







scrapy抓取csdn中标题带有“语义”关键字的文章的标题和链接
实现步骤
- 中文字符比对
中文字符比对
首先了解一下ASCII,Unicode和UTF-8:
http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
大体意思就是ASCII是单字节编码,能表示的字符有限。unicode能表示世界上的所有字符,但占有的空间太大。utf-8是unicode编码中的一种,能够有效的节省空间。
Python 编码转换与中文处理
http://www.jianshu.com/p/53bb448fe85b
关于编码的官方文档:
https://docs.python.org/2/howto/unicode.html#encodings
csdn的中文标题字符的比对
由于要处理的csdn的中文字符,那么先以一个链接的标题作为例子:
http://blog.csdn.net/searobbers_duck/article/details/51669224
* 抓取网页中的内容:
scrapy shell http://blog.csdn.net/searobbers_duck/article/details/51669224- 获得标题:
title = response.xpath('//title/text()').extract()
print title是乱码:
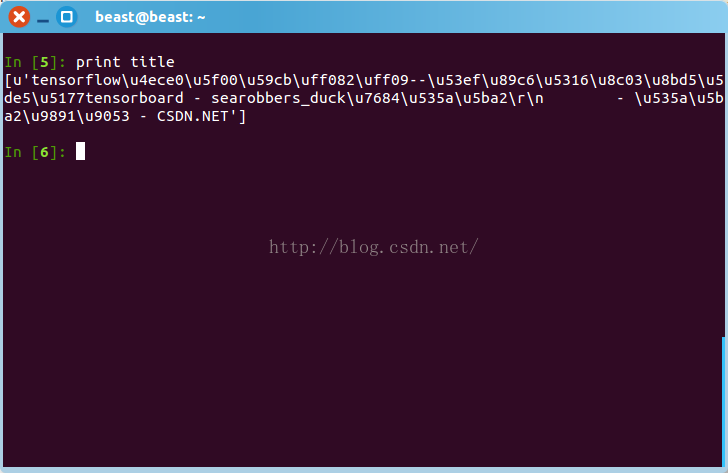
- 查看编码格式:
import chardet
chardet.detect(title[0])
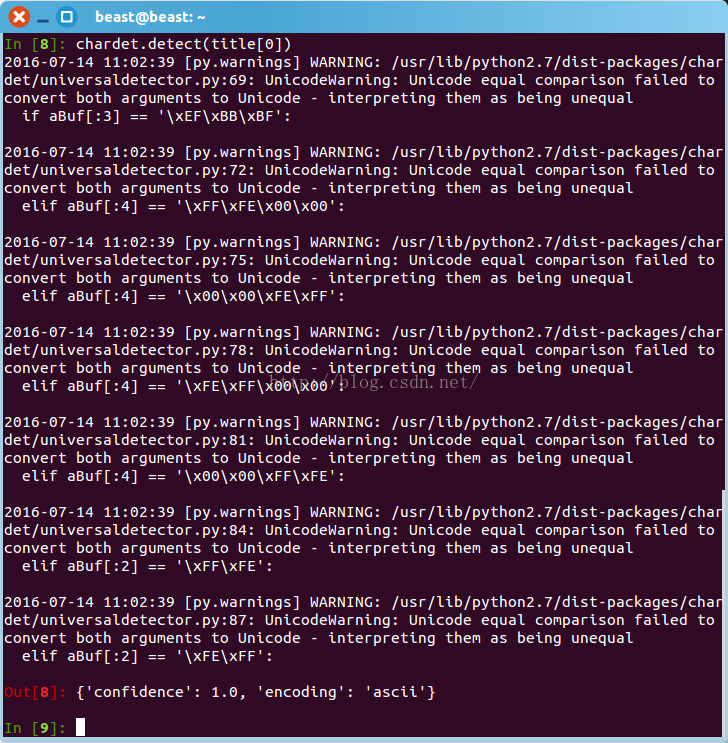
- 变为unicode编码:
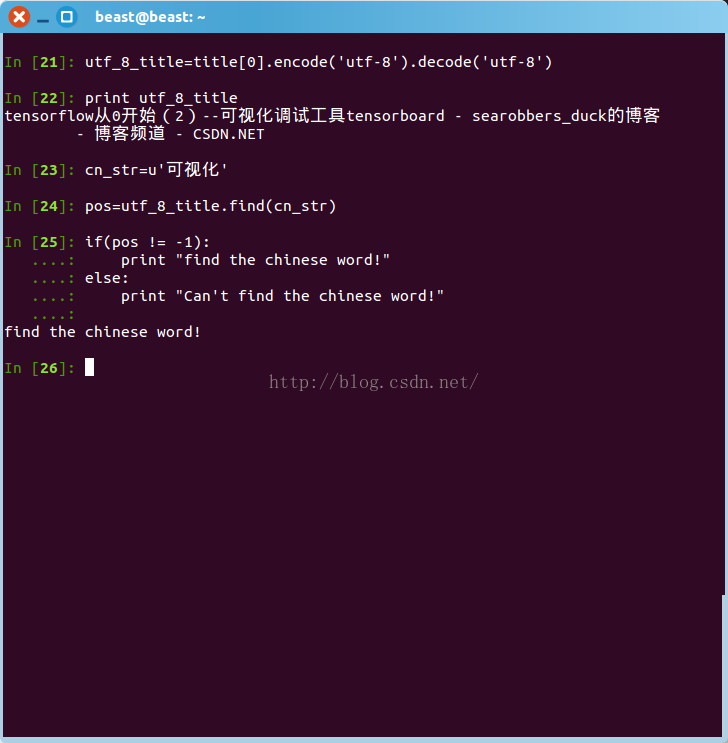
utf_8_title=title[0].encode('utf-8').decode('utf-8')
print utf_8_title- 查找是否包含指定中文字符
cn_str=u'可视化'
pos=utf_8_title.find(cn_str)
if(pos!=-1):
print "find the chinese word!"
else:
print "Can't find the chinese word!"
mysql数据库相关操作
爬虫程序
- 创建工程
scrapy startproject csdn_semantics_spider
cd csdn_semantics_spider
tree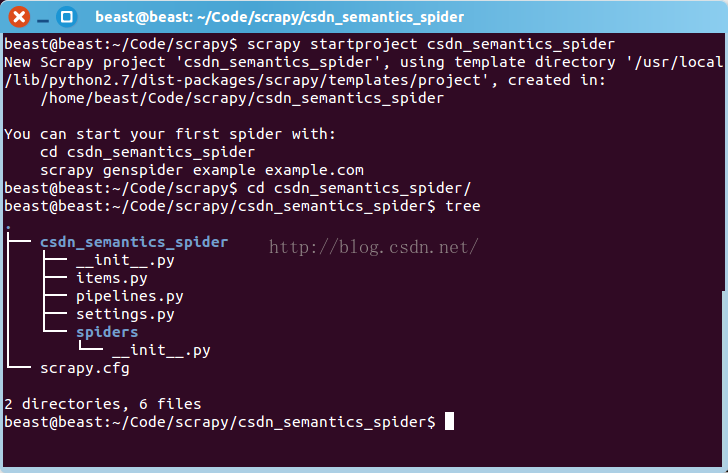
- 修改items.py
item中定义了,在爬虫爬取过程中,需要爬取的内容项。这里主要爬取标题(title),链接(link),描述(desc)
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class CsdnSemanticsSpiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
pass- 修改创建spider文件
gedit csdn_semantics_spider/spider/csdn_semantics_spider1.py修改其内容如下:
#coding=utf-8
import re
import json
from scrapy.selector import Selector
try:
from scrapy.spider import Spider
except:
from scrapy.spider import BaseSpider as Spider
from scrapy.utils.response import get_base_url
from scrapy.utils.url import urljoin_rfc
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor as sle
from csdn_semantics_spider.items import *
class CsdnSemanticsSpider(CrawlSpider):
#定义爬虫的名称
name = "CsdnSemanticsSpider"
#定义允许抓取的域名,如果不是在此列表的域名则放弃抓取
allowed_domains = ["blog.csdn.net"]
#定义抓取的入口url
start_urls = [
