







1.概述
随着计算机硬件的制作工艺提高,如CPU单位面积可容纳的器件多了好几倍,其他硬件的也快速发展,促使单机性能远远超出满足一个应用的需求。同时,目前传统服务器的利用率大约为20%-30%,通过虚拟化技术,可以在一个物理机上同时运行多个操作系统,每一个操作系统拥有自己的内存空间,在逻辑上相互独立。
虚拟化技术与多任务以及超线程技术是完全不同的。多任务是指在一个操作系统中多个程序同时并行运行,而在虚拟化技术中,则可以同时运行多个操作系统,而且每一个操作系统中都有多个程序运行,每一个操作系统都运行在一个虚拟的CPU或者是虚拟主机上;而超线程技术只是单CPU模拟双CPU来平衡程序运行性能,这两个模拟出来的CPU是不能分离的,只能协同工作。---摘自百度百科
通过虚拟化技术,提高硬件的使用效率、简化运维管理、快速部署应用等。
1.1虚拟化技术
1.1.1 全虚拟化
不修改客户操作系统的内核,通过动态指令转化访问硬件资源。
主要是在客户操作系统和硬件之间捕捉和处理那些对虚拟化敏感的特权指令,使客户操作系统无需修改就能运行,速度会根据不同的实现而不同,但大致能满足用户的需求。这种方式是业界现今最成熟和最常见的,而且属于 Hosted 模式和 Hypervisor 模式的都有,知名的产品有IBM CP/CMS,VirtualBox,KVM,VMware Workstation和VMware ESX。
优点:Guest OS无需修改,速度和功能都非常不错,更重要的是使用非常简单,不论是 VMware 的产品,还是Sun的 VirtualBox
缺点:基于Hosted模式的全虚拟产品性能方面不是特别优异,特别是I/O方面。
1.1.2半虚拟化
与完全虚拟化有一些类似,它也利用Hypervisor来实现对底层硬件的共享访问,但是由于在Hypervisor 上面运行的Guest OS已经集成与半虚拟化有关的代码,使得Guest OS能够非常好地配合Hyperivosr来实现虚拟化。通过这种方法将无需重新编译或捕获特权指令,使其性能非常接近物理机,其最经典的产品就是Xen。
优点:这种模式和全虚拟化相比,架构更精简,而且在整体速度上有一定的优势。
缺点:需要对Guest OS进行修改,所以在用户体验方面比较麻烦
1.1.3 硬件辅助虚拟化
Intel/AMD等硬件厂商通过对部分全虚拟化和半虚拟化使用到的软件技术进行硬件化来提高性能。利用硬件(主要是CPU)辅助处理敏感指令以实现完全虚拟化的功能,客户操作系统无需修改。硬件辅助虚拟化技术常用于优化全虚拟化和半虚拟化产品,而不是独创一派,最出名的例子莫过于VMware Workstation,它虽然属于全虚拟化,但是在它的6.0版本中引入了硬件辅助虚拟化技术,比如Intel的VT-x和AMD的AMD-V。现在市面上的主流全虚拟化和半虚拟化产品都支持硬件辅助虚拟化,包括VirtualBox,KVM,VMware ESX和Xen。
优点:通过引入硬件技术,将使虚拟化技术更接近物理机的速度
缺点:现有的硬件实现不够优化,还有进一步提高的空间
1.2 XEN简介
1.2.1 XEN功能描述
Xen是一个开放源代码虚拟机监视器(VMM:virtual Machine Manager),提供多个计算机操作系统运行在同一个计算机硬件上。剑桥大学计算机实验室(University of Cambridge Computer Laboratory)开发了第一个Xen版本。从2010年开始,Xen社区开发和维护Xen作为一个完全免费的软件,GNU General Public License(GPLv2)授权。XEN兼容IA-32、x86-64,Itanium和ARM计算机架构。
在Xen系统里,Xen hypervisor是最底层和具有最高权限的软件层。通过该层支持1个或者多个Guest OS,负责调度物理CPUs。第一个随机启动的Guest OS—Domain 0(dom0),具有管理权限和直接访问硬件资源的权限。系统管理员可以登陆domain 0去管理其他Guest OS,也就是用户级domains(domU)。
Dom0是一个修改过的类linux内核,可以修改自Linux、NetBSD或者Solaris。
1.2.2 XEN发展历史
XEN Hypervisor的原型由剑桥大学在上个世纪90年代末,由Keir Fraser和Ian Pratt作为Xenoserver研究项目的一部分创造。一个关于Hypervisor的描述,至今可以再剑桥的微博服务器上看到,描述如下“forms the core of each Xenoserver node, providing the resource management, accounting and auditing that we require.”
