







Spark GraphX中属于Structural Operators的操作主要有reverse、subgraph、mask、groupEdges等几种函数,他们在Graph中的源码分别如下所示:
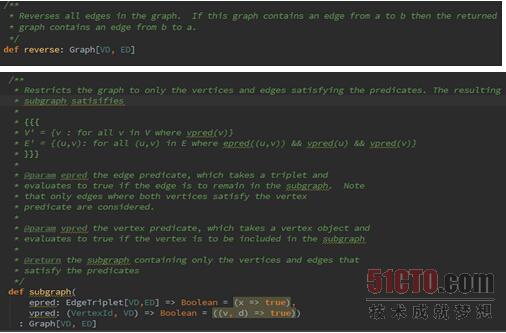
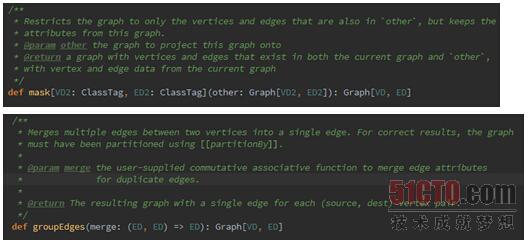
上述函数中用发比较多的是subgraph,下面我们看一下如何使用subgraph。
首先看一下基于web-Google.txt构建的graph有多少vertices:
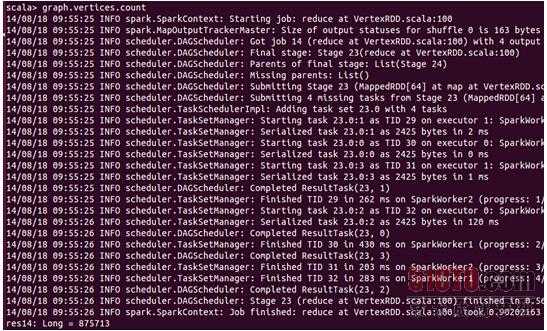
从执行结果上可以看出有875713个顶点;
看一下基于web-Google.txt构建的graph有多少edges:
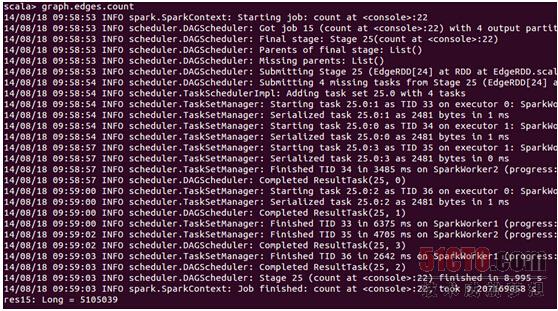
可以发现有5105039条边。
接下来使用subgraph,我们首先只考虑第一个参数,也就是说第二个参数使用默认值而不参加判断:

我们验证一下subgraph的结果:
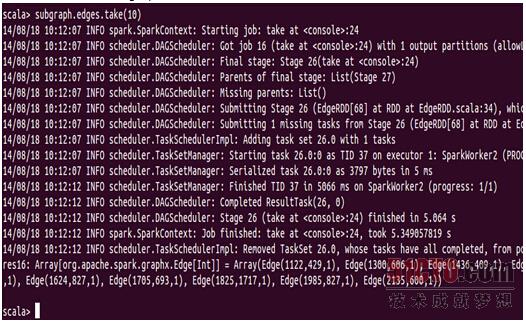
执行结果中表明源顶点的ID都是大于目标顶点的ID的。
接下来看一下我们构建的subgraph的顶点的个数:
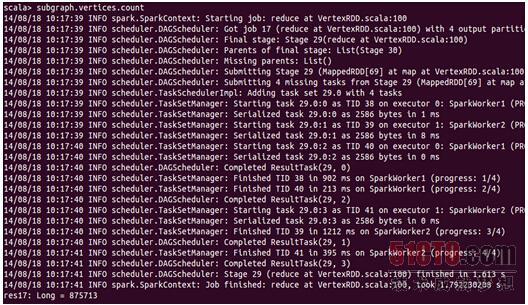
此时发现顶点个数依旧是875713个,和原图是一样的个数。
使用subgraph.edges.count看一下subgraph的边的个数:
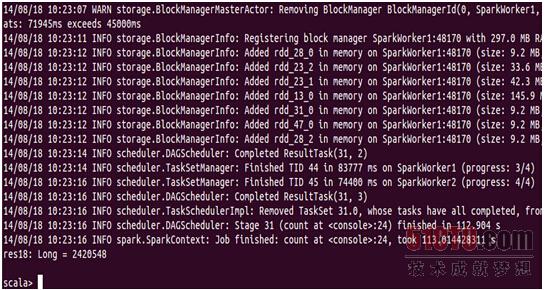
从执行结果上可以看出此时的是2420548,而原来的graph的边的个数是5105039,所以通过过滤条件下的subgraph的边减少了。
接下来我们也加入对顶点过滤的子图构建:

我们查看一下此时的顶点的个数:
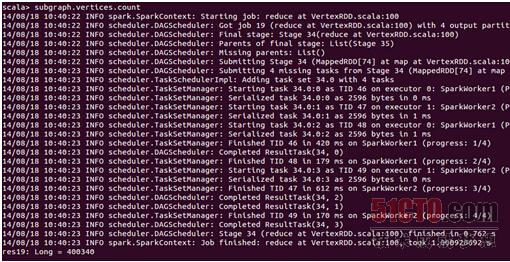
执行结构表明顶点的个数据 400340,原来的顶点个数是875713,顶点在过滤条件的作用下进行了减少。
我们看一下大于1000000的顶点个数:
![]()
此时使用subgraph.vertices.count查看一下顶点的个数:
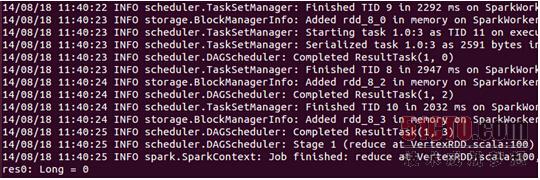
从结果上可以发现不存在顶点的ID大于1000000的情况。
本文转自http://book.51cto.com/art/201409/451614.htm,所有权力归原作者所有。














 772
772











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









