







前言
随着大数据,互联网应用的快速发展,海量数据的存储和访问成为了系统设计的瓶颈问题。对于一个大型的应用系统,每天几十亿的的数据无疑对数据库造成了相当高的负载。对于系统的稳定性和扩展性造成了极大的问题。通过数据切分来提高性能,横向扩展数据层的分布式数据库已经成为一个趋势。水平切分数据库,可以降低单台机器的负载,同时最大限度的降低了宕机造成的损失。通过负载均衡策略,有效的降低了单台机器的访问负载,降低了宕机的可能性;通过集群方案,解决了数据库宕机带来的单点数据库不能访问的问题;通过读写分离策略更是最大限度了提高了应用中读取(Read)数据的速度和并发量。
在这里,我们主要介绍一下MySQL的集群策略以及跟SDB的集群的扩展。
MySQL集群
一 MySQL Cluster
1、Cluster的介绍
MySQL Cluster的关键部分--sql node(MySQL Server)、data node(storage或者ndbd)。至于它的结构,我们从图形来进行理解。
下面是最小配置的cluster,使用两台机器:
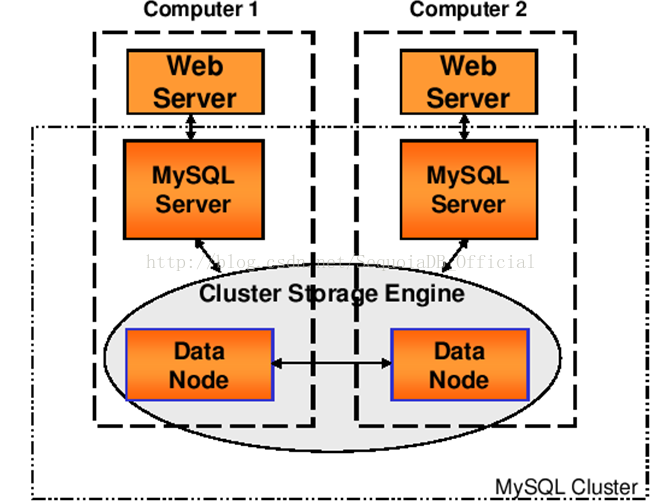
上图有两个数据节点(用于保存持久化数据的)、两个SQL节点(提供给应用程序访问的前端)。
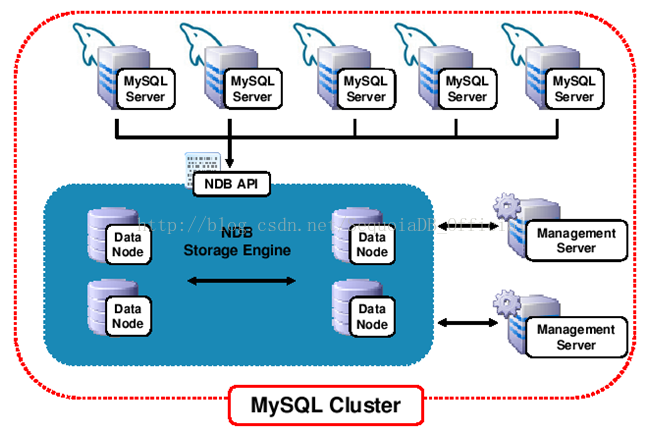
下面是用了五台机器的cluster:
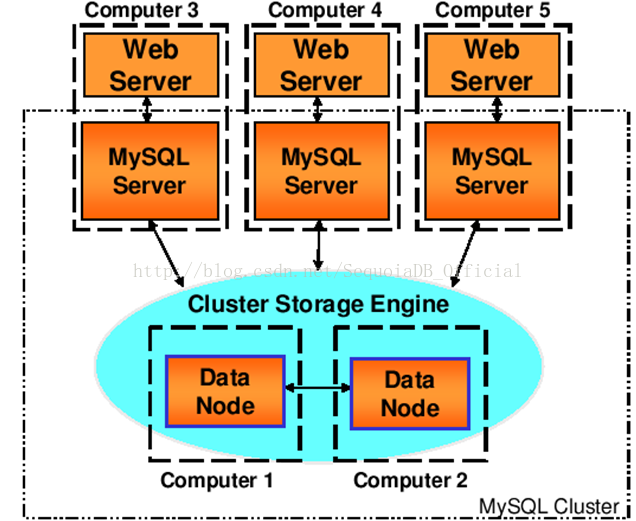
上图有三个SQL节点,两个数据节点。每个节点都独自使用一台机器。
2、数据存储的冗余与分布
sql节点不存储数据;数据节点之间可以是冗余数据,也可以是分布存储,即一份数据拆成多份,保存在不同的节点上。见下图:
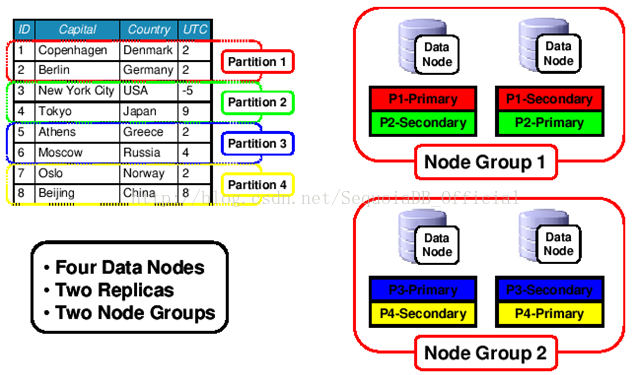
