







一、安装前准备
CentOS6.5(64bit)
hadoop-2.6.0-64.tar.gz
jdk-7u67-linux-x64.tar.gz
二、安装
1、关闭防火墙和SELinux
service iptables status (查看)
service iptables stop
chkconfig iptables off (永久关闭)
vi /etc/sysconfig/selinux
设置 SELINUX=disabled2、设置静态IP地址
vi /etc/sysconfig/network-scripts/ifcfg-eth0
3、修改HostName
hostname hadoop-yarn.dragon.org 当前生效
vi /etc/sysconfig/network 下次启动生效4、IP与HostName绑定
vi /etc/hosts
内容:IP地址 (主机名+域名) 主机名
192.168.48.128 hadoop1.dragon.org hadoop1
5、设置SSH免密码登陆
ssh-keygen -t rsa
cd /root/.ssh/
ssh-copy-id root@localhost
ssh localhost6、安装JDK
安装目录:/install/
版本:jdk-7u67-linux-x64.tar.gz
解压缩:
tar -zxvf jdk-7u67-linux-x64.tar.gz设置环境变量:
vim /etc/profile添加内容:
export JAVA_HOME=/install/jdk
export PATH=.:$JAVA_HOME/bin:$PATH使配置生效:
source /etc/profile验证:
java -version
7、安装hadoop
1)解压tar包
tar -zxvf hadoop-2.6.0-64.tar.gz
2)设置环境变量
export JAVA_HOME=/install/jdk
export HADOOP_HOME=/install/hadoop
export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$PATH使配置生效:
source /etc/profile3)配置

1、hadoop-env.sh
# The java implementation to use.
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/install/jdk2、yarn-env.sh(一般可以不添加)
# some Java parameters
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
export JAVA_HOME=/install/jdk3、mapred-env.sh(一般可以不添加)
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
export JAVA_HOME=/install/jdk4、core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop1:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/install/hadoop/data/tmp</value>
</property>
</configuration>5、hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>6、yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>7、mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>8、masters
添加:localhost
( 建议可以写成以下格式:hadoop2@192.168.10.3,即用户名@地址)
9、slaves
添加:localhost(同上)
NameNode 格式化
hdfs namenode -format(core-site.xml、hdfs-site.xml、hadoop-env.sh)
STARTUP_MSG: host = hadoop1/172.18.50.101
...
Formatting using clusterid: CID-862191a5-ead4-4cf4-b345-2d7d243bec79
15/04/26 09:52:10 INFO common.Storage: Storage directory /install/hadoop/data/tmp/dfs/name 4)启动
1、启动HDFS
NameNode、DataNode、SecondaryNameNode
–启动NameNode
hadoop-daemon.sh start namenode
验证:
方式1、jps
方式2、http://hadoop1:50070/–启动DataNode
hadoop-daemon.sh start datanode
验证:
方式1、jps
方式2、http://hadoop1:50075/–启动SecondaryNameNode
sbin/hadoop-daemon.sh start secondarynamenode
验证:
方式1、jps
方式2、http://hadoop1:50090/2、启动YARN
ResourceManager、NodeManager
启动ResourceManger
yarn-daemon.sh start resourcemanager启动NodeManager
yarn-daemon.sh start nodemanager 验证:
方式1、jps
方式2、http://hadoop1:8088/3、运行例程
1、统计单词
yarn jar /install/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount /input /output2、求PI值
yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar pi 100 1000后面2个数字参数的含义:
第1个100指的是要运行100次map任务
第2个数字指的是每个map任务,要投掷多少次
2个参数的乘积就是总的投掷次数。
扩展:
蒙特卡洛算法,我们取一个单位的正方形里面做一个内切圆(单位圆),则 单位正方形面积 : 内切单位圆面积 = 单位正方形内的飞镖数 : 内切单位圆内的飞镖数 ,通过计算飞镖个数就可以把单位圆面积算出来, 通过面积,在把圆周率计算出来。 注意 :精度和你投掷的飞镖次数成正比。
hadoop的examples中的计算PI的方法属于是采用大量采样的统计学方法,还是属于数据密集型的工作。
查看历史服务器端口号
netstat -tnlp|grep 19888
历史服务器(查看作业历史运行情况)
启动/关闭历史服务器
mr-jobhistory-daemon.sh start historyserver
mr-jobhistory-daemon.sh stop historyserverhttp://hadoop1:19888/三、启动HDFS与YARN的方式
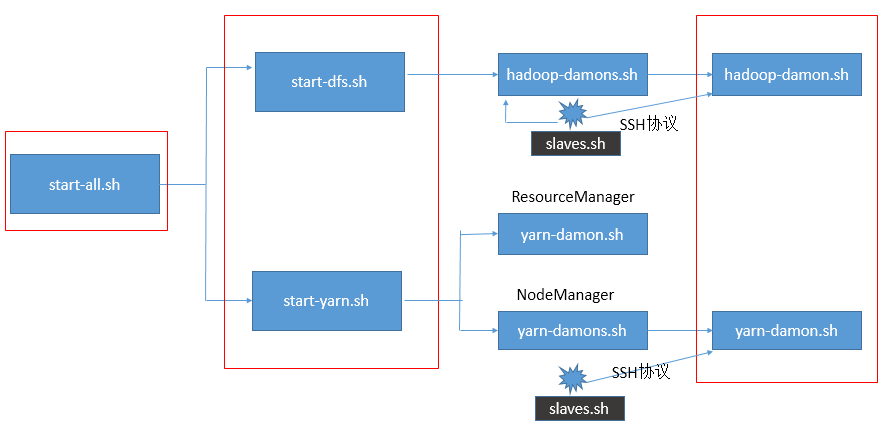
方式一:逐一启动
hadoop-daemon.sh、yarn-daemon.sh(实际项目中)
方式二:分开启动
start-dfs.sh、start-yarn.sh
方式三:一起启动
start-all.sh(不推荐,Hadoop1.x保留的)
HDFS启动时如何使用SSH协议?
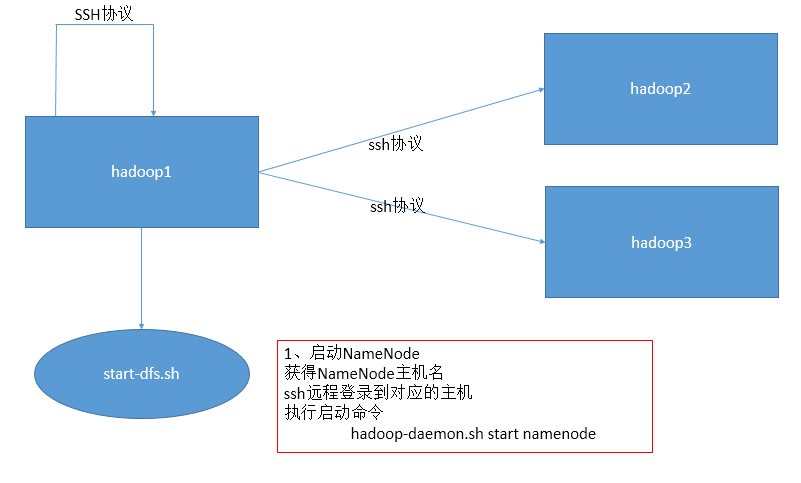
三种启动方式的关系


















 494
494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











