







前言
由于图像的问题学习机器学习,选择TensorFlow,但似乎直接从ImageNet的例子出发,却发现怎么都找不到头(python也不会,机器学习也不懂),但根据我以往的经验,遇到这种情况,又没有明眼人指路时,就瞎碰(没错,就是瞎碰),从一点开始,遇到什么看什么,看相关的各种知识,最好能反复两遍以上,然后揪住其中一个例子,联系之前看过的东西,加深一遍理解。
当然如果只是把现成的东西拿来用,就不用这么复杂了,简单了解下就行。但若要变通运用,上面就是我的方法。
背景介绍
TensorFlow官网上的几个例子教程,简单看起来都不难(个人是个机器学习零基础,数学也不怎么样的人,所以它似乎真的不难),只要根据上面提供的链接,读些相关paper就好,下面是官网教程的链接。
https://www.tensorflow.org/versions/r0.9/tutorials/index.html
本想从ImageNet开始,但是它没教模型怎么构建,直接给了个模型文件,加载进去的。所以不得回过头从最简单的例子开始。就是这个mnist(手写体识别)教程。
mnist
这是个什么东西,大家自行google。
Tensorflow的官网给到两个例子,简单的例子,通过一般的机器学习算法实现。涉及到的概念在上一篇帖子提到了,大家可以自己看下:
- logistic regression
- ReLU activation激活函数
- dropout
- Softmax regression
- cross entropy交叉熵
- hypothesis function
- cost function/loss function
- gradient descent 梯度下降
个人觉得不完全理解也没关系,好事多磨,总有个过程,我也不理解。。。。。
还有个关于CNN的例子,这是我的目的。
mnist 神经网络实现
据官网说这个的识别率更高,我相信了,因为这本来就是我的目的,下面是代码,我机器上的存放路径
~/libsource/tensorflow/tensorflow/models/image/mnist:
# Copyright 2015 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Simple, end-to-end, LeNet-5-like convolutional MNIST model example.
This should achieve a test error of 0.7%. Please keep this model as simple and
linear as possible, it is meant as a tutorial for simple convolutional models.
Run with --self_test on the command line to execute a short self-test.
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import gzip
import os
import sys
import time
import numpy
from six.moves import urllib
from six.moves import xrange # pylint: disable=redefined-builtin
import tensorflow as tf
SOURCE_URL = 'http://yann.lecun.com/exdb/mnist/'
WORK_DIRECTORY = 'data'
IMAGE_SIZE = 28
NUM_CHANNELS = 1
PIXEL_DEPTH = 255
NUM_LABELS = 10
VALIDATION_SIZE = 5000 # Size of the validation set.
SEED = 66478 # Set to None for random seed.
BATCH_SIZE = 64
NUM_EPOCHS = 10
EVAL_BATCH_SIZE = 64
EVAL_FREQUENCY = 100 # Number of steps between evaluations.
tf.app.flags.DEFINE_boolean("self_test", False, "True if running a self test.")
FLAGS = tf.app.flags.FLAGS
def maybe_download(filename):
"""Download the data from Yann's website, unless it's already here."""
if not tf.gfile.Exists(WORK_DIRECTORY):
tf.gfile.MakeDirs(WORK_DIRECTORY)
filepath = os.path.join(WORK_DIRECTORY, filename)
if not tf.gfile.Exists(filepath):
filepath, _ = urllib.request.urlretrieve(SOURCE_URL + filename, filepath)
with tf.gfile.GFile(filepath) as f:
size = f.Size()
print('Successfully downloaded', filename, size, 'bytes.')
return filepath
def extract_data(filename, num_images):
"""Extract the images into a 4D tensor [image index, y, x, channels].
Values are rescaled from [0, 255] down to [-0.5, 0.5].
