







前言
数据结构的教材中关于排序算法有五种:插入排序,快速排序,堆排序(选择排序),归并排序,基数排序。
根据目前的见闻,用到的最多的就是快速排序和堆排序(选择排序),MonetDB(一个开源的列式数据库,自称是世界上第一个提出列式存储)中用的就是快速排序和堆排序,linux内核中用的也是堆排序,听别人说:“快速排序和堆排序的时间复杂度都是n*lgn,快速排序会比堆排序快点,但是快速排序没有堆排序稳定(这个我没验证)”。堆排序已经在另一篇文章中记录过,也在OJ系列的文章中实现过,本篇blog主要写写快速排序。另外“结构之法,算法之道”写的关于快速排序的三篇文章挺不错,建议初学者仔细看看,文章链接如下:
http://blog.csdn.net/v_july_v/article/details/6116297
正文
“非常知名”的排序算法:冒泡排序就不介绍了,快速排序就是对冒泡排序的改进。
第一个问题:快速排序算法的思想是什么?
他的基本思想是经过一次扫描将待排序的记录分为两部分,其中一部记录的关键字均比另一部分记录的关键字大,分别对此两部分重复上述操作,直至所有部分只剩下一个或是零个元素,则排序完成。
明白了快速排序的思想后,自己动手将其实现下,代码如下:
///quick sort
int Partition(int *input,int low, int high)
{
int pivot=low;
int temp=0;
while(low < high)
{
while((low<=high) && (input[pivot]<=input[high]))
{
high--;
}
if(low <= high)
{
temp=input[pivot];
input[pivot]=input[high];
input[high]=temp;
pivot=high;
low++;
high--;
}
while((low<=high) && (input[pivot] > input[low]))
{
low++;
}
if(low <= high)
{
temp=input[pivot];
input[pivot]=input[low];
input[low]=temp;
pivot=low;
low++;
}
}
return pivot;
}
void QuickSort(int *input,int low, int high)
{
if(low < high)
{
int pivot=0;
pivot=Partition(input,low,high);
QuickSort(input,low,pivot-1);
QuickSort(input,pivot+1,high);
}
}
写完代码后会知道实现排序功能由两部分组成:Partition和QuickSort。而QuickSort()函数的核心是递归的终结条件,Partition的核心为:“一次扫描将待排序的记录分为两部分,其中一部记录的关键字均比另一部分记录的关键字大”。
代码中,选择第一个元素为标准将待排序的内容分为两部分,也可以选择最后一个元素为标准,当然也可以以随机数的方式选择某一个元素为标准。选择方法很多,都是为了达到一个目标即每次选的元素都能平均的分割本组元素!如果数据是随机分布的话,以上三种选择方法其实都是一样的。我觉的没有办法控制找到最优或是次优的分割元素,只能看运气了,有待确认。(以上代码我简单测试下是正确的,但不确保正确,如果那位发现bug,请多多指教)
代码中每发生一次元素交换位置就需要辅助的一个temp来交换,其实这种方式很繁琐。看了数据结构的教材后发现起初的实现他也是这么做的,看来是个大众的直观方法啊,接下来的改进代码如下:
///版本2,使用一个temp将标准元素记录下来,然后需要交换位置时直接将其覆盖。
int Partition(int *input,int low, int high)
{
int pivot=0;
int temp=input[low];
while(low < high)///如果相等时就只有一个元素,无需partition.
{
while((low<high) && (temp<=input[high]))
{
high--;
}
if(low < high)
{
input[low]=input[high];
low++;
}
else if(low==high)
{
input[low]=temp;
pivot=low;
break;
}
while((low < high) && (temp > input[low]))
{
low++;
}
if(low < high)
{
input[high]=input[low];
high--;
}
else if(low==high)
{
input[high]=temp;
pivot=high;
break;
}
}
return pivot;
}
快速排序算法的基本特性如下:
时间复杂度:O(n*lgn)。目前还不能自如的运用,先记下吧。
最坏:O(n^2),即每次选择比较元素时都是选中了最大或是最小的,真够不幸的!