上图表述在4个数据节点的情况下,拆分一个表的存储。左上是一张表,字段是ID、CAPITAL、COUNTRY、UTC。目前MySQL Cluster是根据数据节点的个数,和replica的个数(即冗余的份数),对主键进行HASH,分布存储到各个节点中。每一个组的成员个数与replica的个数相同。
当有数据节点出现宕机情况时,系统仍然可用。如下图:
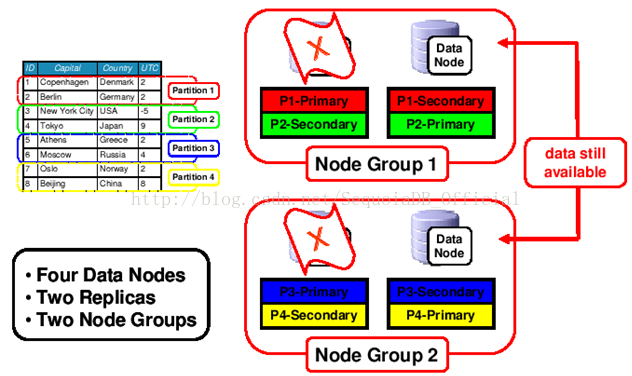
下面是集群的高可用方案:
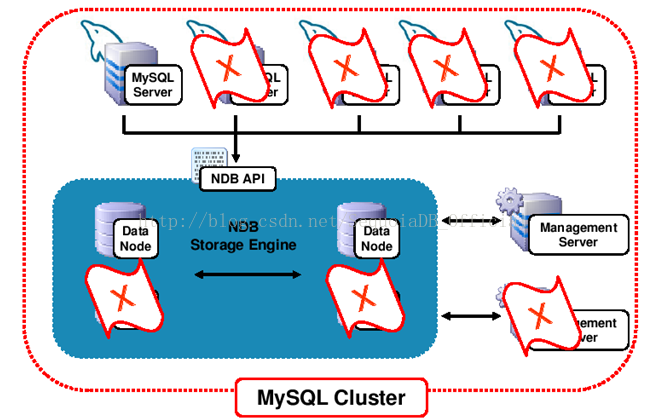
上图坏掉了两个数据节点、四个SQL节点、一个管理节点,cluster仍然是“活”的。
3、Cluster的优缺点
l 能运行在普通硬件上,不需要专业的存储设备;
l 一个节点失败不会导致其他节点失败;
l 数据节点和前端(SQL节点)都可以避免单点失效;
l 数据的冗余是同步方式,不像复制采用异步方式;一个数据节点实效,它的备份节点的数据不会与其不一致;
l 不能在线增加和舍弃节点(需要做全备和恢复,需要重启整个cluster);
l 本身不实现动态的负载均衡;
l 管理复杂程度比复制高;
l 目前应用的广泛程度远不及它的复制。
4、Cluster的限制
l 自增长列必须是主键;
l 不支持事务的部分回滚,重复键或者类似的错误会导致整个事务回滚;
l 只支持read committed隔离级别;
l varchar占用与char相同的空间;
l 外键被忽略;
l 保存点被忽略;
l 执行范围扫描时,开销相对昂贵;
l 最大节点数为63;
l 数据节点最多为48;
l 不适宜处理大事务;
l commit时不能保证日志刷新到硬盘;
l delete某个表的数据,释放的空间,只由在同一个表的insert时再被使用,不会被其他表使用;
l 限制比较多,参见官方文档,不一一列出了。
二 MySQL Replication(master+slave)
1、Replication的基本原理
