







之前,我知道可以可视化CNN,也只是知道有这么一回事情。至于它是“怎么做的、其原理是什么、给我们的指导意义是什么”,也不清楚。说白了,就是我知道有“CNN可视化”,仅仅停留在“知道”层面!但当自己需要运用、理解其他CNN可视化技术时,才晓得将这篇paper精读一下。
Background
1)在很多分类任务中(如手写字符识别、人脸识别,以及极具挑战性的Imagenet Classification),CNN取得了极好的性能。但是,CNN是怎么做到的呢?她内部的工作工作机理是什么?又该如何进一步提升其性能呢?引用论文中的一句话就是“Without clear understanding of how and why they work, the development of better models is reduced to trial-and-error”。
2)在一副图像当中,它的不同部分对于分类准确率的影响相同吗?
3)CNN的不同层,它们的泛化能力相同吗?
作者在这篇论文中提出了一种可视化的技术用以分析CNN的“Why and how they work”,并通过该技术回答了问题2),也对问题3)做了明确的回答!这个可视化技术的要点可以简单理解如下:
假设 B=f(A),可以将A理解为输入图像、B理解为feature map、f理解为CNN(为简单起见,这里认为A、B都是二维的矩阵,即输入是灰度图像、输出是只有一个channel的feature map,请注意这只是为了陈述问题方便)。一般情况是,给定输入A,我们得到feature map B。现在我们想了解一下对于B中一个元素Bij,A中的各个元素对其的“贡献”。我们可以直接令除Bij之外的所有B中元素为0,然后将Bij逆影射到输入空间,得到A‘(如果这样不好理解的话,可以认为是由Bij重构出A‘)。这个A‘就反映了A中各个像素对Bij的“贡献”,或者换句话说,Bij是被A中 “A' pattern”激活的。
Main Points
1)首先图示一下作者提出的可视化技术

Fig 1左侧是作者提出的可视化网络,用来将feature maps上的某个activation影射到输入空间,对应背景介绍中A‘。右侧对传统的CNN一个小小改进,也就是在做max pooling时进行用“Switches”记录一下最大值的位置。我们重点分析左侧的网络结构:
- 如何对pool进行“逆操作”,也就是上图中的Unpooling。其实做法很简单,在我们进行max pooling的时候,我们通过“Switches”记录下是哪个位置取得了最大值,在unpooling的时候,按照这个“Switches”将pooling后的结果放回原来的位置(剩余的直接填充0就好了)。Fig 1 Bottom很好的示意了上述过程。
- 如果我们得到了卷积核的权重,我们是可以进行反卷积的。这个卷积核的权重,我们可以直接从右侧的传统CNN得到。因此,可视化的网络是不需要训练的。
- 上图左侧之所以加上Relu,论文中是这样解释的“To obtain valid feature reconstructions at each layer (which also should be positive), we pass the reconstructed signal through a relu non-linearity”
在CNN中,每一层的feature maps有很多个channel,下面我们做的就是从中选择一个feature map,从该feature map选择一个activation,然后令除了该activation之外的所有feature map activations为0,之后,用上述选择重构出A‘。由于每一个activation在输入图像中的receptive field有限、确定,因此作者也将该activation对应的image patch裁了出来,组成了下图(作者是这样选择activation的,For a given feature map, we show the top 9 activations)