"http://blog.csdn.net/searobbers_duck/article/details/51839799"
]
# 定义爬取URL的规则,并指定回调函数为parse_item
# rules = [
# Rule(sle(allow=("/\S{1,}/article\details/\d{1,}")), #此处要注意?号的转换,复制过来需要对?号进行转义。
# follow=True,
# callback='parse_item')
rules = [
Rule(sle(allow=("/\S{1,}/article/details/\d{1,}")), #此处要注意?号的转换,复制过来需要对?号进行转义。
follow=True,
callback='parse_item')
]
#print "**********CnblogsSpider**********"
#定义回调函数
#提取数据到Items里面,主要用到XPath和CSS选择器提取网页数据
def parse_item(self, response):
#print "-----------------"
items = []
sel = Selector(response)
base_url = get_base_url(response)
title = sel.css('title').xpath('text()').extract()
key_substr=u'语义'
for index in range(len(title)):
item = CsdnSemanticsSpiderItem()
item['title']=title[index].encode('utf-8').decode('utf-8')
pos=item['title'].find(key_substr)
print item['title']
if(pos != -1):
#print item['title'] + "***************\r\n"
print item['title']
item['link']=base_url
item['desc']=item['title']
#print base_url + "********\n"
items.append(item)
#print repr(item).decode("unicode-escape") + '\n'
return items
- 修改pipelines.py文件
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
import codecs
class JsonWithEncodingCsdnSemanticsPipeline(object):
def __init__(self):
self.file = codecs.open('csdn_semantics.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
def spider_closed(self, spider):
self.file.close()- 修改setting.py
在setting.py中添加:
ITEM_PIPELINES = {
'csdn_semantics_spider.pipelines.JsonWithEncodingCsdnSemanticsPipeline': 300,
}
LOG_LEVEL = 'INFO'- 上述修改完成后,运行爬虫程序
scrapy crawl CsdnSemanticsSpider效果如下:
将爬取的信息写入数据库
- 数据库模块
创建一个名为“csdn_semantics_db”的数据库,并建好表格,代码如下:
drop database if exists csdn_semantics_db;
create database if not exists csdn_semantics_db default character set utf8 collate utf8_general_ci;
use csdn_semantics_db;
create table if not exists csdn_semantics_info(linkmd5id char(32) NOT NULL, title text, link text, description text, updated datetime DEFAULT NULL, primary key(linkmd5id)) ENGINE=MyISAM DEFAULT CHARSET=utf8;