MySQL Replication是两个MySQL服务器之间的异步数据复制。
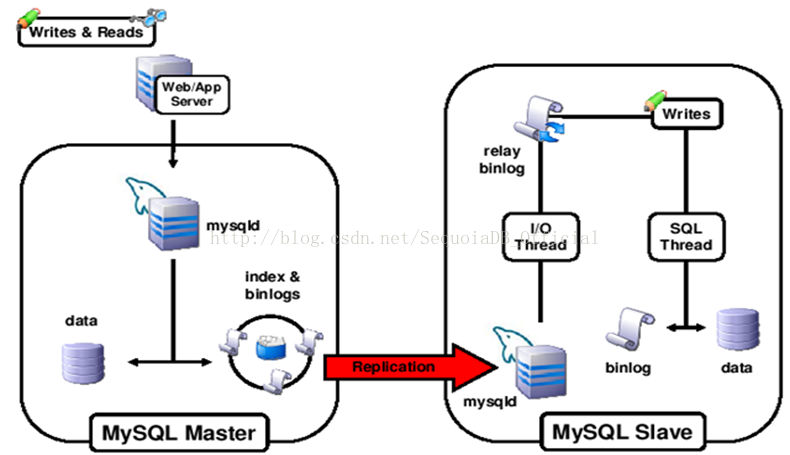
两个MySQL服务器,一个为Master(主),一个为Slave(从)。master开启二进制日志;slave启动一个线程连接master,来不断地获取master的二进制日志,并写到本地的relay binlog文件中;slave启动另一个线程把reIay binlog文件中的日志应用到slave数据库中;master中有一个线程负责与slave通讯,不断的读取二进制日志,并传递给slave。
2、只基于复制的高可用方案
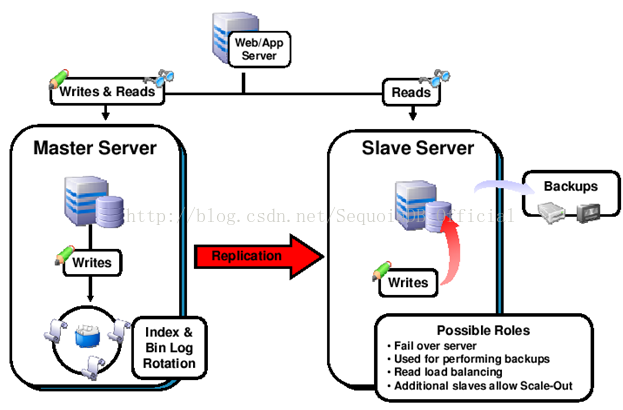
slave可以用做master的备份;slave可以分流读操作;备份到其他介质时,可从slave备份,而不增加master的负载。
当master出现问题时:
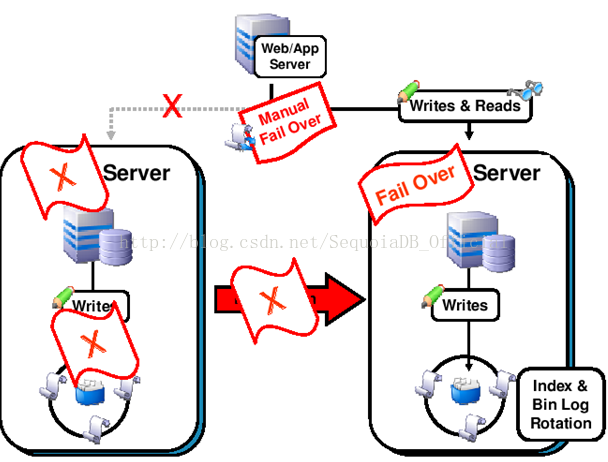
master失效时,通过手工操作,让应用只访问slave。
3、复制(Replication)的优缺点
l slave可以作为master的备份;
l 是异步的,不会给master带来很大的压力,但某些情况下,当master宕掉时,可能有些数据还未复制到slave中去;
l 配置简单;
l master和slave相对独立,建立新的复制关系时不必停机;当其中一方宕机,另一方还可以继续运转;宕机的一方经过恢复后,重新建立复制关系,也不需要正在运转的一方停机;
l 应用广泛,这是MySQL非常成熟的技术,大量的案例都使用了复制;
l slave可以分流数据库读操作,但这需要应用程序分别处理数据库的读和写;
l 可以对slave进行备份,而不影响master;特别是可以lock所有表,然后做文件拷贝,甚至停止slave的MySQL服务,然后做文件拷贝,数据量大时,比mysqldump速度快。