"""
print('Extracting', filename)
with gzip.open(filename) as bytestream:
bytestream.read(16)
buf = bytestream.read(IMAGE_SIZE * IMAGE_SIZE * num_images)
data = numpy.frombuffer(buf, dtype=numpy.uint8).astype(numpy.float32)
data = (data - (PIXEL_DEPTH / 2.0)) / PIXEL_DEPTH
data = data.reshape(num_images, IMAGE_SIZE, IMAGE_SIZE, 1)
return data
def extract_labels(filename, num_images):
"""Extract the labels into a vector of int64 label IDs."""
print('Extracting', filename)
with gzip.open(filename) as bytestream:
bytestream.read(8)
buf = bytestream.read(1 * num_images)
labels = numpy.frombuffer(buf, dtype=numpy.uint8).astype(numpy.int64)
return labels
def fake_data(num_images):
"""Generate a fake dataset that matches the dimensions of MNIST."""
data = numpy.ndarray(
shape=(num_images, IMAGE_SIZE, IMAGE_SIZE, NUM_CHANNELS),
dtype=numpy.float32)
labels = numpy.zeros(shape=(num_images,), dtype=numpy.int64)
for image in xrange(num_images):
label = image % 2
data[image, :, :, 0] = label - 0.5
labels[image] = label
return data, labels
def error_rate(predictions, labels):
"""Return the error rate based on dense predictions and sparse labels."""
return 100.0 - (
100.0 *
numpy.sum(numpy.argmax(predictions, 1) == labels) /
predictions.shape[0])
def main(argv=None): # pylint: disable=unused-argument
if FLAGS.self_test:
print('Running self-test.')
train_data, train_labels = fake_data(256)
validation_data, validation_labels = fake_data(EVAL_BATCH_SIZE)
test_data, test_labels = fake_data(EVAL_BATCH_SIZE)
num_epochs = 1
else:
# Get the data.
train_data_filename = maybe_download('train-images-idx3-ubyte.gz')
train_labels_filename = maybe_download('train-labels-idx1-ubyte.gz')
test_data_filename = maybe_download('t10k-images-idx3-ubyte.gz')
test_labels_filename = maybe_download('t10k-labels-idx1-ubyte.gz')
# Extract it into numpy arrays.
train_data = extract_data(train_data_filename, 60000)
train_labels = extract_labels(train_labels_filename, 60000)
test_data = extract_data(test_data_filename, 10000)
test_labels = extract_labels(test_labels_filename, 10000)
# Generate a validation set.
validation_data = train_data[:VALIDATION_SIZE, ...]
validation_labels = train_labels[:VALIDATION_SIZE]
train_data = train_data[VALIDATION_SIZE:, ...]
train_labels = train_labels[VALIDATION_SIZE:]
num_epochs = NUM_EPOCHS
train_size = train_labels.shape[0]
# This is where training samples and labels are fed to the graph.
# These placeholder nodes will be fed a batch of training data at each
# training step using the {feed_dict} argument to the Run() call below.
train_data_node = tf.placeholder(
tf.float32,
shape=(BATCH_SIZE, IMAGE_SIZE, IMAGE_SIZE, NUM_CHANNELS))
train_labels_node = tf.placeholder(tf.int64, shape=(BATCH_SIZE,))
eval_data = tf.placeholder(
tf.float32,
shape=(EVAL_BATCH_SIZE, IMAGE_SIZE, IMAGE_SIZE, NUM_CHANNELS))
# The variables below hold all the trainable weights. They are passed an
# initial value which will be assigned when we call:
# {tf.initialize_all_variables().run()}
conv1_weights = tf.Variable(
tf.truncated_normal([5, 5, NUM_CHANNELS, 32], # 5x5 filter, depth 32.
stddev=0.1,
seed=SEED))
conv1_biases = tf.Variable(tf.zeros([32]))
conv2_weights = tf.Variable(
tf.truncated_normal([5, 5, 32, 64],
stddev=0.1,
seed=SEED))
conv2_biases = tf.Variable(tf.constant(0.1, shape=[64]))
fc1_weights = tf.Variable( # fully connected, depth 512.
tf.truncated_normal(
[IMAGE_SIZE // 4 * IMAGE_SIZE // 4 * 64, 512],
stddev=0.1,
seed=SEED))
fc1_biases = tf.Variable(tf.constant(0.1, shape=[512]))
fc2_weights = tf.Variable(
tf.truncated_normal([512, NUM_LABELS],
stddev=0.1,
seed=SEED))
fc2_biases = tf.Variable(tf.constant(0.1, shape=[NUM_LABELS]))
# We will replicate the model structure for the training subgraph, as well
# as the evaluation subgraphs, while sharing the trainable parameters.
def model(data, train=False):
"""The Model definition."""