2002
Xen Hypervisor开源,允许全球开发者使用和改进该产品
2004
Xen 2.0发布,同时Ian Pratt和其他技术人员成立XenSource公司,致力于将Xen Hypervisor从一个研究型产品转化为企业级计算应用产品。作为企业战略的一部分,Xen Hypervisor坚持开源。
2005
Xen Hypervisor被Red Hat、Novell、Sun采用,作为他们的虚拟化解决方案。同时开发者社区也在竭力加速推进Xen 3.0版本研发
2007
Citrix用5亿美元收购XenSource
2008
Xen支持ARM,Xen 3.0发布
2009
Xen官网宣布开始云计算研发项目XCP(Xen Cloud Platform)
2010
Xen 4.0发布,开始使用dom0Linux kernel,开始支持SR-IOV
2011
Xen社区发布第一版Xen Cloud Platform
2. XEN系统结构
Xen Hypervisor直接运行在硬件之上,负责CPU、内存和中断的调度。它在bootloader加载之后是第一个运行的程序。在Xen之上运行多个虚拟机,每一个运行的虚拟机实例叫做Domain(域)或者Guest。其中,有一个特殊的域Domain 0,它包含了系统中所有的驱动,同时,也包含控制栈用来管理虚拟机的创建,销亡和配置等。
Xen主要的组成要素有以下几个:
- • Xen Hypervisor
- • Domain 0
- • Domain管理和控制工具(包含在Domain 0中)
- • Domain U PV Guest OS
- • Domain U HVM Guest OS
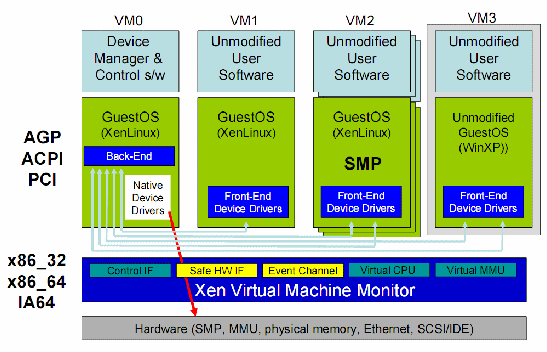
Figure 1 Xen体系结构
2.1 XEN Hypervisor
Xen Hypervisor是一个介于硬件和操作系统之间的软件层,它负责在各虚拟机之间进行CPU调度和内存分配(partitioning)。Xen Hypervisor不仅抽象出硬件层,同时控制虚拟机的执行,因为这些虚拟机共享同一个处理环境。Xen Hypervisor不会处理网络、存储设备、视频以及其他I/O。
XEN Hypervisor包括控制接口、硬件安全访问接口、事件通道、虚拟处理器、虚拟内存管理单元。
2.2 Domain 0
Domain 0是一个修改过的Linux kernel,可以修改自Linux、NetBSD或者Solaris,它是唯一运行在Xen Hypervisor之上的虚拟机,它拥有访问物理I/O资源的权限,同时和系统上运行的其他虚拟机进行交互。Domain 0需要在其它Domain启动之前启动。

Figure 2 Domain 0
Domain 0中包含两个驱动:Network Backend Driver和Block Backend Driver,分别负责处理来自Domain U的网络和本地磁盘请求。Network Backend Driver直接和本地网络硬件进行通信以处理所有来自Domain U上客户操作系统的网络请求。Block Backend Driver和本地存储设备进行通信以处理来自Domain U的读写请求
同时还包含用以对域进行管理和控制的工具和一个模拟仿真器QEMU-DM。
2.2.1 Domain管理和控制工具
通过Domain管理和控制工具,用户可以管理虚拟机的创建,销毁和配置等。同时管理工具也提供了一个接口,可以使得通过命令行终端的方式、图形界面接口对Domain进行管理操作。Domain管理和控制工具主要包括以下几个方面:
i. Xend
Xend是一个python应用程序,它是Xen虚拟化环境的系统管理工具。它通过对libxenctrl库的调用实现对Xen Hypervisor的请求。Xend处理的所有请求都是通过Xm工具提供的XML RPC接口提交的,见下图
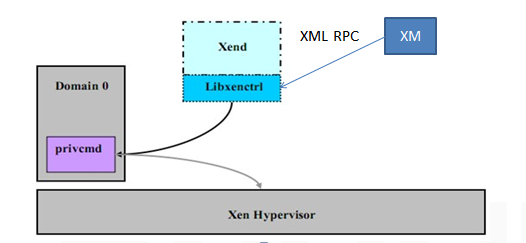
Figure 3 管理和控制工具
ii. XM
Xm是一个命令行工具,它接受用户的输入并把指令通过XML RPC传输给Xend
iii. Xenstored
Xenstored维护一个信息档案,包括内存和建立在Domain 0与Domain U之间的事件通道。Domain 0通过改变这个档案来设置和其他虚拟机的设备通道
iv. Libxenctrl
Libxenctrl是一个C语言的库,它为Xend提供与Xen Hypervisor通信的能力。privcmd是Domain 0中的一个特殊驱动,它负责提交请求到hypervisor。
v. Qemu-dm
每一个运行在Xen虚拟化环境下的HVM客户系统都有他自己的Qemu守护进程。该进程处理来自HVM客户系统的所有网络和磁盘请求,以支持Xen虚拟化 环境下的全虚拟化。Qemu必须存在于Xen hypervisor之外,因为它需要访问网络和I/O设备,所以他运行在Domain 0
vi. Xen虚拟化固件
Xen虚拟化固件是一个虚拟的BIOS,它被加载到每一个Domain U HVM Guest以提供标准的启动指令,保证客户操作系统在正常启动过程中能得到标准的PC兼容的软件环境
2.2.2 QEMU-DM