select * from csdn_semantics_info;
- 修改pipelines.py的内容:
代码如下,如有sql语句疑问请访问链接: http://blog.csdn.net/searobbers_duck/article/details/51889556
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
import codecs
from datetime import datetime
from hashlib import md5
import MySQLdb
import MySQLdb.cursors
from twisted.enterprise import adbapi
class JsonWithEncodingCsdnSemanticsPipeline(object):
def __init__(self):
self.file = codecs.open('csdn_semantics.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
def spider_closed(self, spider):
self.file.close()
class MySQLStoreCsdnSemanticsPipeline(object):
def __init__(self, dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls, settings):
dbargs = dict(
host=settings['MYSQL_HOST'],
db=settings['MYSQL_DBNAME'],
user=settings['MYSQL_USER'],
passwd=settings['MYSQL_PASSWD'],
charset='utf8',
cursorclass = MySQLdb.cursors.DictCursor,
use_unicode= True,
)
dbpool = adbapi.ConnectionPool('MySQLdb', **dbargs)
return cls(dbpool)
#pipeline默认调用
def process_item(self, item, spider):
d = self.dbpool.runInteraction(self._do_upinsert, item, spider)
d.addErrback(self._handle_error, item, spider)
d.addBoth(lambda _: item)
return d
#将每行更新或写入数据库中
def _do_upinsert(self, conn, item, spider):
linkmd5id = self._get_linkmd5id(item)
#print linkmd5id
now = datetime.utcnow().replace(microsecond=0).isoformat(' ')
insertcmd="insert into csdn_semantics_info values('%s','%s','%s','%s', '%s') on duplicate key update title='%s', link='%s', description='%s', updated='%s'"%(linkmd5id, item['title'], item['link'],item['desc'], now, item['title'], item['link'],item['desc'], now)
conn.execute(insertcmd)
#获取url的md5编码
def _get_linkmd5id(self, item):
#url进行md5处理,为避免重复采集设计
return md5(item['link']).hexdigest()
#异常处理
def _handle_error(self, failue, item, spider):
log.err(failure)源代码地址:https://github.com/searobbersduck/CsdnSemanticScrapy.git














 7880
7880











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









