









--------------------------------------------------------------------------------------
[版权申明:本文系作者原创,转载请注明出处]
文章出处: http://www.cnblogs.com/sdksdk0/p/5585192.html作者: 朱培 ID:sdksdk0
-----------------------------------------------------------------------------------
今天分享的是大数据实践的zookeeper。
zookeeper内部就是一个集群,主节点是选举出来的,外部看起来就像只有一台一样,保存的是一份状态数据。 做分布式应用协调的时候,可以降低开发难度。
具有高可用性,松耦合交互方式。
关于zookeeper的配置可以查看我的文章:http://blog.csdn.net/sdksdk0/article/details/51517460,在这里不再重复讲解安装配置。
一、zookeeper的API接口
String create(String path, byte[] data, List<ACL> acl, CreateMode createMode)
Stat exists(String path, boolean watch)
void delete(String path, int version)
List<String> getChildren(String path, boolean watch)
List<String> getChildren(String path, boolean watch)
Stat setData(String path, byte[] data, int version)
byte[] getData(String path, boolean watch, Stat stat)
void addAuthInfo(String scheme, byte[] auth)
Stat setACL(String path, List<ACL> acl, int version)
List<ACL> getACL(String path, Stat stat)
zookeeper一般来说保管的数据不超过1M.主要是保存一些配置信息,主要特点是监听数据实时更新。
二、主要应用
1、集群管理:规定编号最小的为master,所以当我们对SERVERS节点做监控的时候,得到服务器列表,只要所有集群机器逻辑认为最小编号节点为master,那么master就被选出,而这个master宕机的时候,相应的znode会消失,然后新的服务器列表就被推送到客户端,然后每个节点逻辑认为最小编号节点为master,这样就做到动态master选举。2、配置的管理:在分布式应用环境中很常见,例如同一个应用系统需要多台 PC Server 运行,但是它们运行的应用系统的某些配置项是相同的,如果要修改这些相同的配置项,那么就必须同时修改每台运行这个应用系统的 PC Server,这样非常麻烦而且容易出错。 将配置信息保存在 Zookeeper 的某个目录节点中,然后将所有需要修改的应用机器监控配置信息的状态,一旦配置信息发生变化,每台应用机器就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中。
3、共享锁:在同一个进程中很容易实现,但是在跨进程或者在不同 Server 之间就不好实现了。Zookeeper 却很容易实现这个功能,实现方式也是需要获得锁的 Server 创建一个 EPHEMERAL_SEQUENTIAL 目录节点,然后调用 getChildren方法获取当前的目录节点列表中最小的目录节点是不是就是自己创建的目录节点,如果正是自己创建的,那么它就获得了这个锁,如果不是那么它就调用 exists(String path, boolean watch) 方法并监控 Zookeeper 上目录节点列表的变化,一直到自己创建的节点是列表中最小编号的目录节点,从而获得锁,释放锁很简单,只要删除前面它自己所创建的目录节点就行了。
4、队列管理:Zookeeper 可以处理两种类型的队列:当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达,这种是同步队列;队列按照 FIFO 方式进行入队和出队操作,例如实现生产者和消费者模型
三、使用eclipse连接zookeeper
在eclipse中,我们可以导入需要的包,然后对节点进行增删改查操作。 当连接的时候可以这样,这里我是采用了3台zookeeper来进行操作的。ubuntu1,2,3都分别是主机名ZooKeeper zk = null;
@Before
public void init() throws Exception{
zk = new ZooKeeper("ubuntu2:2181,ubuntu1:2181,ubuntu3:2181", 5000, new Watcher() {
//监听事件发生时的回调方法
@Override
public void process(WatchedEvent event) {
System.out.println(event.getPath());
System.out.println(event.getType());
}
});
}创建节点: 这里我是采用创建一个永久节点,在zookeeper节点中有临时节点和永久节点之分。在跟目录下创建一个eclipse节点,内容的编码格式是utf-8,Ids是指权限控制,我这里采用的是开放ACL权限控制。最后需要把流关闭。
@Test
public void testZkNode() throws Exception {
String path = zk.create("/eclipse", "指令汇科技".getBytes("utf-8"), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
System.out.println("创建了一个永久节点: " + path);
zk.close();
}然后是注册监听器,毕竟zookeeper有一个很重要的功能就是是用来监听整个服务的状态。
@Test
public void testGet() throws Exception {
//监听器的注册只能生效一次
byte[] data = zk.getData("/eclipse", true, new Stat());
System.out.println(new String(data,"utf-8"));
Thread.sleep(Long.MAX_VALUE);
}
在main方法中调用执行。
@Test
