









对于网站来说,实际上是不愿意让大家去爬取它的内容的,因为爬虫可能会对真实的用户带来不太好的影响(很多网站会限制流量,尤其是对爬虫产生的流量,会对服务器带来一定的压力)。所以网站会对爬虫有一定的抵制,如果不注意爬虫的技巧,有可能就被网站封杀IP,以致暂停了。
那么如何能够轻松绕过部分的反爬虫限制,书写我们的爬虫呢??
1.设定程序休止时间
连续不断的进行爬虫的抓取,就会被网站监测出来是一个爬虫程序。所以,我们应该在能够接受的速度内,尽量降低一下自己爬取的频率(中间停1-5秒,再去爬下一个),以免对这些网站产生不必要的影响,这样做也对网站的负荷会比较好。
n为你想要实现的时间间隔
import time
time.sleep(n)
2.设定代理
设定代理的原因主要有两个:
①、有时候需要爬取的网站,通过我们的网络IP没有办法去进行访问。所以需要设置代理。如:在教育网里访问外网的网站;国内的IP有时候无法访问国外的网站等。
②、有时候,不管我们怎么设置我们的爬取频率,在爬取如新浪微博、Facebook等这些很成熟的网站的时候,这些网站的反爬虫技术很高超,所以会很快的检测到我们的机器爬虫程序,从而会把我们登录访问的ip地址封掉。比如针对facebook,它会禁止这个ip地址再去访问它的网站,即使我们重新启动爬虫,从无论是正常从浏览器访问还是爬虫访问,Facebook都一律不允许这个ip地址再去访问它的网站。
那么,通过代理服务器如何进行呢??
传统:通常直接使用我们的电脑去访问网页。
通过代理服务器:我们发送一个网络的请求,会首先发送到代理服务器上,代理服务器再把这个请求转发到网页所在的网站服务器。网站服务器回复的反馈会先发送到代理服务器上,代理服务器再发送给我们的电脑。在这种情况下,只要我们的电脑和代理服务器的连接是合理快速的,代理服务器和网站服务器的连接是顺畅快速的,通过代理服务器往往就可以加速我们访问目标网页的速度,甚至我们可以访问到一些我们之前无法访问的网页内容。
那么,如何通过python访问代理服务器呢??
#使用urllib.request的两个方法进行代理的设置
proxy = urlrequest.ProxyHandler({'https': '47.91.78.201:3128'})
opener = urlrequest.build_opener(proxy)代理服务器的存在,可以应对网站禁止某个IP访问的反爬虫措施,代理服务器有着不同的匿名类型,通常我们会挑选中、高级别的代理服务器来访问网页。(使用低级别的是没有用的,网站还是能够知道我们的真实IP,对于我们的爬取时没有任何帮助的,因为它还是能够封掉我们的真实IP)

3.设定User-Agent
网站是可以识别我们是否在使用Python进行爬取,需要我们在发送网络请求时,把header部分伪装成浏览器。
opener.addheaders = [('User-Agent','...')]
