







tesseract是开源OCR中开发时间最长、使用最多的ocr,就不多说了。
jTessBoxEditor is a box editor and trainer for Tesseract OCR, providing editing of box data of both Tesseract 2.0x and 3.0x formats and full automation of Tesseract training. It can read images of common image formats, including multi-page TIFF. The program requires Java Runtime Environment 7 or later.
注意:
一张图片对应一个box文件,只有后缀不同,box文件后缀是.box。例如1.jpg对应的box文件是1.box。
box文件里第一行代码一个box的标注,一行有6列,最后一列暂不需要关心。第一列是框内的字符内容或者类别,中间四列分别是box的坐标,分别是x1,y1,x2,y2,但是y1和y2 是以左下顶点为原点计算的。所以如果按照我们正常使用左上顶点作为原点的话,h作为图像的高,y1’和y2’代表左上顶点为原点看的话,y1’ = h - y2, y2’ = h - y1。
打开jtessboxeditor程序看到的是x1,y1,w,h ,是以正常习惯换算得到的。
举例:
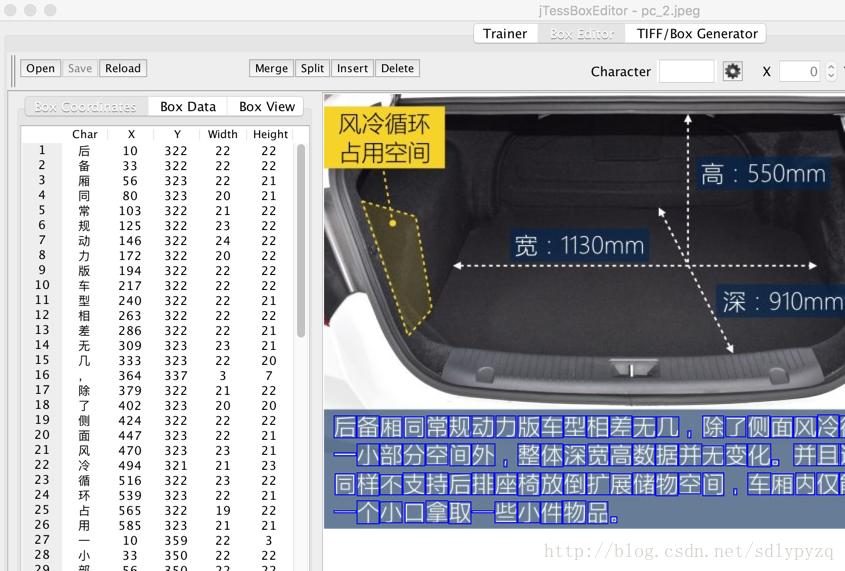
比如“后”在上图中显示 的是10,322,22,22,jtessboxeditor上显示 的是按正常习惯(即图像左上顶点为原点(0,0))展示 的。
box文件第一行是 “后 10 91 32 113 0”,即x1=10, y1=91, x2=32, y2 = 113
图像的高度是435,所以y1’ = h - y2 = 435 - 113 = 322, y2’ = h - y1 = 435 - 91 = 344















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