public void testSet() throws UnsupportedEncodingException, KeeperException, InterruptedException{
zk.setData("/eclipse", "谁是英雄".getBytes("utf-8"), -1);
zk.close();
}
四、动态服务器
因为我主要分享的是如何在客户端上动态的监听服务器的上线和离线,所以我们先来写一个服务器的进程。
首先我们需要把后面需要的节点信息定义一下,先去zookeeper的客户端上面运行一下,创建一个grpnode节点,以便我们的后续操作。
private ZooKeeper zk;
private String groupNode = "grpnode";
private String subNode = "sub";
// 向zookeeper注册信息
public void connectZK(String name) throws KeeperException, InterruptedException, IOException {
zk = new ZooKeeper("ubuntu2:2181,ubuntu1:2181,ubuntu3:2181", 5000, new Watcher() {
//监听事件发生时的回调方法
@Override
public void process(WatchedEvent event) {
}
});
String path = zk.create("/" + groupNode + "/" + subNode, name.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
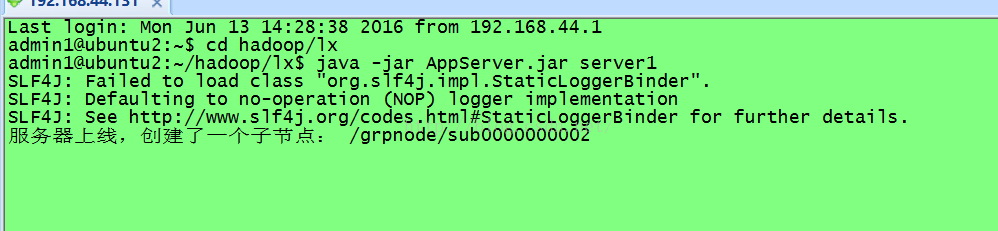
System.out.println("服务器上线,创建了一个子节点: " + path);
}接下来就是zookeeper默认的业务逻辑的处理,最后在主方法中调用。当然也可以把这个打成一个jar包放到hadoop上面去运行。
// 业务处理逻辑
public void handle() throws Exception {
Thread.sleep(Long.MAX_VALUE);
}
public static void main(String[] args) throws Exception {
if(args.length==0){
System.err.println("参数个数不对,请附加服务器名作为参数来启动.....");
System.exit(1);
}
// 去向zookeeper注册本服务器信息
AppServer server = new AppServer();
server.connectZK(args[0]);
server.handle();
}
五、动态客户端
服务器写好之后,我们就需要一个客户端来监听这个服务器的上下线操作了。同样使用一个zookeeper的监听回调方法。一旦服务器发生变化,这里就可以动态监听到。主要是监听父子节点的变化情况。private volatile List<String> servers;
private ZooKeeper zk;
//使用zk的监听器功能触发服务器更新的动作
public void connectZK() throws IOException, KeeperException, InterruptedException{
zk = new ZooKeeper("ubuntu2:2181,ubuntu1:2181,ubuntu3:2181", 5000, new Watcher() {
//监听事件发生时的回调方法
@Override
public void process(WatchedEvent event) {
if("/grpnode".equals(event.getPath()) && event.getType()==EventType.NodeChildrenChanged ){
//触发更新服务器列表的动作
try {
updateServerList();
} catch (Exception e) {
e.printStackTrace();
}
}
}
});
updateServerList();
}动态获取服务器列表,这里主要就是监听父子节点的变化。
//动态获取服务器列表
public void updateServerList() throws KeeperException, InterruptedException, UnsupportedEncodingException{
ArrayList<String> serverList=new ArrayList<String>();
//监听子节点,并且对父节点注册监听器
List<String> childer=zk.getChildren("/grpnode", true);
//遍历子节点
for(String child:childer){
byte[] data=zk.getData("/grpnode/"+child,false, new Stat());
String server=new String(data,"utf-8");
//将获取到的服务器名称存入list
serverList.add(server);
}
//把暂存的list放到全局的list中
servers=serverList;
System.out.println("最新的在线服务器是:"+serverList);
}
最后就是我们最熟悉的main方法了
//客户端的业务功能
public void handle() throws InterruptedException{
Thread.sleep(Long.MAX_VALUE);
}
public static void main(String[] args) throws IOException, InterruptedException, KeeperException{
AppClient client=new AppClient();
client.connectZK();
client.handle();
}在hadoop中运行结果如下:

总结:Zookeeper 作为 Hadoop 项目中的一个子项目,是 Hadoop 集群管理的一个必不可少的模块,它主要用来控制集群中的数据,如它管理 Hadoop 集群中的 NameNode,还有 Hbase 中 Master Election、Server 之间状态同步等。 Zoopkeeper 提供了一套很好的分布式集群管理的机制,就是它这种基于层次型的目录树的数据结构,并对树中的节点进行有效管理,从而可以设计出多种多样的分布式的数据管理模型。














 416
416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