空间复杂度:lg(n),这个空间的开销指的是QuickSort()函数中pivot变量在递归中的定义次数。
稳定性:不稳定。这个应该就是比较元素的选定导致的,不确定。
反思总结:
1.临界条件,即low<high还是low<=high。第一种思路在思考临界条件时比较困难,第二种方法就清晰很多。
2.第二种交换元素的方式比第一种在代码上复杂度更低,思路也更易理解(其实还是临界条件导致)。
以下内容引用自:http://blog.csdn.net/v_july_v/article/details/6116297
这个博主的名字叫:“结构之法,算法之道”,写了很多好文章,推荐!!!
五:快速排序的最坏情况和最快情况。
最坏情况发生在划分过程产生的俩个区域分别包含n-1个元素和一个0元素的时候,
即假设算法每一次递归调用过程中都出现了,这种划分不对称。那么划分的代价为O(n),
因为对一个大小为0的数组递归调用后,返回T(0)=O(1)。
估算法的运行时间可以递归的表示为:
T(n)=T(n-1)+T(0)+O(n)=T(n-1)+O(n).
可以证明为T(n)=O(n^2)。
因此,如果在算法的每一层递归上,划分都是最大程度不对称的,那么算法的运行时间就是O(n^2)。
亦即,快速排序算法的最坏情况并不比插入排序的更好。
此外,当数组完全排好序之后,快速排序的运行时间为O(n^2)。
而在同样情况下,插入排序的运行时间为O(n)。
//注,请注意理解这句话。我们说一个排序的时间复杂度,是仅仅针对一个元素的。
//意思是,把一个元素进行插入排序,即把它插入到有序的序列里,花的时间为n。
再来证明,最快情况下,即PARTITION可能做的最平衡的划分中,得到的每个子问题都不能大于n/2.
因为其中一个子问题的大小为|_n/2_|。另一个子问题的大小为|-n/2-|-1.
在这种情况下,快速排序的速度要快得多。为,
T(n)<=2T(n/2)+O(n).可以证得,T(n)=O(nlgn)。
直观上,看,快速排序就是一颗递归数,其中,PARTITION总是产生9:1的划分,
总的运行时间为O(nlgn)。各结点中示出了子问题的规模。每一层的代价在右边显示。
每一层包含一个常数c。
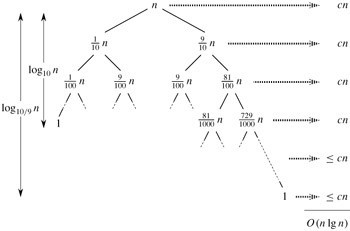
ok,相信,您已经看到,上述所有的快速排序算法,都是递归版本的,那还有什么办法可以实现此快速排序算法列?对了,递归,与之相对的,就是非递归了。
以下,就是快速排序算法的非递归实现:
template <class T>
int RandPartition(T data[],int lo,int hi)
{
T v=data[lo];
while(lo<hi)
{
while(lo<hi && data[hi]>=v)
hi--;
data[lo]=data[hi];
while(lo<hi && data[lo]<=v)
lo++;
data[hi]=data[lo];
}
data[lo]=v;
return lo;
}
//快速排序的非递归算法
template <class T>
void QuickSort(T data[],int lo,int hi)
{
stack<int> st;
int key;
do{
while(lo<hi)
{
key=partition(data,lo,hi);
//递归的本质是什么?对了,就是借助栈,进栈,出栈来实现的。
if( (key-lo)<(key-hi) )
{
st.push(key+1);
st.push(hi);
hi=key-1;
}
else
{
st.push(lo);
st.push(key-1);
lo=key+1;
}
}
if(st.empty())
return;
hi=st.top();
st.pop();
lo=st.top();
st.pop();
}while(1);
}
void QuickSort(int data[], int lo, int hi)
{
if (lo<hi)
{
int k = RandPartition(data, lo, hi);
QuickSort(data, lo, k-1);
QuickSort(data, k+1, hi);
}
}
如果你还尚不知道快速排序算法的原理与算法思想,请参考本人写的关于快速排序算法的前俩篇文章:一之续、快速排序算法的深入分析,及一、快速排序算法。如果您看完了此篇文章后,还是不知如何从头实现快速排序算法,那么好吧,伸出手指,数数,1,2,3,4,5....数到100之后,再来看此文。
-------------------------------------------------------------
据本文评论里头网友ybt631的建议,表示非常感谢,并补充阐述下所谓的并行快速排序:
Intel Threading Building Blocks(简称TBB)是一个C++的并行编程模板库,它能使你的程序充分利用多核CPU的性能优势,方便使用,效率很高。
以下是,parallel_sort.h头文件中的关键代码:
- 00039 template<typename RandomAccessIterator, typename Compare>
- 00040 class quick_sort_range: private no_assign {
- 00041
