4,则最多可开启5条线程
*/
int availableProcessors = Runtime.getRuntime().availableProcessors();
System.out.println("CPU核数是:"+availableProcessors);
int threadCount = 3;
/**
* 3. 计算每个线程要下载多少个字节
*/
int blockSize = totalSize/threadCount;
//每次循环启动一条线程下载
for(int threadId=0; threadId<3;threadId++){
/**
* 4.计算各个线程要下载的字节范围
*/
//开始索引
int startIndex = threadId * blockSize;
//结束索引
int endIndex = (threadId+1)* blockSize-1;
//如果是最后一条线程(因为最后一条线程可能会长一点)
if(threadId == (threadCount -1)){
endIndex = totalSize -1;
}
/**
* 5.启动子线程下载
*/
new DownloadThread(threadId,startIndex,endIndex).start();
}
}
//下载的线程类
private static class DownloadThread extends Thread{
private int threadId;
private int startIndex;
private int endIndex;
public DownloadThread(int threadId, int startIndex, int endIndex) {
super();
this.threadId = threadId;
this.startIndex = startIndex;
this.endIndex = endIndex;
}
@Override
public void run(){
System.out.println("第"+threadId+"条线程,下载索引:"+startIndex+"~"+endIndex);
//每条线程要去找服务器拿取目标段的数据
try {
//创建一个URL对象
URL url = new URL(path);
//开启网络连接
HttpURLConnection connection = (HttpURLConnection)url.openConnection();
//添加配置
connection.setConnectTimeout(5000);
/**
* 6.获取目标文件的[startIndex,endIndex]范围
*/
//告诉服务器,只要目标段的数据,这样就需要通过Http协议的请求头去设置(range:bytes=0-499 )
connection.setRequestProperty("range", "bytes="+startIndex+"-"+endIndex);
connection.connect();
//获取响应码,注意,由于服务器返回的是文件的一部分,因此响应码不是200,而是206
int responseCode = connection.getResponseCode();
//判断响应码的值是否为206
if (responseCode == 206) {
//拿到目标段的数据
InputStream is = connection.getInputStream();
/**
* 7:创建一个RandomAccessFile对象,将返回的字节流写到文件指定的范围
*/
//获取文件的信息
String fileName = getFileName(path);
//rw:表示创建的文件即可读也可写。
RandomAccessFile raf = new RandomAccessFile("d:/"+fileName, "rw");
/**
* 注意:让raf写字节流之前,需要移动raf到指定的位置开始写
*/
raf.seek(startIndex);
//将字节流数据写到file文件中
byte[] buffer = new byte[1024];
int len = 0;
while((len=is.read(buffer))!=-1){
raf.write(buffer, 0, len);
}
//关闭资源
is.close();
raf.close();
System.out.println("第 "+ threadId +"条线程下载完成 !");
} else {
System.out.println("下载失败,响应码是:"+responseCode);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
//获取文件的名称
private static String getFileName(String path){
//http://localhost:8080/test.txt
int index = path.lastIndexOf("/");
String fileName = path.substring(index+1);
return fileName ;
}
}
示例代码运行结果如下:

好了,本文写到此为止。以上是我个人对多线程下载的初步理解,如有不妥之处,还望大家多多指点,感谢!让我们共同学习,一起进步。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