QEMU是一个以速度著称的x86模拟器,QEMU的模拟速度约为物理机器的25%,大概是Bochs的60倍。QEMU本身可以运行在多种操作系统之上。它有两种工作方式,运行模式和全系统模式。在运行模式下,QEMU可以再一个CPU上启动为另一个CPU编译的Linux进程,或用来进行跨平台编译和调试。而全系统模式则模拟一套完整的系统,包括一个CUP和几个外设。
QEMU采用动态翻译技术来产生本地代码以取得较为理想的运行速度,它的主要部分是一个快速的,可移植的指令翻译器,在运行时把加载进来的代码转换成主机上的指令集合,其基本思想是采用硬编码(hard coded)方式将每条指令转换成多条简单的微操作(micro operation),微操作用C代码片段表示,然后通过相应的工具将目标文件传给动态代码生成器,由它来把这些简单的指令串接起来完成一项功能。
2.2.3网络和磁盘后端驱动
XEN Hypervisor可以进行CPU的虚拟化,内存的虚拟化,并对vCPU和虚拟内存进行管理和控制,但目前Xen Hypervisor无法进行网络I/O和磁盘I/O的虚拟化及管理,所以通过Domain 0进行I/O的管理控制。
一个设备的驱动存在于Domain 0中,同时有一个虚拟驱动分成前端驱动和后端驱动,分别存在于虚拟机和Domain 0中。一个虚拟机的I/O访问为,虚拟机的前端驱动和Domain 0的相应后端驱动通信,后端驱动再传输数据给相应的本地设备驱动,通过本地设备驱动来对物理设备进行访问和控制。

Figure 4 前端驱动与后端驱动
前端驱动(Frontend Driver)位于Guest Domain中,负责接管Guest Domain的I/O处理恳求,传递给后端驱动(Backend Driver),并接管来自后端的处理成果返回给Guest Domain。后端驱动在Domain0中,负责接管来自前端的I/O处理恳求,并把恳求交给Domain0中的相应驱动来处理,随后把处理成果返回给Frontend。从而完成Guest Domain的I/O操纵。
因为前端和后端位于不同的OS中,它们之间的通信要依附共享内存环和事务通道来进行。共享环是由前端分派的一块共享内存,在前端和后端间共享。在ring上存在两对生产者消费者指针。经由过程共享内存环,前端和后端可以把I/O恳求放入环中和从环中读取,而I/O恳求的处理成果也可以经由过程环进行传递。事务通道则容许前端和后端发送给对方一个确认信息。
2.3 Domain U
运行在Xen Hypervisor上的所有半虚拟化(paravirtualized)虚拟机被称为“Domain U PV Guests”,其上运行着被修改过内核的操作系统,如Linux、Solaris、FreeBSD等其它UNIX操作系统。所有的全虚拟化虚拟机被称为 “Domain U HVM Guests”,其上运行着不用修改内核的操作系统,如Windows等
- • 半虚拟化Domain U PV Guests
- Domain U PV Guests的内核知道它自己不能直接访问物理硬件,因为他知道有其他虚拟机也运行在同一个环境中
- • 全虚拟化Domain U HVM Guests
- Domain U HVM Guests的内核不知道他正在和其他虚拟机共享一个处理环境,它认为它运转在物理硬件上。
2.3.1 PV Domain
Xen中的PV Domain Guest包含两个驱动,“PV Network Driver”和“PV Block Driver”,分别负责接收虚拟机中的网络请求和磁盘请求,如下图所示:
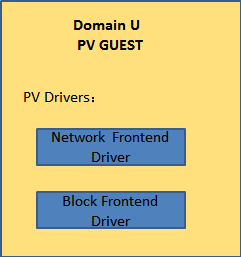
Figure 5 PV Domain
2.3.2 HVM Domain
Domain 0里为每一个HVM Guest启动一个特殊守护进程:Qemu-dm,由Qemu-dm负责客户操作系统的网络和磁盘请求。Domain U HVM Guests必须进行初始化为某类机器,所以要在Domain U上附加一个软件:Xen虚拟固件,来模拟BIOS
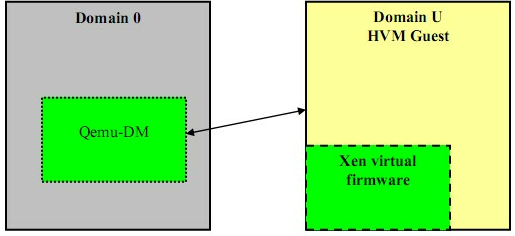
Figure 6 HVM Domain
3 CPU虚拟化
X86架构下,CPU提供4个特权级(0环—3环),操作系统位于最高特权级0环,应用程序则位于最低特权级3环。在Xen系统中,Xen位于Guest OS和硬件之间,具有比Guest OS更高的运行特权级,Guest OS被迫迁移到相对较低的特权级中。Guest OS不能直接对物理CPU进行调度,为此,XEN建立vCPU结构,为每一个Domain提供一个或者多个vCPU结构,在Domain内部,Guest OS对这些vCPU进行调度。
XEN中,vCPU分时复用物理的CPU,任意时刻一个物理CPU只能被一个vCPU使用。所以XEN必须对vCPU的合理分配时间片并维护所有vCPU的状态,保证vCPU的正确执行,并对vCPU使用物理CPU进行调度。
3.1 CPU中断和异常处理
与传统非虚拟化操作相比,Xen系统体系结构发生了变化,但Xen系统也同样需要对硬件设备进行管理,并处理这些设备产生的中断。XEN系统将中断分成物理中断和虚拟中断两个部分,一共有512个中断,前256个为物理中断,后256个为虚拟中断。