- 00042 inline size_t median_of_three(const RandomAccessIterator &array, size_t l, size_t m, size_t r) const {
- 00043 return comp(array[l], array[m]) ? ( comp(array[m], array[r]) ? m : ( comp( array[l], array[r]) ? r : l ) )
- 00044 : ( comp(array[r], array[m]) ? m : ( comp( array[r], array[l] ) ? r : l ) );
- 00045 }
- 00046
- 00047 inline size_t pseudo_median_of_nine( const RandomAccessIterator &array, const quick_sort_range &range ) const {
- 00048 size_t offset = range.size/8u;
- 00049 return median_of_three(array,
- 00050 median_of_three(array, 0, offset, offset*2),
- 00051 median_of_three(array, offset*3, offset*4, offset*5),
- 00052 median_of_three(array, offset*6, offset*7, range.size - 1) );
- 00053
- 00054 }
- 00055
- 00056 public:
- 00057
- 00058 static const size_t grainsize = 500;
- 00059 const Compare ∁
- 00060 RandomAccessIterator begin;
- 00061 size_t size;
- 00062
- 00063 quick_sort_range( RandomAccessIterator begin_, size_t size_, const Compare &comp_ ) :
- 00064 comp(comp_), begin(begin_), size(size_) {}
- 00065
- 00066 bool empty() const {return size==0;}
- 00067 bool is_divisible() const {return size>=grainsize;}
- 00068
- 00069 quick_sort_range( quick_sort_range& range, split ) : comp(range.comp) {
- 00070 RandomAccessIterator array = range.begin;
- 00071 RandomAccessIterator key0 = range.begin;
- 00072 size_t m = pseudo_median_of_nine(array, range);
- 00073 if (m) std::swap ( array[0], array[m] );
- 00074
- 00075 size_t i=0;
- 00076 size_t j=range.size;
- 00077 // Partition interval [i+1,j-1] with key *key0.
- 00078 for(;;) {
- 00079 __TBB_ASSERT( i<j, NULL );
- 00080 // Loop must terminate since array[l]==*key0.
- 00081 do {
- 00082 --j;
- 00083 __TBB_ASSERT( i<=j, "bad ordering relation?" );
- 00084 } while( comp( *key0, array[j] ));
- 00085 do {
- 00086 __TBB_ASSERT( i<=j, NULL );
- 00087 if( i==j ) goto partition;
- 00088 ++i;
- 00089 } while( comp( array[i],*key0 ));
- 00090 if( i==j ) goto partition;
- 00091 std::swap( array[i], array[j] );
- 00092 }
- 00093 partition:
- 00094 // Put the partition key were it belongs
- 00095 std::swap( array[j], *key0 );
- 00096 // array[l..j) is less or equal to key.
- 00097 // array(j..r) is greater or equal to key.
- 00098 // array[j] is equal to key
- 00099 i=j+1;
- 00100 begin = array+i;
- 00101 size = range.size-i;
- 00102 range.size = j;
- 00103 }
- 00104 };
- 00105
- ....