用不同浏览器访问的header字符串,放入上述代码省略号的部分即可。
常用的浏览器header有:
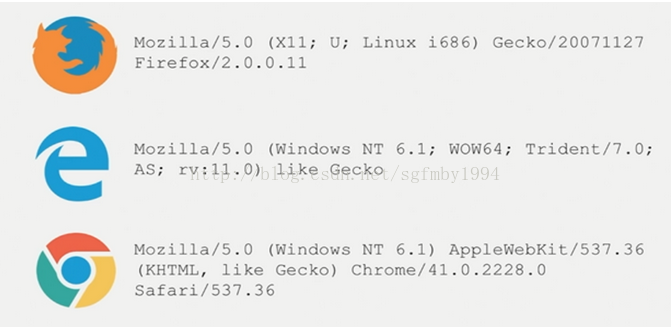
网上查看还有这些:
1.QQ浏览器: Mozilla/5.0 (compatible; MSIE 10.0; WindowsNT6.1; WOW64; Trident/6.0; QQBrowser/7.7.24962.400) (我在代码中用的是这个)
2. IE浏览器:Mozilla/5.0(compatible; MSIE 10.0;Windows NT 6.1; WOW64; Trident/6.0)
示例:Place PulseGoogle街景图爬取
这是MIT的学术项目,爬取不同城市的街景地图,然后让人去手工标注图片中的城市哪个更安全,更有趣等等。
举个例子,下面这两个城市的图景。如果认为左边更好的话,就点击左边的城市,如果认为差不多的话就点击等号,
如果认为右边更好的话,就点击右边的城市。
MIT会统计这些标注结果。
这个数据集是这样的:(左边城市是什么,右边城市是什么,某人的打分)
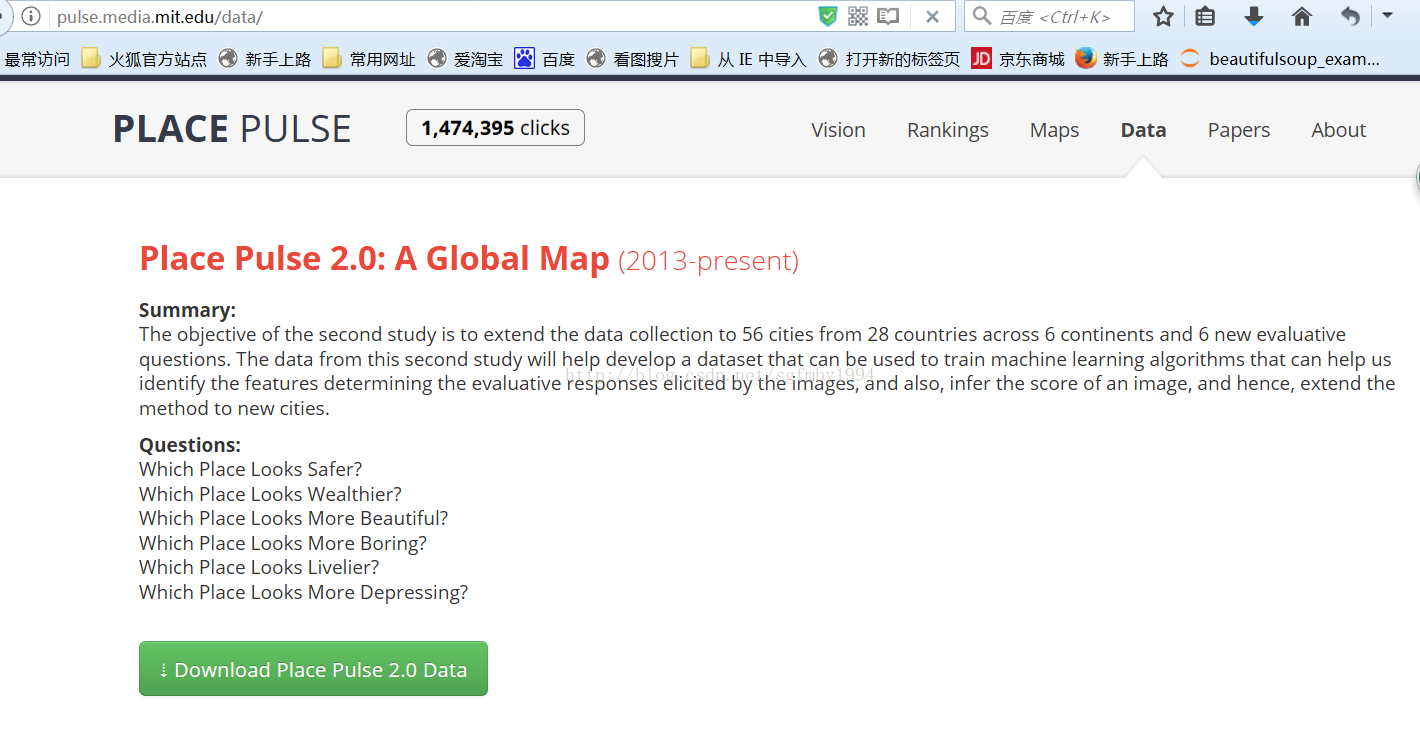
下载下来:

结构:
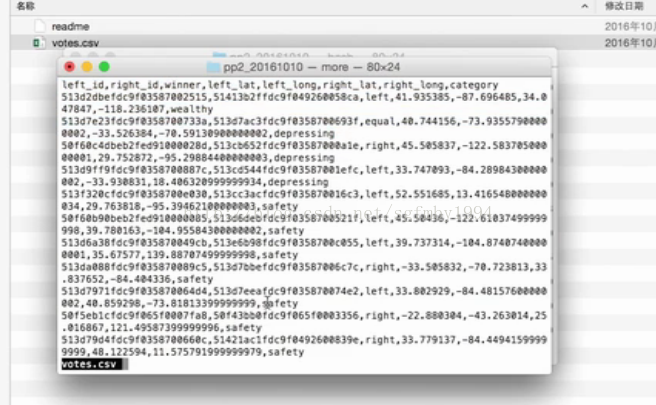
逗号来分隔每一个属性里面的值
核心任务:
把对应每一个图片ID的谷歌街景图片,根据它告诉我们的这个图片所在的GPS的经纬度的位置,利用readme中看到的google map的api,把这个图片下载下来。
代码及注释:
# coding=utf-8
import urllib.request as urlrequest
import time
import random
# 1.准备工作:载入包,定义存储目录,连接API
IMG_PATH = './imgs/{}.jpg' # 最终会把下载的图片存到这个目录下面
DATA_FILE = './data/votes.csv'