中断是指CPU对系统发生的某个事件做出的一种反应,CPU暂停正在执行的程序,保留现场后自动地转去执行相应的处理程序,处理完该事件后再返回断点继续执行被“打断”的程序。中断主要分为三类:第一类是由CPU外部引起的,称作中断,如I/O中断、时钟中断、控制台中断等。第二类是来自CPU的内部事件或程序执行中的事件引起的过程,称作异常,如CPU本身故障、程序故障等引起。第三类是由于在程序中使用了请求系统服务的系统调用而引发的过程,称作“陷入”(trap,或者陷阱),前两类通常称为中断,通常是被动的,而系统调用往往是主动的。
Xen系统中物理中断处理:
Xen系统中绝大部分硬件设备产生的中断最终都由Guest OS处理,但由于Domain不能直接访问这些硬件设备,来自设备的中断须要经过分发才能被Guest OS接收并进行处理,因而比Linux系统,Xen系统中处理中断要相对复杂,主要体现在Xen在获得外部中断后如何正确发送给相应的Guest OS,并找到正确的中断处理程序。VIDT(Virtual Interrupt Descriptor Table,虚拟中断向量表),Guest OS的异常处理过程如下:
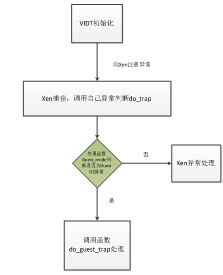
Figure 7 Guest OS的异常处理
Guest OS处理异常的过程,当应当程序申请系统调用时,直接由3环转入0环,在0环经过Xen处理后再返回1环的Guest OS,并在Guest OS内核中处理该系统调用。这个过程需要在Xen和Guest OS之间经过两次切换,增大了系统开销。为此,Xen为每个Guest OS注册一个快速异常处理程序(Fast Handlier),应用程序在使用系统调用时,可以通过该程序直接从3环进入1环,而不需要再经过0环的Xen,减少了切换次数。
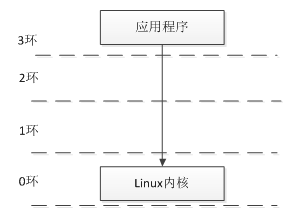
Figure 8系统调用
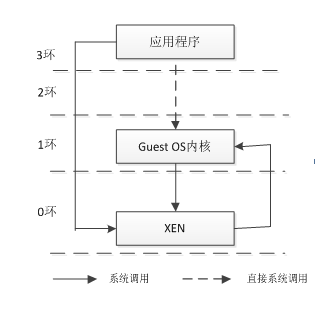
Figure 9 XEN系统调用
3.2 vCPU调度
Xen系统中,每个Domain都拥有自己的vCPU结构,Guest OS内的任务都必须要在vCPU上执行,但vCPU的执行最终要在具体的物理CPU上。通过对物理CPU周期进行时间片划分,vCPU通过获得CPU时间片权限,来使用CPU执行指令。
vCPU的调度,指由XEN决定当前由哪一个vCPU在物理CPU上执行。vCPU的调度对整个虚拟机系统的性能有很大影响。
vCPU调度的两个主要要求:
a)充分利用CPU资源
b)支持精确的CPU分配
XEN中有两种比较常用的算法:
a)BVT(Borrow Virtual Time)调度算法
BVT是一种公平性优先的调度算法,该算法将时间片分为实际时间和虚拟时间,真实时间为硬件计时器记录的时间,虚拟时间为对真实时间经过某种规则计算后得到的时间值。该算法用虚拟时间来监控进程的执行时间,每次总是调度具有最早的有效虚拟时间vCPU。
b)SEDF(Simple Earliest Deadline First)调度算法
这是一种最小时限调度算法,它为每一个vCPU制定周期p和时间片s,表示在周期p该vCPU必须运行s时间,用一个可运行的队列管理所有当前周期内还有可运行时间的vCPU,这些vCPU按照时限递增排列,用一个等待队列管理当前周期的运行时间已经用完的vCPU,这些vCPU按照下一个周期的开始时间递增排列。每次调度时,从可运行队列队头取得可以运行的vCPU。支持连续工作和断续工作模式。
c)Credit调度算法
Credit调度算法是一种按比例公平共享的非抢占式调度算法。Credit调度算法为每一个Guest操作系统设置一个二元组(weight,cap),各个Guest OS之间的Weight的比例决定他们各自占用CPU时间片的比例,而cap决定一个Guest OS用CPU时间的上限值。通过设置weight和cap参数值,管理员可以管理CPU的优先级。Weight参数用于分配CPU cycle,是一个相对值。一个weight为128的VCPU比一个weight为64的VCPU获得的CPU cycle多一倍。因此,利用这个参数可以决定哪个VCPU获得更多,哪个获得更少。第二个设置CPU的参数是cap,它设置的是domain获得的CPU cycle百分数,是一个绝对值。如果设置为100,就表示那个VCPU会100%地占用物理CPU的可用cycle。如果cap为50,则表示该VCPU占用的CPU cycle绝不会超过总量的一半。
4 内存虚拟化
Xen为自己的内核和堆分配了12MB的物理内存,并保留高端的64MB的虚拟地址工自己使用,机器地址(Machine Address,MA)和虚拟地址(Virtual Address)
4.1 内存寻址
4.2 虚拟地址分配
4.3 内存复用
A)气泡驱动(ballooning driver)
利用预装在用户虚拟机中的前端驱动程序,偷取guest os的内存贡献给VMM以供其他虚拟机使用.反向易然.
存在问题:
- • 需要实现用户虚拟机支持的前端驱动程序.
- • 不能自动偷取和归还,需要从DOM0设置.