# 2D convolution, with 'SAME' padding (i.e. the output feature map has
# the same size as the input). Note that {strides} is a 4D array whose
# shape matches the data layout: [image index, y, x, depth].
conv = tf.nn.conv2d(data,
conv1_weights,
strides=[1, 1, 1, 1],
padding='SAME')
# Bias and rectified linear non-linearity.
relu = tf.nn.relu(tf.nn.bias_add(conv, conv1_biases))
# Max pooling. The kernel size spec {ksize} also follows the layout of
# the data. Here we have a pooling window of 2, and a stride of 2.
pool = tf.nn.max_pool(relu,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
padding='SAME')
conv = tf.nn.conv2d(pool,
conv2_weights,
strides=[1, 1, 1, 1],
padding='SAME')
relu = tf.nn.relu(tf.nn.bias_add(conv, conv2_biases))
pool = tf.nn.max_pool(relu,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
padding='SAME')
# Reshape the feature map cuboid into a 2D matrix to feed it to the
# fully connected layers.
pool_shape = pool.get_shape().as_list()
reshape = tf.reshape(
pool,
[pool_shape[0], pool_shape[1] * pool_shape[2] * pool_shape[3]])
# Fully connected layer. Note that the '+' operation automatically
# broadcasts the biases.
hidden = tf.nn.relu(tf.matmul(reshape, fc1_weights) + fc1_biases)
# Add a 50% dropout during training only. Dropout also scales
# activations such that no rescaling is needed at evaluation time.
if train:
hidden = tf.nn.dropout(hidden, 0.5, seed=SEED)
return tf.matmul(hidden, fc2_weights) + fc2_biases
# Training computation: logits + cross-entropy loss.
logits = model(train_data_node, True)
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(
logits, train_labels_node))
# L2 regularization for the fully connected parameters.
regularizers = (tf.nn.l2_loss(fc1_weights) + tf.nn.l2_loss(fc1_biases) +
tf.nn.l2_loss(fc2_weights) + tf.nn.l2_loss(fc2_biases))
# Add the regularization term to the loss.
loss += 5e-4 * regularizers
# Optimizer: set up a variable that's incremented once per batch and
# controls the learning rate decay.
batch = tf.Variable(0)
# Decay once per epoch, using an exponential schedule starting at 0.01.
learning_rate = tf.train.exponential_decay(
0.01, # Base learning rate.
batch * BATCH_SIZE, # Current index into the dataset.
train_size, # Decay step.
0.95, # Decay rate.
staircase=True)
# Use simple momentum for the optimization.
optimizer = tf.train.MomentumOptimizer(learning_rate,
0.9).minimize(loss,
global_step=batch)
# Predictions for the current training minibatch.
train_prediction = tf.nn.softmax(logits)
# Predictions for the test and validation, which we'll compute less often.
eval_prediction = tf.nn.softmax(model(eval_data))
# Small utility function to evaluate a dataset by feeding batches of data to
# {eval_data} and pulling the results from {eval_predictions}.
# Saves memory and enables this to run on smaller GPUs.
def eval_in_batches(data, sess):
"""Get all predictions for a dataset by running it in small batches."""
size = data.shape[0]
if size < EVAL_BATCH_SIZE:
raise ValueError("batch size for evals larger than dataset: %d" % size)
predictions = numpy.ndarray(shape=(size, NUM_LABELS), dtype=numpy.float32)
for begin in xrange(0, size, EVAL_BATCH_SIZE):
end = begin + EVAL_BATCH_SIZE
if end <= size:
predictions[begin:end, :] = sess.run(
eval_prediction,
feed_dict={eval_data: data[begin:end, ...]})
else:
batch_predictions = sess.run(
eval_prediction,
feed_dict={eval_data: data[-EVAL_BATCH_SIZE:, ...]})
predictions[begin:, :] = batch_predictions[begin - size:, :]
return predictions
# Create a local session to run the training.
start_time = time.time()
with tf.Session() as sess:
# Run all the initializers to prepare the trainable parameters.
tf.initialize_all_variables().run()
print('Initialized!')