4、复制(Replication)的限制
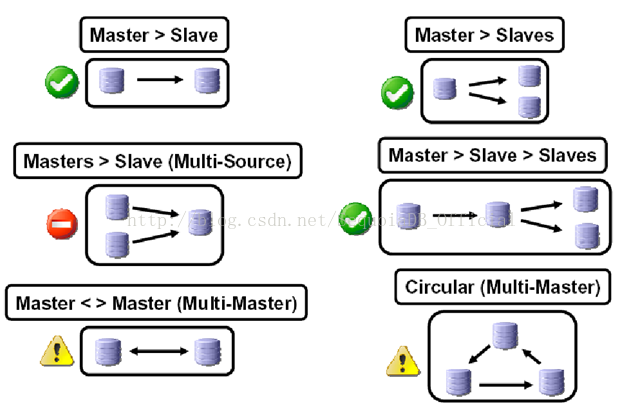
一个master可以带多个slave;一个slave只能有一个master;slave也同时可以作为master,从而形成链式复制、双向复制、环式复制。但双向复制和环式复制,在官方文档中并不提倡,因为容易产生冲突,冲突之后也没有自动解决的机制。
如下图:
三 Mycat实现MySQL集群
1、Mycat概述
Mycat从定义和分类来看,它是一个开源的分布式数据库系统,是一个实现了MySQL协议的服务器,前端用户可以把它看作是一个数据库代理,用MySQL客户端工具和命令行访问,而其后端可以用MySQL原生协议与多个MySQL服务器通信,也可以用JDBC协议与大多数主流数据库服务器通信,其核心功能是分表分库,即将一个大表水平分割为N个小表,存储在后端MySQL服务器里或者其他数据库里。
MyCat发展到目前的版本,已经不是一个单纯的MySQL代理了,它的后端可以支持MySQL、SQL Server、Oracle、DB2、PostgreSQL等主流数据库,也支持MongoDB这种新型NoSQL方式的存储,未来还会支持更多类型的存储。而在最终用户看来,无论是那种存储方式,在MyCat里,都是一个传统的数据库表,支持标准的SQL语句进行数据的操作,这样一来,对前端业务系统来说,可以大幅降低开发难度,提升开发速度。
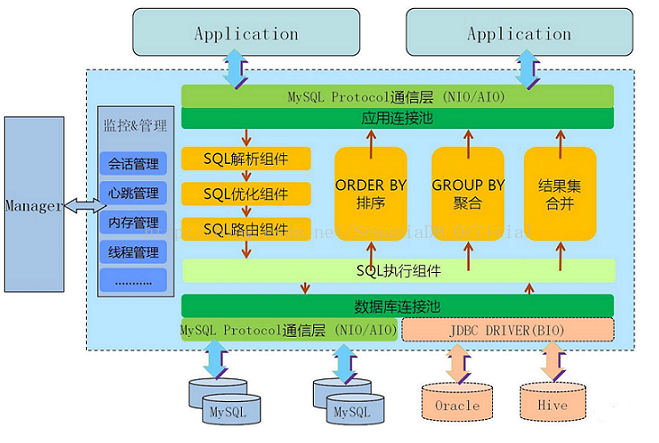
Mycat架构图
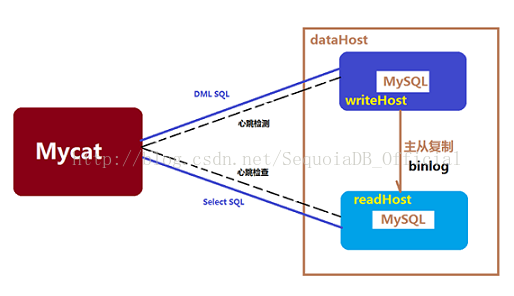
Mycat支持基于MySQL主从复制状态的高级读写分离控制机制
读写分离
读写分离定义
为了确保数据库产品的稳定性,很多数据库拥有双机热备功能。也就是,第一台数据库服务器,是对外提供增删改查业务的生产服务器;第二台数据库服务器,仅仅接收来自第一台服务器的备份数据。一般来说,为了配置方便,以及稳定性,这两台数据库服务器,都用的是相同的配置。