- • 不能实现启动时的内存复用,只能启动后偷取(即启动虚拟机时宿主机必须提供其给定大小的内存)
- • 目前xen 引入了pod (Populate-on-demand) 似乎解决了在HVM虚拟机中的限制
B) 基于内容的页共享(base-content page sharable)
VMM会让虚拟机共享同样内容的也面,以达到节约内存的目的。
存在问题:
- • 操作比较重,因为要查看页面内容。
- • 目前VMM只是对前后端驱动所用的页面,因此能省出的内存数量很有限。
- • blktap2目前该技术尚不完善。
C)VMM 换出技术(OnDemand paging/swap)
VMM实现请页功能,这时guest os 类似进程一样在VMM缺少内存时能被换出到宿主机磁盘上。该方法对虚拟机透明。
存在问题:
- • 由于对虚拟机透明,所以换出的虚拟机存在不确定性。这样容易造成“double paging”,也就是guest os中某些页面已经被换出,而该guest os又被VMM换出,这样必然让guest os的性能恶化。
- • Xen的实现中hypervisor没有IO功能,因此要换出页面则需要借助dom0完成。所以操作复杂,目前尚未真正实现。(kvm中由于hypervisor在内核中实现,guest os 实现基于进程,因此onDemand paging功能省缺实现)
D) Transcient Memory
Oracle 提出的新方法,这种方法实际采用了guest os 内存分配和VMM沟通,也就是向VMM申请,使用完毕,归还VMM的思路。这种方法最彻底的解决内存复用问题。
存在问题:
- • 需要改变guest os已有的内存分配接口。也就是改造现有系统(虽然是安全的非侵入式改造)。
- • 该技术还在发展阶段,尚不成熟。
结论:
1 目前最成熟和可投入实用是气泡驱动.1 该技术已经发展多年 2 linux /windows其前端气泡驱动都有参考模型。3 ciritx server已经采用气泡 + vm反馈 + dom0上的策略引擎 实现了单机上的内存复用。
2 最理想的方式是采用 Transcient Memory 实现复用,这种方式无疑是将宿主机的整个内存池化、实现了按需分配、用完归还。避免了使用预先化区——被VM独占——带来的分配限制
5 XEN网络虚拟化
引入虚拟化之后,在一个物理服务器上运行多个虚拟机实例,多个虚拟机同时使用网络设备,物理网卡只作为上行链路,每一个虚拟机里有一个或者多个虚拟网卡,虚拟网卡和物理网卡之间通过Bridge等虚拟交换设备连接,具体如下图:
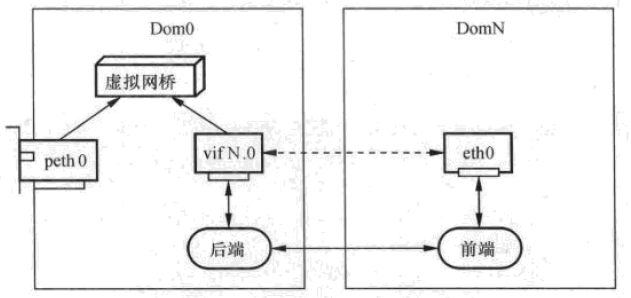
Figure 10 Xen 网络虚拟化
虚拟网络设备包括位于Dom0的后端和位于DomN的前端,同时前、后端需要通过共享内存进行通信,由于后端需要支持多个前端设备,所以后端具有网桥功能。在每一次DomN启动时,创建了前端设备eth0,此时在Dom0中为其创建相应的后端设备vif N.x,其中N是domain的ID,x是DomN的第x个网络设备,第一个网络设备就是vif N.0
传统Linux在发送数据包时,数据包从应用程序传入内核,上层的协议TCP/IP等将数据封装成sk_buff格式,传送给底层的网络设备如以太网,然后由内核调用网络设备的发包函数完成发包过程。Xen虚拟网络的实现是在Linux 2.6网络模块的基础上修改的。在DomU中,虚拟网络设备的前端与这个流程基本相同,应用程序将数据包从用户空间拷贝到内核空间,经过协议栈后封装成sk_buff,将包发送出去。只是由于前端是虚拟设备,因此不是讲报发送到物理设备,而是将包转发到后端设备,由后端真正完成包的转发。具体事项时通过把保存该数据包的内存页面授权给后端驱动域(包含对真实硬件驱动的虚拟机),后端设备驱动获取到该页面后,通过协议栈转发到本地设备驱动,从而将数据包从真实的网络设备发送出去,虚拟网络数据包的发送过程如下图:
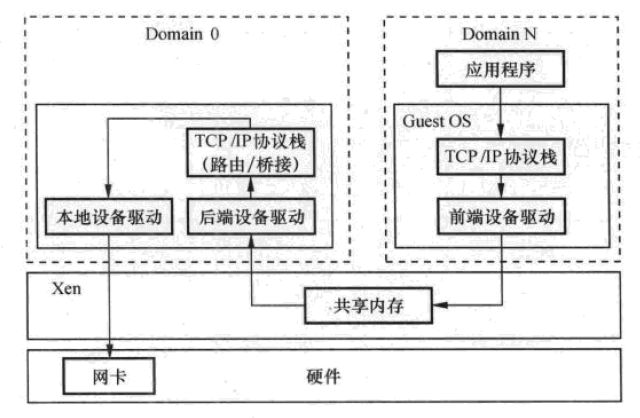
Figure 11 Xen TCP/IP网络发包
6 I/O设备虚拟化、驱动
块设备、网络设备的Xen驱动都是可分离的驱动,都在特权操作系统的一部分来处理从物理设备—》后端设备—》非特权操作系统的前端,就像后端设备的一个代理,后端驱动与前端驱动通过在这个架构中成为Xenbus的共享事件通道和缓存区进行通信。
6.1 XEN前端驱动与后端驱动
除Dom0和隔离驱动域之外,Xen的其他域DomU不拥有任何真正的物理设备,而是虚拟设备如虚拟的控制台,虚拟的块设备甚至虚拟的网络设备。Xenbus为所有的半虚拟设备驱动程序在虚拟域之间提供了一个抽象的总线,Xen虚拟设备都必须在初始化时间向Xenbus注册。Xen常规的块设备驱动程序分成前端驱动Front-enddriver和后端驱动程序Back-end driver,前端设备驱动程序在接到来自操作系统的读写请求时,通过事件通道和共享内存向后端驱动域的后端设备提出服务请求,后端设备在收到服务请求后则通过该虚拟机上的原生设备完成读写请求。典型的Xenbus上的虚拟设备包括块设备和虚拟网络接口。
6.2 设备仿真