# 记录一下已经下载了哪些图片,把图片id放在里面,这样如果下载中止也能知道哪些已经下载了,
# 这样在下载一个图片之前,我们可以先判断一下这个图片的id是否在这个文件中有,如果有,就不用再下载了。
STORED_IMG_ID_FILE = './data/cached_img.txt'
STORED_IMG_IDS = set() # 把已经下载的图片的id放在一个集合里面
# readme中提到的google针对下载街景地图的api
# 我们需要修改的是location,即经纬度
IMG_URL = 'https://maps.googleapis.com/maps/api/streetview?size=400x300&location={},{}'
# 2.应用爬虫技巧:使用代理服务器、User-Agent
# 根据网上找到的代理服务器来更新一下,因为代理服务器可以运行的时间也是有限制的
proxy = urlrequest.ProxyHandler({'https': '173.213.108.111:3128'}) # 设置代理服务器的地址
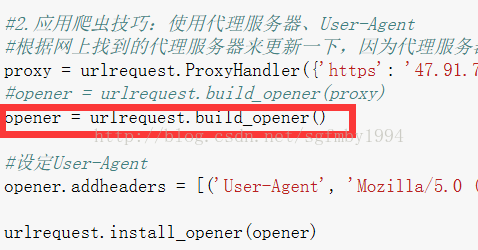
#opener = urlrequest.build_opener(proxy)
opener = urlrequest.build_opener()
# 设定User-Agent
opener.addheaders = [('User-Agent',
'Mozilla/5.0 (compatible; MSIE 10.0; WindowsNT 6.1; WOW64; Trident/6.0; QQBrowser/7.7.24962.400) ')]
urlrequest.install_opener(opener)
# 3.读取图片的id
with open(STORED_IMG_ID_FILE) as input_file:
for line in input_file:
STORED_IMG_IDS.add(line.strip())
