







#define预处理的弊端
参考:《Effective C++》
几个弊端
1.难以调试
2.源码体积变大
3.难以控制作用域
4.无法提供封装性
5.直接替换,无法保证类型安全。
6.直接替换的严重后果
1.难以调试
我们给出一个预处理:
#define SIZE_COUNT 100当出现编译错误时,编译器提示的是100而不是SIZE_COUNT
宏定义在编译器处理之前就被预处理给替换了,所以SIZE_COUNT对于编译器来说从来都是不可见的。他不会被载入符号表。所以抛出编译错误时,我们看到的是100,而不是SIZE_COUNT
2.源码体积变大
a. #define直接替换插入到源代码当中,如此一来,我们代码的体积就变大了。
b. 还有可能出现多个副本的情况。对于代码段的重用没有函数的效率高。如下的SIZE_COUNT,可能出现多余的目标码。
#define SIZE_COUNT 100解决方案
在C++中,对于如下的常量,可以解1.难以调试2.源码体积变大的问题。
const std::size_t SizeCount 100;因为:
1.SizeCount对于编译器是可见的,会载入符号表
2.其次,SizeCount不会出现多个副本。
3.难以控制作用域
#define的作用于是从#define开始到#undef(如果没有#undef那就是本源文件末)
显然,用#define和#undef的确可以比较自在的操控他的作用于,但是如果我们只需要让它在类中可见呢?
比如:
#define LENGTH 10
class demo{
public:
int arr[LENGTH];
};显然,与其用下面的使用方法,我们不如定义一个常量
class demo{
public:
#define LENGTH 10
int arr[LENGTH];
#undef LENGTH
};使用常量(此时我们即可以保证为数组提供的是常量,又可以保证该类当中始终只有一份10(因为static为该类共享)):
class demo{
public:
static const std::size_t length=10;
int arr[length];
};此时的length如果单纯只是为了给数组提供常量的话,这样是没问题的(静态整形常量可以在类内部直接声明并给予初值)。
如果你取地址的话,有些编译器(G++报错,但是VC++不会)恐怕就要报错了(因为取地址表示有相应的内存空间,而const常量通常不分配内存,而是直接从符号表中读取的)。所以我们会采用如下的方法:
class demo{
public:
static const std::size_t length=10;
int arr[length];
};
const std::size_t demo::length;//表示为length常量分配内存空间但是千万注意:此时类外部的定义不能够在赋值。因为类内部的声明和类外部的定义将发生冲突。
但是如果写成下面这样:
class demo{
public:
static const std::size_t length;
int arr[length];
};
const std::size_t demo::length(10);同样无法编译通过,因为编译器无法为arr确定length参数。错误如下(codeblocks):

有些编译器不支持在类的内部为静态常量成员赋初值,这是我们可以使用enum:
class demo{
public:
enum{length=10};
int a[length];
private:
};从这段代码,我们可以看到enum的若干属性:
1.可以初始化数组个数,表示他是常量
2.不可以取地址, 表明它和#define非常相近
用enum的几个优点是:
1.enum有作用域
2.enum可以提供封装性(可以设置为private成员)
同时,enum 也无法用指针或是引用指向它们,可以提供特殊需求;此外,enum也是模板元编程的基础技术。
4.无法提供封装性
例如没有private #define一样。
5.直接替换,无法保证类型安全。
C++是强类型语言,有系统内建的类型、STL、用户自定义类型等各种各样的类型,一旦类型不匹配编译就会报错,而且宏不好调试。例如:
#define container_of(ptr,type,member,membertype) *((membertype*)((char*)(ptr)+(unsigned long)&((type*)0)->member))上面的宏是做什么的呢?一眼看过去一定很晕,但是留心的同学一定注意到这个宏 类似 linux内核中的list中的container_of宏。用于从结构体中抽取目标对象(当然这个被我改了),例如:
#include <iostream>
struct mystruct {
int data;
double db;
char ch;
};
#define container_of(ptr,type,member,membertype) *((membertype*)((char*)(ptr)+(unsigned long)&((type*)0)->member))
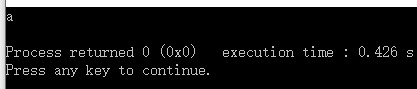
int main() {
mystruct st{ 12,12.12,'a' };
std::cout << container_of(&st, mystruct, ch,char) << std::endl;
return 0;
}
具体参看:http://www.ibm.com/developerworks/cn/linux/kernel/l-chain/
这个例子很好体现了宏直接替换的原则,显然调试这个宏不是那么简单的。而且在传入参数时,宏是不会检查类型是否匹配的。
6.直接替换的严重后果
代码如下:
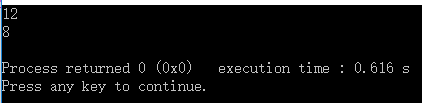
#include <iostream>
#define MUL(x,y) x*y
int main(){
std::cout<<MUL(3,4)<<std::endl;//用户期望值:12,实际值:12
std::cout<<MUL(1+3,2+1)<<std::endl;//用户期望值:12,实际值:1+3*2+1=8
return 0;
}
所以我们写#define风格的内联函数时,我们都尽量加上口号,写成:
#define MUL(x,y) (x)*(y)解决方案
用C++的inline替代宏
#include <iostream>
inline int mul(int x,int y){
return x*y;
}
int main(){
std::cout<<mul(3,4)<<std::endl;//用户期望值:12,实际值:12
std::cout<<mul(1+3,2+1)<<std::endl;//用户期望值:12,实际值:12
return 0;
}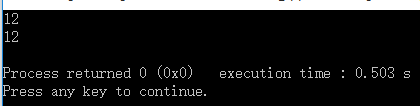
如图所示,inline函数的形式与普通函数没有区别:有参数类型、有返回值,既保证了函数的类型检查特性,有保留了内联函数调用上的高效率。
但是,inline对于编译器只是一个建议,也就是说,能不能真正的在编译时优化为内联函数最后还是由编译器决定的。我们的inline只是一个建议。
能最终成为inline函数的条件:
1.不是递归函数
2.函数内不含循环
3.不包含switch语句
4.不包含静态变量
5.没有goto语句
6.不包含数组
暂时只想到这几点














 1292
1292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