在虚拟化中,为实现物理设备的共享,客户机的I/O访问必须被Xen捕获,有设备模型进行仿真。硬件辅助虚拟化提供对客户机I/O的捕获,但Xen监控程序本身并没有驱动程序区直接访问这些设备,在这些环境中,驱动自身无法意识到自己是虚拟的,它发出的所有指令都必须被截留和模拟。要完成这个工作,可以使用Qemu解决方案。Qemu是一个处理器模拟器,提供了多种解决方案与设备通信,如模拟磁盘设备。每一个虚拟机都可以看到一个完整的虚拟PC平台,包含键盘、鼠标、时间时钟、软盘、IDE硬盘、CDROM和VGA图形卡等。
6.3 HVM的半虚拟化驱动
全虚拟化或者硬件辅助虚拟化将物理CPU扩展到虚拟主机中,HVM需要Intel VT或AMD-V的硬件支持。Xen使用Qemu来模拟PC硬件,包括BIOS,IDE硬盘控制器,VGA图形设备,USB控制器,网络设备等。硬件设备的虚拟化用来提高模拟仿真的性能。全虚拟化的虚拟机不需要修改内核代码,这就意味着Windows操作系统可以作为Xen HVM的客户操作系统。全虚拟化通常比半虚拟化效率低,这是由于需要通过仿真来达到效果。
我们注意到Xen PV客户操作系统自动使用半虚拟化驱动,而对于全虚拟化虚拟机,可以通过安装半虚拟化驱动来提高性能。目前HVM半虚拟化驱动主要有PVHVM或者GPLPV。
PVHVM驱动安装在全虚拟化Linux客户操作系统中,通过PVHVM驱动可以绕过Qemu模拟仿真,同更快的硬盘和网络I/O访问速度。
7 XEN 虚拟机存储(虚拟机磁盘格式)
8 Domain 0与Domain U通信
8.1 事件通道
事件通道用于Dom和Xen之间、Dom和Dom之间异步事件通知机制。管道的一端连接一个域,另一端连接一个事件源,这些事件源可以是其他的域,物理中断,虚拟中断等,当连接的是两个域时,管道可以用于域间的双向通信,每个这样的管道都有一个编号,即端口,一个域可以打开的端口数位1024个
8.2 HyperCall
Hypervisor是Xen提供给客户系统的交互界面,客户系统通过hypercall存取硬件资源,根据Xen的安全模型,Xen运行在ring0层,而Guest OS运行在ring1层,App运行在ring3层,不同类型的Guest OS不同方式调用Hypercall。
与系统调用类似,Xen中的hypervisor是通过软中断(中断号0x82)实现,超级调用号中定义了45个超级调用,其中7个是平台相关的调用。
Xen基本机制中,Xenstore是域间共享,不调用hypercall;其他几种包含时间通道,granttable、内存管理等都与hypercall相关。不同的系统中定义的hypercall数量不统一,有的多有的少,目前xen支持128个hypercall定义,但其实只有37个,另有7个作为保留,一个hypercall可以试下多个功能。
hypercall与事件通道:
- • hypercall是用于各域与XEN进行同步通信的;通过中断处理系统相关的特权操作,如建立页表、管理内存、访问I/O设备等。
- • 而事件通道则是为各域之间进行异步交互设计的,是Xen用于在虚拟域之间以及虚拟域和VMM之间进行异步事件通知的机制。
- •两者关系:Xen中的物理中断(pIRQ)、虚拟中断(vIRQ)、虚拟处理器lbJ中断(vlpl)、虚拟域间通信(IDC)等均通过事件通道实现。虚拟域间通信是通过一个被称之为evtchn的驱动程序建立虚拟域间的事件通道。每个DomainU都和Domaino之间都存在一个域lbJ事件通道和一个共享内存区域,用来传递请求和数据。事件通道的端口及1/0请求信息,都存储在每个虚拟域的“共享内存页 (sharedpage)”结构体中。比如绑定PIRQ,绑定vIRQ,绑定两个域,分配端口,发送消息等等,这些操作最终都是通过调用entry.s中定义的Hypercalls来实现的。
8.3 Domain U I/O读写
a) I/O共享环:在不同Domain之间存在的一块固定的共享内存,用于在DomU和Dom0之间传递I/O请求和响应。I/O共享环利用生产者和消费者的机理来产生发送以及响应IO请求。
b) 授权表:在不同Dom之间高效传输IO数据的机制。通过授权表把内存映射到目的Dom或者把内存传送到目的Dom。
c) 事件通道:用于Dom和Xen之间、Dom和Dom之间异步事件通知机制。
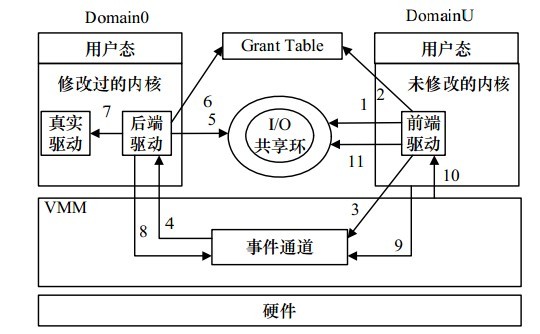
Figure 12 Domain U的IO写入示意图
以DomainU向IO设备写入数据为例:
1) DomU产生IO请求,在IO共享环中添加请求。
2) 然后将IO数据放入授权表指向的内存中,等待Dom0来取。
3) 一切准备就绪,通过事件通道通知Dom0开始处理。
4) Dom0收到事件通道的通知,知道有数据需要处理。
5) 然后,Dom0从IO共享环中取出IO请求,分析下到底DomU想要Dom0为他做什么。
6) 明白要做什么后,将授权表中的数据取出进行处理。
7) 数据处理完成后,Dom0将处理后信息放入IO共享环,然后通过事件通道发送通知给DomU,告诉他处理完成了。
8) DomU收到事件通道的通知,从IO共享环中取出相应,进而处理之。
总结:IO共享环的作用是具体的IO请求(如发送网络数据),是请求!事件通道是通知用的!授权表指向的内存是数据的存储地!