由该图可以得出结论

2)有了上述可视化的分析工具,我们可以实时追踪在训练过程中feature 的 evolution。这一部分请大家参考原始论文,我就不赘述了。
3)有了上述可视化的分析工具,我们还可以将引起最大响应的patch遮住,看看不同patch对分类结果的影响。结论就是“the model is truly identifying the location of the object in the image”。
4)有了上述可视化的分析工具,我们还可以将引起最大响应的patch遮住,看看最大响应的是不是消失了,以此验证,特定的pattern激活相应的activation。
5)当然了,我们还可以利用上述可视化分析工具,分析一下Alexnet模型的缺点,并且提出改进的办法,这篇paper也做了这样的事情。
6)此外,作者做了实验,通过移除Alexnet的一些层或者改变某一层的width,看看不同层、width对分类精度的影响,结论就是:模型的深度是影响性能一个很重要的因素,增加模型width能够提升网络的性能。
7)作者还验证了,小数据集不太适合训练大的网络如Alexnet。
8)网络的高层feature泛化能力较强,但其在PASCAL数据集上表现不佳,原因可能是:存在data-bias(Imagenet和PASCAL中的图像差异较大)
Summary
1)一个简单的可视化技术,让我们能够从各个角度审视“How and why CNN works”。“小改进、大智慧”,或许这应该成为科研的指导思想吧!
2)作者详细分析网络深度、宽度、数据集大小对网络性能的影响,也分析了网络输出特征的泛化能力以及泛化过程中出现的问题(如果另一个数据集与Imagenet差异较大,泛化能力相对较弱出现的原因)。
Matthew D. Zeiler,Rob Fergus. Visualizing and Understanding Convolutional Networks.CVPR2014.论文下载
推荐一篇比较好的blog: Visualizing Features from a Convolutional Neural Network( github-tensorFlow程序)
关于Deconvolution一直存在一个疑惑,为什么反卷积==卷积核作转置后再进行卷积,关于这个问题一直没有找到答案,发现quora的一个相关问题有点小讨论,但也没有完全解开谜底,纠结了好久这个问题,估计是个数学问题吧,直接接受吧
下面是转载的一篇关于DCNN的博客,写的非常好
原文地址:http://blog.csdn.net/hjimce/article/details/50544370
作者:hjimce
一、相关理论
本篇博文主要讲解2014年ECCV上的一篇经典文献:《Visualizing and Understanding Convolutional Networks》,可以说是CNN领域可视化理解的开山之作,这篇文献告诉我们CNN的每一层到底学习到了什么特征,然后作者通过可视化进行调整网络,提高了精度。最近两年深层的卷积神经网络,进展非常惊人,在计算机视觉方面,识别精度不断的突破,CVPR上的关于CNN的文献一大堆。然而很多学者都不明白,为什么通过某种调参、改动网络结构等,精度会提高。可能某一天,我们搞CNN某个项目任务的时候,你调整了某个参数,结果精度飙升,但如果别人问你,为什么这样调参精度会飙升呢,你所设计的CNN到底学习到了什么牛逼的特征?
这篇文献的目的,就是要通过特征可视化,告诉我们如何通过可视化的角度,查看你的精度确实提高了,你设计CNN学习到的特征确实比较牛逼。这篇文献是经典必读文献,才发表了一年多,引用次数就已经达到了好几百,学习这篇文献,对于我们今后深入理解CNN,具有非常重要的意义。总之这篇文章,牛逼哄哄。
二、利用反卷积实现特征可视化
为了解释卷积神经网络为什么work,我们就需要解释CNN的每一层学习到了什么东西。为了理解网络中间的每一层,提取到特征,paper通过反卷积的方法,进行可视化。反卷积网络可以看成是卷积网络的逆过程。反卷积网络在文献《Adaptive deconvolutional networks for mid and high level feature learning》中被提出,是用于无监督学习的。然而本文的反卷积过程并不具备学习的能力,仅仅是用于可视化一个已经训练好的卷积网络模型,没有学习训练的过程。
反卷积可视化以各层得到的特征图作为输入,进行反卷积,得到反卷积结果,用以验证显示各层提取到的特征图。举个例子:假如你想要查看Alexnet 的conv5提取到了什么东西,我们就用conv5的特征图后面接一个反卷积网络,然后通过:反池化、反激活、反卷积,这样的一个过程,把本来一张13*13大小的特征图(conv5大小为13*13),放大回去,最后得到一张与原始输入图片一样大小的图片(227*227)。
1、反池化过程
我们知道,池化是不可逆的过程,然而我们可以通过记录池化过程中,最大激活值得坐标位置。然后在反池化的时候,只把池化过程中最大激活值所在的位置坐标的值激活,其它的值置为0,当然这个过程只是一种近似,因为我们在池化的过程中,除了最大值所在的位置,其它的值也是不为0的。刚好最近几天看到文献:《Stacked What-Where Auto-encoders》,里面有个反卷积示意图画的比较好,所有就截下图,用这篇文献的示意图进行讲解:
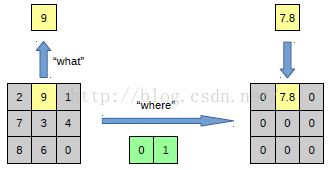
以上面的图片为例,上面的图片中左边表示pooling过程,右边表示unpooling过程。假设我们pooling块的大小是3*3,采用max pooling后,我们可以得到一个输出神经元其激活值为9,pooling是一个下采样的过程,本来是3*3大小,经过pooling后,就变成了1*1大小的图片了。而upooling刚好与pooling过程相反,它是一个上采样的过程,是pooling的一个反向运算,当我们由一个神经元要扩展到3*3个神经元的时候,我们需要借助于pooling过程中,记录下最大值所在的位置坐标(0,1),然后在unpooling过程的时候,就把(0,1)这个像素点的位置填上去,其它的神经元激活值全部为0。再来一个例子:
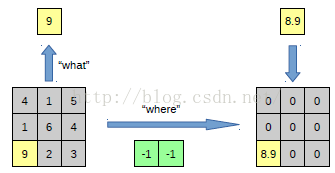
在max pooling的时候,我们不仅要得到最大值,同时还要记录下最大值得坐标(-1,-1),然后再unpooling的时候,就直接把(-1-1)这个点的值填上去,其它的激活值全部为0。
2、反激活
我们在Alexnet中,relu函数是用于保证每层输出的激活值都是正数,因此对于反向过程,我们同样需要保证每层的特征图为正值,也就是说这个反激活过程和激活过程没有什么差别,都是直接采用relu函数。
3、反卷积
对于反卷积过程,采用卷积过程转置后的滤波器(参数一样,只不过把参数矩阵水平和垂直方向翻转了一下),这一点我现在也不是很明白,估计要采用数学的相关理论进行证明。
最后可视化网络结构如下:
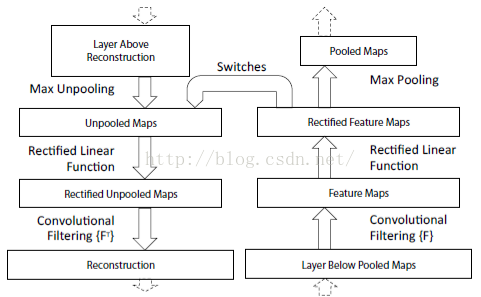
网络的整个过程,从右边开始:输入图片-》卷积-》Relu-》最大池化-》得到结果特征图-》反池化-》Relu-》反卷积。到了这边,可以说我们的算法已经学习完毕了,其它部分是文献要解释理解CNN部分,可学可不学。
总的来说算法主要有两个关键点:1、反池化 2、反卷积,这两个源码的实现方法,需要好好理解。
三、理解可视化
特征可视化:一旦我们的网络训练完毕了,我们就可以进行可视化,查看学习到了什么东西。但是要怎么看?怎么理解,又是一回事了。我们利用上面的反卷积网络,对每一层的特征图进行查看。
1、特征可视化结果:

总的来说,通过CNN学习后,我们学习到的特征,是具有辨别性的特征,比如要我们区分人脸和狗头,那么通过CNN学习后,背景部位的激活度基本很少,我们通过可视化就可以看到我们提取到的特征忽视了背景,而是把关键的信息给提取出来了。从layer 1、layer 2学习到的特征基本上是颜色、边缘等低层特征;layer 3则开始稍微变得复杂,学习到的是纹理特征,比如上面的一些网格纹理;layer 4学习到的则是比较有区别性的特征,比如狗头;layer 5学习到的则是完整的,具有辨别性关键特征。
2、特征学习的过程。

作者给我们显示了,在网络训练过程中,每一层学习到的特征是怎么变化的,上面每一整张图片是网络的某一层特征图,然后每一行有8个小图片,分别表示网络epochs次数为:1、2、5、10、20、30、40、64的特征图:
结果:(1)仔细看每一层,在迭代的过程中的变化,出现了sudden jumps;(2)从层与层之间做比较,我们可以看到,低层在训练的过程中基本没啥变化,比较容易收敛,高层的特征学习则变化很大。这解释了低层网络的从训练开始,基本上没有太大的变化,因为梯度弥散嘛。(3)从高层网络conv5的变化过程,我们可以看到,刚开始几次的迭代,基本变化不是很大,但是到了40~50的迭代的时候,变化很大,因此我们以后在训练网络的时候,不要着急看结果,看结果需要保证网络收敛。
3、图像变换。
从文献中的图片5可视化结果,我们可以看到对于一张经过缩放、平移等操作的图片来说:对网络的第一层影响比较大,到了后面几层,基本上这些变换提取到的特征没什么比较大的变化。
个人总结:我个人感觉学习这篇文献的算法,不在于可视化,而在于学习反卷积网络,如果懂得了反卷积网络,那么在以后的文献中,你会经常遇到这个算法。大部分CNN结构中,如果网络的输出是一整张图片的话,那么就需要使用到反卷积网络,比如图片语义分割、图片去模糊、可视化、图片无监督学习、图片深度估计,像这种网络的输出是一整张图片的任务,很多都有相关的文献,而且都是利用了反卷积网络,取得了牛逼哄哄的结果。所以我觉得我学习这篇文献,更大的意义在于学习反卷积网络。
参考文献:
1、《Visualizing and Understanding Convolutional Networks》
2、《Adaptive deconvolutional networks for mid and high level feature learning》
3、《Stacked What-Where Auto-encoders》














 1323
1323











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









