







最小堆是二叉树,其每个父节点的值都小于或等于其任何子节点,最小堆的特性是它的最小元素始终是树的根节点。由于堆的这种特性,堆一般会用在优先队列问题上。
python中并没有独立的堆类型,而是通过heapq模块来实现堆的一些操作。
heapd模块提供了以下几种操作:
(1)heapify(x ):
将列表x转换为堆,(对x进行操作,将x按最小堆的方式存储)
(2)heappush(heap, item):
将item压入堆中;
(3)heappop(heap):
弹出并从堆中返回最小的项;
(4)heappushpop(heap,item):
将item压入堆中,然后弹出并从堆中返回最小的项目 ;
(5)heapreplace(heap,item):
弹出并从堆中返回最小的项,然后推送新item,堆大小不变;(注意和(4)的区别)
(6)heapq.merge( iterables,key = None,reverse = False )*
将多个排序的输入合并到一个排序的输出中(例如,合并多个日志文件中带有时间戳的条目)。返回 排序后的值的迭代器。
(7)nlargest(n, iterable, key=None)
从iterable定义的数据集中返回包含n个最小元素 的列表。 key(如果提供)指定了一个参数的功能,该参数用于从iterable中的每个元素中提取一个比较键。
(8)nsmallest(n, iterable, key=None)
从iterable定义的数据集中返回包含n个最小元素 的列表。 key(如果提供)指定了一个参数的功能,该参数用于从iterable中的每个元素中提取一个比较键。
例子:
x = [2,1,3]
import heapq
heapq.heapify(x)
print(x)
print('############')
y = heapq.heappop(x)
print(y)
print(x)
print('############')
heapq.heappush(x,1)
print(x)
print('############')
y = heapq.heappushpop(x,2)
print(x)
print(y)
print('############')
y = heapq.heappushpop(x,1)
#y = heapq.heapreplace(x,1)
print(x)
print(y)
print('############')
y = heapq.heapreplace(x,1)
print(x)
print(y)
输出结果如下:
[1, 2, 3]
############
1
[2, 3]
############
[1, 3, 2]
############
[2, 3, 2]
1
############
[2, 3, 2]
1
############
[1, 3, 2]
2
x = [1,2,5]
y = [2,3,6]
z = [1,4,4]
print(list(heapq.merge(x,y,z)))
输出:
[1, 1, 2, 2, 3, 4, 4, 5, 6]
注意:
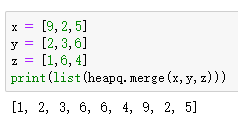
heapq.merge()参数中的x,y,z必须是排好序的,否则就会出现如上图所示的错误,且这个函数返回的并不是一个列表,需要用list()转为列表。
x = [1, 1, 2, 2, 2, 3, 4, 5, 6]
y = heapq.nlargest(3,x)
print(y)
z = heapq.nsmallest(3,x)
print(z)
print(x)
输出:
[6, 5, 4]
[1, 1, 2]
[1, 1, 2, 2, 2, 3, 4, 5, 6]
注意:
这两个函数并不会改变原来的列表x,返回的是两个新的列表。
参考:https://docs.python.org/3.6/library/heapq.html#heapq.merge














 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