在实际运行中,第一台数据库服务器的压力,远远大于第二台数据库服务器。因此,很多人希望合理利用第二台数据库服务器的空闲资源。
从数据库的基本业务来看,数据库的操作无非就是增删改查这4个操作。但对于“增删改”这三个操作,如果是双机热备的环境中做,一台机器做了这三个操作的某一个之后,需要立即将这个操作,同步到另一台服务器上。出于这个原因,第二台备用的服务器,就只做了查询操作。进一步,为了降低第一台服务器的压力,干脆就把查询操作全部丢给第二台数据库服务器去做,第一台数据库服务器就只做增删改了。
优缺点
优点:合理利用从数据库服务器的空闲资源。
缺点:本来第二台数据库服务器,是用来做热备的,它就应该在一个压力非常小的环境下,保证运行的稳定性。而读写分离,却增加了它的压力,也就增加了不稳定性。因此,读写分离,实质上是一个在资金比较缺乏,但又需要保证数据安全的需求下,在双机热备方案上,做出的一种折中的扩展方案。
SequoiaDB分布式集群
SequoiaDB 是业界领先的新一代分布式数据库产品,功能上包括了分布式 OLTP,分布式对象存储以及分布式 NoSQL 实现全类型数据的覆盖。
一、分布式架构
SequoiaDB 作为典型 Share-Nothing 的分布式数据库,同时具备高性能与高可用的特性。 SequoiaDB 采用分片技术为系统 供了横向扩展机制,其分片过程对于应用程序来说完全透明。 该机制解决了单台服务器硬件资源(如内存、CPU、磁盘 I/O)受限的问题,并不会增加应用程 序开发的复杂性。
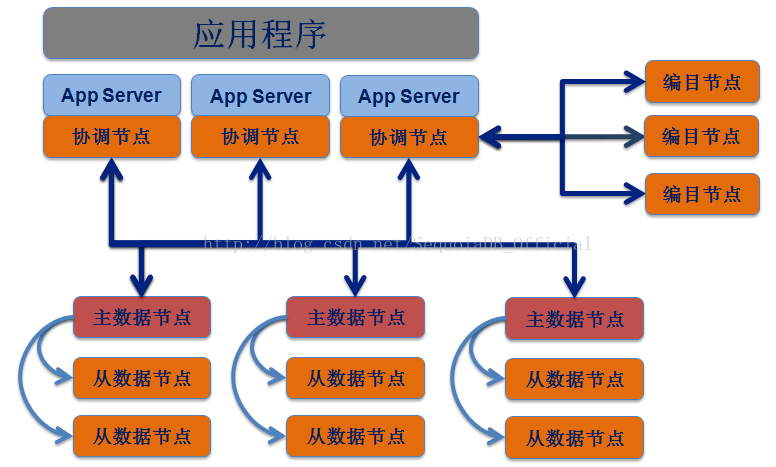
· 协调节点:负责调度、分配、汇总,是SequoiaDB的数据分发节点,本身不存储任何数据,主要负责接收应用程序的访问请求;