- 00218 #endif
再贴一下插入排序、快速排序之其中的俩种版本、及插入排序与快速排序结合运用的实现代码,如下:
- /// 插入排序,最坏情况下为O(n^2)
- template< typename InPos, typename ValueType >
- void _isort( InPos posBegin_, InPos posEnd_, ValueType* )
- {
- /****************************************************************************
- * 伪代码如下:
- * for i = [1, n)
- * t = x
- * for( j = i; j > 0 && x[j-1] > t; j-- )
- * x[j] = x[j-1]
- * x[j] = x[j-1]
- ****************************************************************************/
- if( posBegin_ == posEnd_ )
- {
- return;
- }
- /// 循环迭代,将每个元素插入到合适的位置
- for( InPos pos = posBegin_; pos != posEnd_; ++pos )
- {
- ValueType Val = *pos;
- InPos posPrev = pos;
- InPos pos2 = pos;
- /// 当元素比前一个元素大时,交换
- for( ;pos2 != posBegin_ && *(--posPrev) > Val ; --pos2 )
- {
- *pos2 = *posPrev;
- }
- *pos2 = Val;
- }
- }
- /// 快速排序1,平均情况下需要O(nlogn)的时间
- template< typename InPos >
- inline void qsort1( InPos posBegin_, InPos posEnd_ )
- {
- /****************************************************************************
- * 伪代码如下:
- * void qsort(l, n)
- * if(l >= u)
- * return;
- * m = l
- * for i = [l+1, u]
- * if( x < x[l]
- * swap(++m, i)
- * swap(l, m)
- * qsort(l, m-1)
- * qsort(m+1, u)
- ****************************************************************************/
- if( posBegin_ == posEnd_ )
- {
- return;
- }
- /// 将比第一个元素小的元素移至前半部
- InPos pos = posBegin_;
- InPos posLess = posBegin_;
- for( ++pos; pos != posEnd_; ++pos )
- {
- if( *pos < *posBegin_ )
- {
- swap( *pos, *(++posLess) );
- }
- }
- /// 把第一个元素插到两快元素中央
- swap( *posBegin_, *(posLess) );
- /// 对前半部、后半部执行快速排序
- qsort1(posBegin_, posLess);
- qsort1(++posLess, posEnd_);
- };
- /// 快速排序2,原理与1基本相同,通过两端同时迭代加快平均速度
- template<typename InPos>
- void qsort2( InPos posBegin_, InPos posEnd_ )
- {
- if( distance(posBegin_, posEnd_) <= 0 )
- {
- return;
- }
- InPos posL = posBegin_;
- InPos posR = posEnd_;
- while( true )
- {
- /// 找到不小于第一个元素的数
- do
- {
- ++posL;
- }while( *posL < *posBegin_ && posL != posEnd_ );
- /// 找到不大于第一个元素的数
- do
- {
- --posR;
- } while ( *posR > *posBegin_ );
- /// 两个区域交叉时跳出循环
- if( distance(posL, posR) <= 0 )
- {
- break;
- }
- /// 交换找到的元素
- swap(*posL, *posR);
- }
- /// 将第一个元素换到合适的位置
- swap(*posBegin_, *posR);
- /// 对前半部、后半部执行快速排序2
- qsort2(posBegin_, posR);
- qsort2(++posR, posEnd_);
- }
- /// 当元素个数小与g_iSortMax时使用插入排序,g_iSortMax是根据STL库选取的
- const int g_iSortMax = 32;
- /// 该排序算法是快速排序与插入排序的结合
- template<typename InPos>
- void qsort3( InPos posBegin_, InPos posEnd_ )
- {
- if( distance(posBegin_, posEnd_) <= 0 )
- {
- return;
- }
- /// 小与g_iSortMax时使用插入排序
- if( distance(posBegin_, posEnd_) <= g_iSortMax )
- {
- return isort(posBegin_, posEnd_);
- }
- /// 大与g_iSortMax时使用快速排序
- InPos posL = posBegin_;
- InPos posR = posEnd_;
- while( true )
- {
- do
- {
- ++posL;
- }while( *posL < *posBegin_ && posL != posEnd_ );
- do
- {
- --posR;
- } while ( *posR > *posBegin_ );
- if( distance(posL, posR) <= 0 )
- {
- break;
- }
- swap(*posL, *posR);
- }
- swap(*posBegin_, *posR);
- qsort3(posBegin_, posR);
- qsort3(++posR, posEnd_);
- }














 325
325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