举个例子:A(DomU)请B(Dom0)帮忙保存一些贵重物品S(数据),首先A写一张纸条(IO共享环),上面说明请求B帮忙做的事情,放到B的门口,然后敲门(事件通道)。B听到敲门(事件通道的中断)后开门看到纸条(IO共享环),分析上面的内容后,去到A固有的地点(授权表上写明的内存地址)取物品S。一切做完后写个纸条(IO共享环)贴到A门口,敲门(事件通道)。
9 虚拟机迁移
如果要将一个虚拟机从一个物理机挪到另一个物理,最简单、最原始的办法就是讲虚拟机的所有文件拷贝到目标物理机,包括所有的后端存储等信息,然后再目标机器上重新创建一个Domain来加载该虚拟机,但这个过程需要将虚拟机完全关闭。如果是远程虚拟机迁移必须满足一定的基础条件:
首先,在源主机和目的主机方面,两者必须都运行有Xen和xend守护进程。必须确保目的主机具有足够的磁盘空间、内存容量和资源,以供迁移后的domain运行之用。此外,源主机和目的主机还必须具有相同的体系结构和虚拟化扩展,例如,如果源主机使用的是具有虚拟化扩展的x86-64体系结构的话,目的主机也必须如此。之所以这样做,是为了防止由于内核和用户库使用的指令集不匹配而导致domain迁移之后无法正常工作的情况。
其次,在网络方面,要求源主机和目的主机还必须位于同一子网上。迁移domain时,如果目的地结点位于不同的子网上,那么迁移将会失败,因为该domain的MAC和IP地址也随之迁移。如您运行了防火墙,你可能需要创建相应的iptables规则来准许迁入连接。
再者,迁移时,xend守护进程会中止domain在源主机上的运行,接着将其复制到目的主机,然后重新启动该domain 。默认时,xend守护进程从本机接受迁移请求。为了使迁移目标接受来自远程主机的迁入请求,您必须修改目的主机在/etc/xend-config.sxp文件中的xen-relocation-hosts-allow 参数。
9.1 Save & Restore
所有形式的迁移都基于最基础的想法,首先保存(Save)一个物理主机上的domain,然后在另一个主机上重新加载(Restore)domain,我们可以通过手动执行xm save和xm restore命令来模拟自动化迁移。
Xen中描述xm save和restore为休眠状态和恢复,当一个虚拟机进入休眠时,会把它在内存中的所有数据保存到磁盘中如vm.save,然后再关闭该虚拟机。当需要唤醒该虚拟机时,操作系统加载内存保存在磁盘中的文件vm.save,恢复到保存前的状态。
使用xm save 这个命令将domain将自己挂起,把domain的所有资源还给domain 0,取消中断号分配,以及取消内存映射关系。同时,domain 0发指令关闭domainU,然后保存该检查点。在这个过程中,确保该虚拟机的所有内存页内容都可访问。然后将内存页内容保存到硬盘中。
这个操作之后,domain会停止运行。内存的内容及入口等信息保存到一个文件中,通过这个文件可以加载信息。通过该虚拟机的虚拟磁盘文件,和刚才保存的内存文件,可以将一个虚拟机恢复到当时的状态,类似于做了一个快照。
xm restore
通过该命令,可以恢复一个domain,通过save和restore在本地物理机上进行备份和为迁移提供技术支持。
9.2冷迁移
在涉及到Xen的自动化迁移前,我们可以用手工来实现虚拟机的迁移功能,在迁移过程中,首先是save一个domain,然后通过管理员将这个save的文件拷贝到另外一个物理主机的存储上。当两台物理主机使用的是共享存储,所以不需要将虚拟机的虚拟磁盘进行复制。主要是由以下几步来完成操作:

通过以上两步来对运行中的虚拟机内存进行保存,保存为一个savefile文件,然后将该文件拷贝到另外一个物理机上。然后通过restore来恢复虚拟机。

同时在这步操作时,不需要拷贝domain的配置文件,savefile包含了所有配置信息区启动这个虚拟机。这也意味着,在save和restore这个中间,你不能够改变这个虚拟机的任何配置信息,即使改变了也没有效果,会还原到在改变之前。
9.3热迁移
冷迁移有它实际的使用地方,虽然这种方法很简单,但是如果您的服务器上有不许中断的关键业务,或者您想最小化业务中断时间,那么您还是不能采用这种迁移方法。这时,Xen还为我们提供了一种强大的功能就派上用场了,它就是动态迁移法或热迁移。它能让Domain在运行期间,以最小的服务中断为代价,将Domain迁移到另外的Xen 服务器上。
热迁移带来的好处:
- • Xen的动态迁移随同诸如heartbeat之类的高可用性解决方案一起使用,能给我们带来一个“永不抛锚”的系统。
- • 它使我们能够以“治未病”方式来维护寄放虚拟机的物理服务器。您可以监视服务器,然后通过转移系统来即时解决潜在的和可疑的问题。
- • 它使得在需要时向系统配置添加计算能力变得更加轻松。
- • 可以根据需要更换硬件,而无需中断运行在该硬件上的服务。
热迁移需要的条件:
- • 两者必须都运行有Xen和xend守护进程
- • 必须确保目的主机具有足够的磁盘空间、内存容量和资源
- • 源主机和目的主机还必须位于同一子网上
- • 源主机和目的主机还必须具有相同的体系结构和虚拟化扩展
热迁移基于基本的save和restore思想来实现,只是所在虚拟机只有在迁移拷贝最后的内存块时才需要休眠,同时该虚拟机在另外的物理机上可以快速地恢复。具体过程如下:
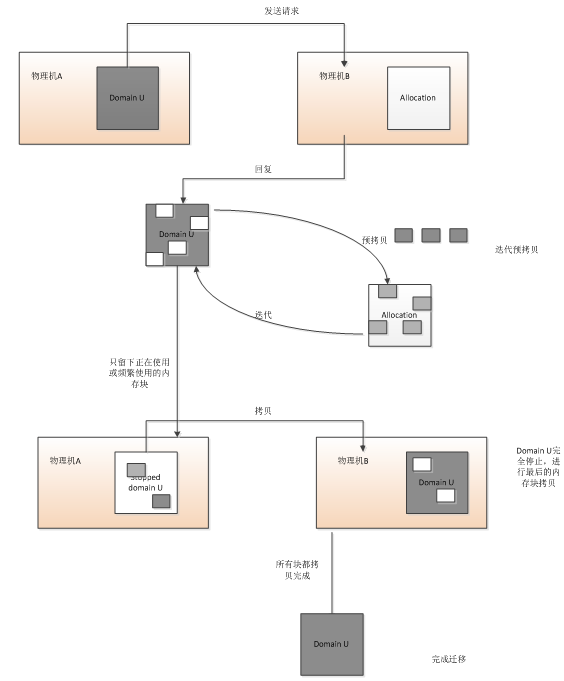
Figure 13 热迁移内存数据示意图
默认设置下,Xen一共进行29次迭代,完成内存数据拷贝。在迭代的最后,会关闭虚拟机,然后将最后的内存块进行拷贝,然后再另外的物理机上将该虚拟机启动。
10 Libvirt库简介