# 4.根据提供的votes.csv,进行google街景图片的爬取
with open(DATA_FILE) as input_file: # 读取votes.csv
skip_first_line = True
for line in input_file:
if skip_first_line: # 因为第一行是属性行,所以跳过
skip_first_line = False
continue
# 根据逗号就行拆分成各个属性(这些属性在readme中可以看到)
left_id, right_id, winner, left_lat, left_long, right_lat, right_long, category = line.split(',')
# 针对左边的图片
if left_id not in STORED_IMG_IDS: # 如果左边的图片还没有下载
print('saving img {}...'.format(left_id))
urlrequest.urlretrieve(IMG_URL.format(left_lat, left_long), IMG_PATH.format(left_id)) # 文件命名为这个图片的id
STORED_IMG_IDS.add(left_id) # 把已经下载的图片的id加进集合中
with open(STORED_IMG_ID_FILE, 'a') as output_file: # 把已经下载的图片的id新添加进cached_img.txt中
output_file.write('{}\n'.format(left_id))
time_interval = random.uniform(1, 5)
time.sleep(time_interval) # wait some time, trying to avoid google forbidden (of crawler)
# 针对右边的图片
if right_id not in STORED_IMG_IDS:
print('saving img {}...'.format(right_id))
urlrequest.urlretrieve(IMG_URL.format(right_lat, right_long), IMG_PATH.format(right_id))
STORED_IMG_IDS.add(right_id)
with open(STORED_IMG_ID_FILE, 'a') as output_file:
output_file.write('{}\n'.format(right_id))
time_interval = random.uniform(1, 5)
time.sleep(time_interval) # wait some time, trying to avoid google forbidden (of crawler)
国外服务器的代理地址,可以在 http://www.kuaidaili.com/free/outha/这个网站中找到。
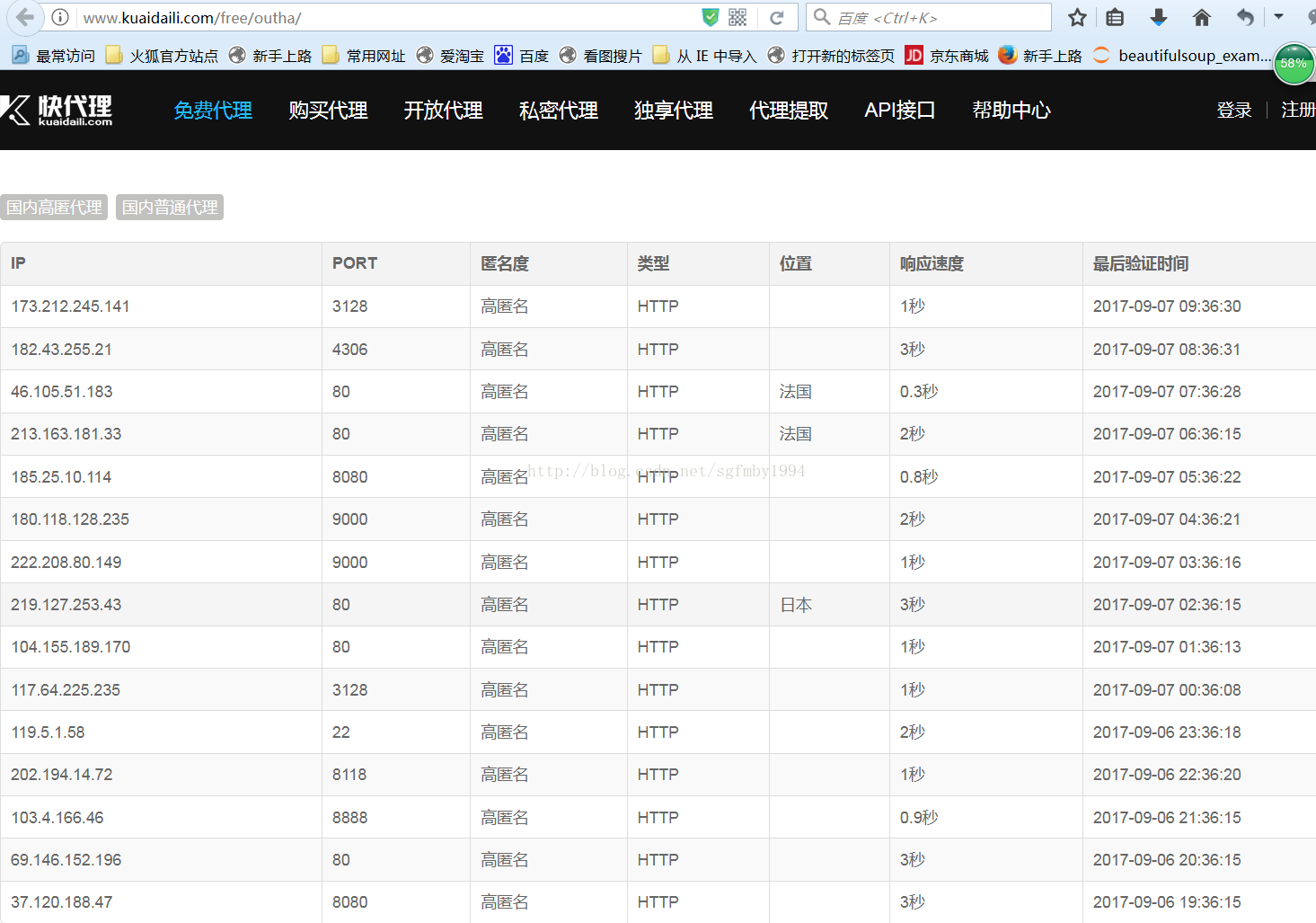
可以看到每个地址对应ip地址所在的国家,匿名的程度等等。
这里需要注意我们不能使用低级(Transparent)代理。
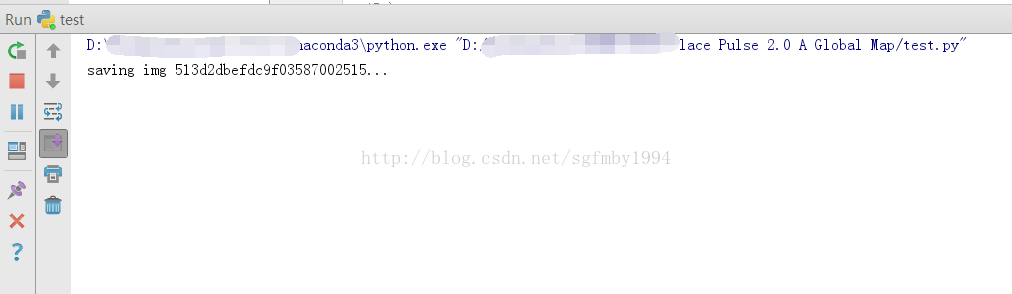
先来运行不使用代理服务器的程序:
速度很慢,存储不动,google在大陆访问起来还是比较困难的。
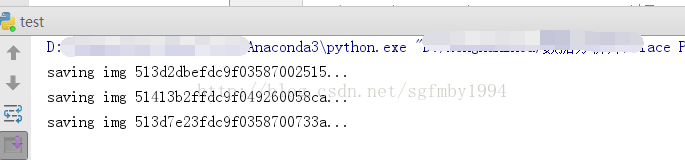
运行设置代理服务器的程序:

可以顺利进行,这说明我们成功连接到了代理的一个服务器上,再通过这个代理服务器连接到了google上。
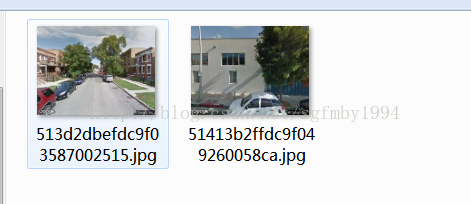
在文件夹里可以查看到我们从googlemap中下载到的图片以及图片的id。














 7066
7066











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