· 编目节点:负责存储整个数据库的部署结构与节点状态信息,并且记录集合空间与集合的参数信息,同时记录每个集合的数据切分状况;
· 数据节点:承载数据存储、计算的进程为用户 供高性能的读写服务,并且在多索引的支持下针对海量数据查询性能优越。多个数据节点可以组成一个数据节点组,采取一主多备结构。
二、弹性扩容
SequoiaDB支持横向动态扩容。用户在系统性能或存储不足时,可以通过快速扩展集群,提升系统整体性能或存储容量。通过原生的分布式架构,可以实现弹性的容量扩展,帮助用户更灵活的调整数据库的存储空间。
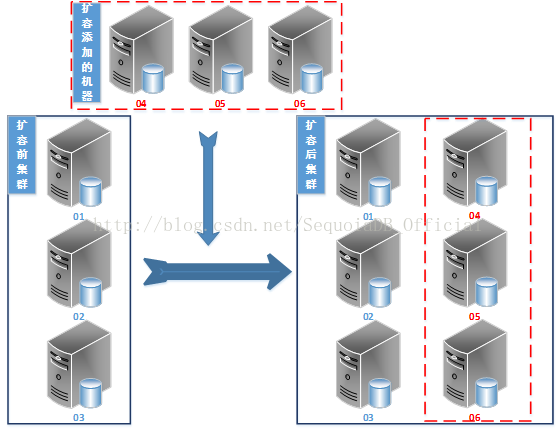
集群扩容举例
· 集群扩容过程对应用系统透明,应用系统无需修配置、程序。
· 集群扩容速度快
· 支持数据均衡分布
三、读写分离
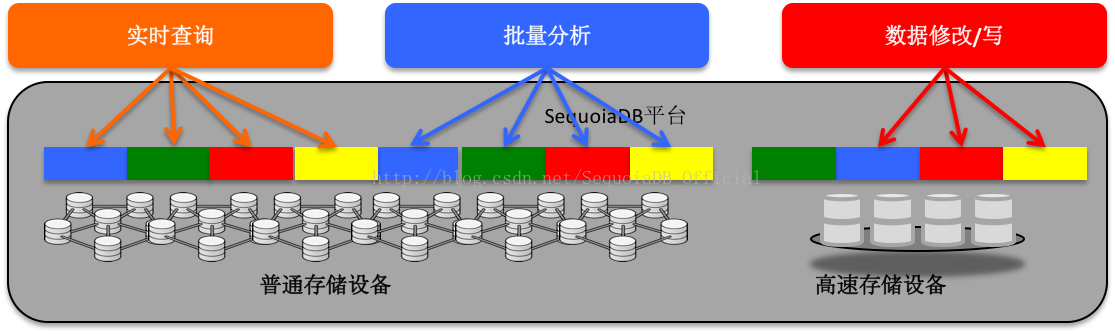
基于数据组“一主多从”的特性,SequoiaDB可以实现分布式架构下的读写分离。
• 数据在多个分布节点内自动复制,并实现写请求和读请求的自动分离,避免读请求对数据写入的影响。
此外,可进一步定制数据分布策略,保证不同类型业务可以运行在同一平台上,但同时又不会互相干扰,比如“冷/热数据区分离”,写交易的“强一致性”和“弱一致性”分离以及“查询/批量分离”
总结
从MySQL 分布式和SequoiaDB的功能和性能对比,我们可以归纳一些结论:
• 在数据量较小的情况下,使用单点的MySQL和SequoiaDB的性能差别不回特别大。
• 数据量较大的情况下,MySQL单点和
总体来说相对于MySQL,分布式数据库SequoiaDB的扩展性更加灵活,高效同时更能保证数据库的高可用。
微信客服:
sequoiadb111
















 339
339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