libvirt是一套免费、开源的支持Linux下主流虚拟化工具的C函数库,其旨在为包括Xen在内的各种虚拟化工具提供一套方便、可靠的编程接口,支持与C,C++,Ruby,Python等多种主流开发语言的绑定。当前主流Linux平台上默认的虚拟化管理工具virt-manager(图形化),virt-install(命令行模式)等均基于libvirt开发而成。
其主要目标为:为包括Xen在内的各种虚拟化工具提供一套方便、可靠的编程接口,用一种单一的方式管理多种不同的虚拟化提供方式和hypervisor(管理工具),避免学习、使用不同hypervisor的特定工具。
11 基于XEN的企业级虚拟化
11.1 Citrix XenServer
服务器半虚拟化产品Citrix的XenServer源自于开放原始码Xen。和大多数服务器半虚拟化产品相同的是,XenServer作为一种开放的、功能强大的服务器虚拟化解决方案,可将静态的、复杂的数据中心环境转变成更为动态的、更易于管理的交付中心,从而大大降低数据中心成本。
新的Citrix XenServer版本为客户提供有活力、可扩展、功能丰富的虚拟平台,不仅功能异常强大,还非常易学易用。XenServer包含以下核心功能:
-强大的集中式管理可以对无数量限制的服务器和虚拟机实现完全多节点管理。包括大量图形报告和警报、简易的物理到虚拟及虚拟到虚拟的转换工具,以及一个无单一故障点的弹性、高度可用的管理基础架构。
-动态迁移及多服务器资源共享结合强大的XenMotion™技术,使虚拟机能够在不中断服务、无停机的情况下实现服务器之间的迁移。还包括在众多物理服务器中自动平衡计算能力、优化虚拟机配置及多资源库管理。
-经过验证的管理程序引擎采用64-位行业标准Xen开放源管理程序——该程序是由超过50家领先技术供应商联合开发的——充分利用下一代服务器、操作系统和微处理器的最新性能、安全性及可扩展性的增强功能。
-快速裸机性能支持无限数量的服务器及虚拟机,拥有业界领先的整合比率,在最具有挑战性的应用负载上实现接近于物理机的性能,并且在Windows和Linux环境下性能几乎零损耗。
-简单设置及管理采用熟悉的界面,并带有简单的配置向导、直观的Web 2.0风格搜索,以及能让新管理员易学易用的内置自助功能。
-集成存储管理支持任何现有存储系统,如:主机逻辑卷管理、快照复制及动态多路径功能等内置存储管理功能。
11.2 Novell SuSE with Xen
Xen的基础虚拟化组件有Xen hypervisor、Domain 0,一些基于VM Guests,和Tools、Commands,以及一些配置文件去管理虚拟化。总的来说,物理计算机上运行所有这些组件被称为作为一个VM主机服务器,因为这些组件一起形成了一个虚拟机的管理平台。
The Xen Hypervisor:
Xen Hypervisor有时候也被称为虚拟机监视器,是一个开源的软件,协调虚拟机和物理机之间的底层硬件资源。
The Domain 0
虚拟机管理环境,同时也称为domain 0或者管理域,有一些组件组成:1)SuSE Linux操作系统,为管理虚拟机提供图形化界面以及命令行方式去管理。2)Xend守护进程,保存所有虚拟机的配置信息,以及管理和控制所有被创建的虚拟机。3)一个被修改过的QEMU,一个开源程序,模拟一个计算机系统,包含一个处理器及所有外设,为全虚拟化提供环境。
The Xen-based VM
一个Xen-based VM,也叫做Domain U或者VM Guest,主要有以下组成部分:1)至少一个虚拟磁盘,它包含一个可引导的操作系统。虚拟可以基于块设备文件,分区,卷,或其他类型的磁盘。。2)虚拟机的配置信息,可以通过Xend到处一个配置文件,或者通过虚拟机管理工具修改配置文件。3)一些虚拟网络设备,连接到控制域提供的网络中。
Management Tools, Commands, and Configuration Files
有一个GUI工具,命令和配置文件,帮助相结合您管理和定制您的虚拟化环境
11.3 Oracle VM
Oracle VM主要用于服务器虚拟化,基于开源的虚拟化技术Xen,虚拟机系统支持Windows、Linux和Oracle Solaris。另外Oracle VM提供了一个易于管理的、集成的、基于Web浏览器的管理控制台,用户的通过Web图形界面,轻松创建和管理虚拟服务器池。使用Oracle VM创建的每个虚拟机都拥有自身的虚拟CPU、网络接口、存储和操作系统,并且相互隔离。
Oracle VM主要分成Oracle VM Server和Oracle VM Manager两部分。
- • Oracle VM Server:包含一个Oracle定制优化过的Xen Hypervisor,可以进行裸机安装,内嵌Oracle VM的客户端用来连接Oracle VM Manager,进行虚拟机的创建、维护以及进行高级操作。Oracle VM Server相当于一个精简版的Linux系统,用户可以直接登录到Oracle VM Server后台进行操作。
- • Oracle VM Manager:是一个基于Web的管理控制台,由Oracle提供,界面类似OEM,用户直接登录Oracle VM Manager对Oracle VM平台进行控制。
Oracle VM功能介绍:
高可用性
a)基于可靠的Oracle ClusterWare技术实现
b)无需复杂的传统高可用集群配置,及时可靠
c)自动重启服务器池中失效的虚拟机
安全在线迁移
a)在不中断应用的情况下在不同主机间迁移
b)使用加密传输的方式动态迁移虚拟机
IO管理
a)虚拟机网卡IO限制配置
b)虚拟机磁盘IO优先级配置
c)虚拟机CPU优先级配置
自动系统均衡
a)服务器池中所有虚拟机自动实现负载均衡
b)用户可以根据喜好自定义服务器池
c)根据计算资源(CPU、内存和网络)选择服务器














 2762
2762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









