



批量读取长文本,一直是一个很影响ABAP代码效率的问题。
问了一下ChatGPT,如何批量读取长文本,回答如下:

老掉牙的READ_TEXT,呵!不过如此嘛!
继续问,“abap如何不使用read_text函数,批量读取长文本”,ChatGPT就开始编小作文了。
毕竟,这种专业性的知识——没人喂它,它自己是不会知道的。
回归正题。
LOOP里使用函数READ_TEXT,效率实在太低了。
实在不太建议业务顾问在做方案的时候把可能在报表里会查询的字段放到长文本里去,ABAP读取起来真的是头疼死了。
如果真的有这个需求,那就用下面这个函数吧,READ_TEXT_TABLE(老版本可能没有),它是通过For All Entries In的方式去读取数据库的,避免了LOOP中的循环读取。
这个函数读取出来的长文本,需要进一步转化才能得到string类型的文本。为了方便使用,我做了个FORM如下:
*&---------------------------------------------------------------------*
*& 获取长文本
*&---------------------------------------------------------------------*
FORM get_longtext TABLES it_longtext STRUCTURE zabaps_longtext.
DATA: lt_text_headers TYPE TABLE OF thead,
lt_text_table TYPE text_lh.
SORT it_longtext BY tdobject tdname tdid.
DELETE ADJACENT DUPLICATES FROM it_longtext COMPARING tdobject tdname tdid.
lt_text_headers = CORRESPONDING #( it_longtext[] ).
MODIFY lt_text_headers FROM VALUE #( tdspras = sy-langu ) TRANSPORTING tdspras WHERE tdspras = ''.
CALL FUNCTION 'READ_TEXT_TABLE'
IMPORTING
text_table = lt_text_table
TABLES
text_headers = lt_text_headers.
CLEAR it_longtext[].
LOOP AT lt_text_table ASSIGNING FIELD-SYMBOL(<ls_text_table>).
CLEAR it_longtext.
MOVE-CORRESPONDING <ls_text_table>-header TO it_longtext.
LOOP AT <ls_text_table>-lines ASSIGNING FIELD-SYMBOL(<ls_line>).
it_longtext-longtext = it_longtext-longtext && <ls_line>-tdline.
ENDLOOP.
APPEND it_longtext.
ENDLOOP.
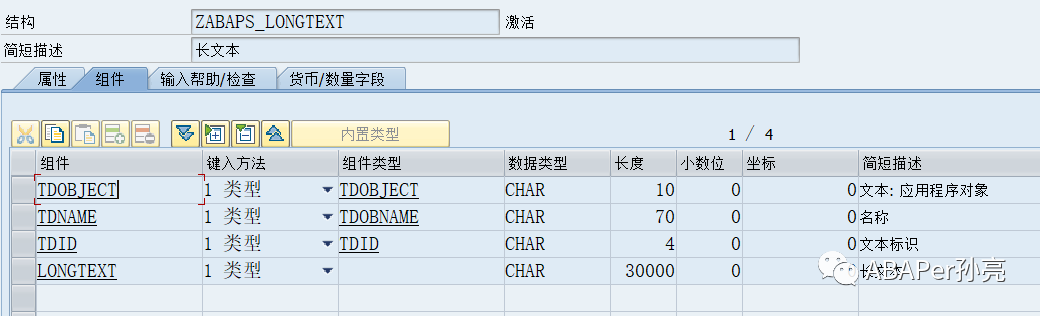
ENDFORM.zabaps_longtext的字段内容如下:
我的SE38插件工具箱——视频介绍:
https://www.bilibili.com/video/BV1hP4y1N7Qz/
联系286503700获取
ABAP文章汇总:
https://mp.weixin.qq.com/s/djmMeM0qfDxPPwxbjuJABA
Excel文章汇总:
https://mp.weixin.qq.com/s/NwJ0SzIrn9hVmaCMo-UYyA
网盘永久链接:
https://mp.weixin.qq.com/s/f_WwKZdwM-vPEstTjjz_eQ
关注公众号,点下方菜单打开上面的链接,更方便哦。
笔者微信:286503700(QQ同号)
如果喜欢,谢谢转发。


















 787
787

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