# Loop through training steps.
for step in xrange(int(num_epochs * train_size) // BATCH_SIZE):
# Compute the offset of the current minibatch in the data.
# Note that we could use better randomization across epochs.
offset = (step * BATCH_SIZE) % (train_size - BATCH_SIZE)
batch_data = train_data[offset:(offset + BATCH_SIZE), ...]
batch_labels = train_labels[offset:(offset + BATCH_SIZE)]
# This dictionary maps the batch data (as a numpy array) to the
# node in the graph it should be fed to.
feed_dict = {train_data_node: batch_data,
train_labels_node: batch_labels}
# Run the graph and fetch some of the nodes.
_, l, lr, predictions = sess.run(
[optimizer, loss, learning_rate, train_prediction],
feed_dict=feed_dict)
if step % EVAL_FREQUENCY == 0:
elapsed_time = time.time() - start_time
start_time = time.time()
print('Step %d (epoch %.2f), %.1f ms' %
(step, float(step) * BATCH_SIZE / train_size,
1000 * elapsed_time / EVAL_FREQUENCY))
print('Minibatch loss: %.3f, learning rate: %.6f' % (l, lr))
print('Minibatch error: %.1f%%' % error_rate(predictions, batch_labels))
print('Validation error: %.1f%%' % error_rate(
eval_in_batches(validation_data, sess), validation_labels))
sys.stdout.flush()
# Finally print the result!
test_error = error_rate(eval_in_batches(test_data, sess), test_labels)
print('Test error: %.1f%%' % test_error)
if FLAGS.self_test:
print('test_error', test_error)
assert test_error == 0.0, 'expected 0.0 test_error, got %.2f' % (
test_error,)
if __name__ == '__main__':
tf.app.run()
其tensorflow图如下图所示: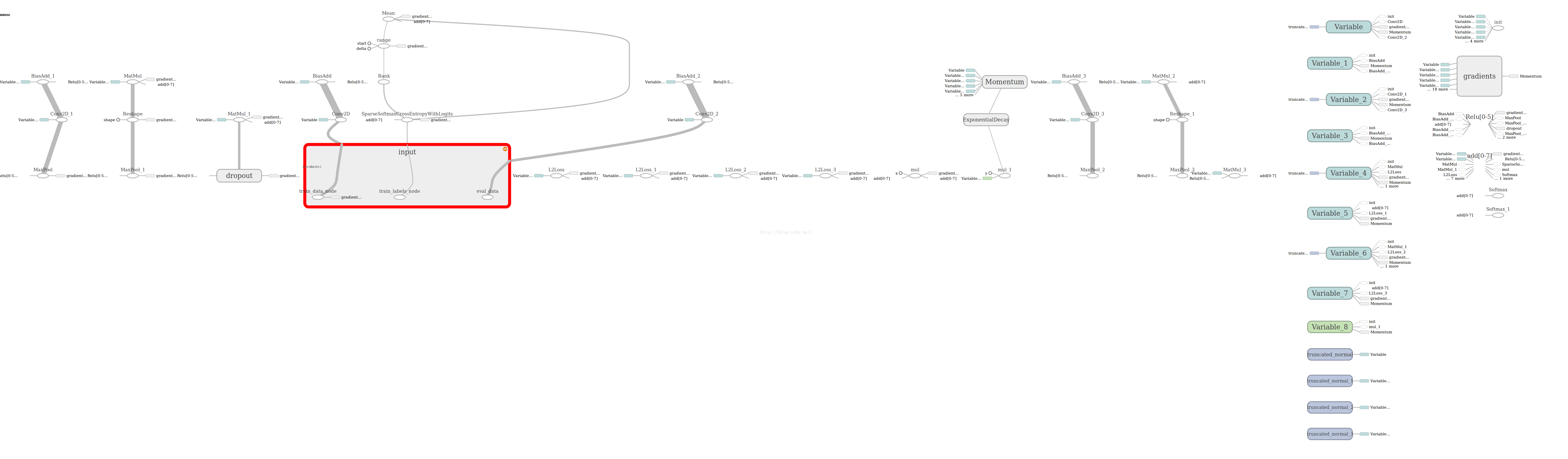
解读
- 由于没写过python,所以一开始我就困惑了,这货为什么有两个main函数入口:
if __name__ == '__main__':
def main(argv=None): # pylint: disable=unused-argument解释见下面两篇帖子:
http://stackoverflow.com/questions/419163/what-does-if-name-main-do
http://stackoverflow.com/questions/4041238/why-use-def-main
-
待续。。。。














 4299
4299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









