






Just three months ago, the WebKit team announced SquirrelFish, a major revamp of our JavaScript engine featuring a high-performance bytecode interpreter. Today we’d like to announce the next generation of our JavaScript engine - SquirrelFish Extreme (or SFX for short). SquirrelFish Extreme uses more advanced techniques, including fast native code generation, to deliver even more JavaScript performance.
For those of you who follow WebKit development and are interested in contributing, we’d like to report our results and what we did to achieve them.
How Fast is It?
This chart shows WebKit’s JavaScript performance in different versions - bigger bars are better.
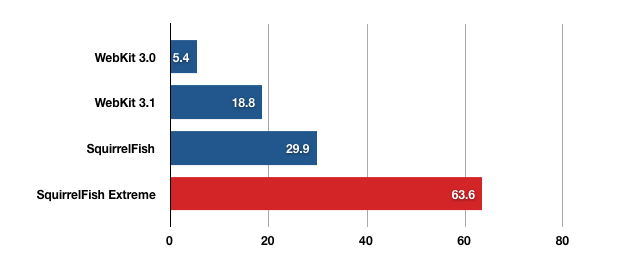
The metric is SunSpider runs per minute. We present charts this way because “bigger is better” is easier to follow when you have a wide range of performance results. As you can see, SquirrelFish Extreme as of today is more than twice as fast as the original SquirrelFish, and over 10 times the speed you saw in Safari 3.0, less than a year ago. We are pretty pleased with this improvement, but we believe there is more performance still to come.
Quite a few people contributed to these results. I will mention a few who worked on some key tasks, but I’d also like to thank all of the many WebKit contributors who have helped with JavaScript and performance.
What makes it so fast?
SquirrelFish Extreme uses four different technologies to deliver much better performance than the original SquirrelFish: bytecode optimizations, polymorphic inline caching, a lightweight “context threaded” JIT compiler, and a new regular expression engine that uses our JIT infrastructure.
1. Bytecode Optimizations
When we first announced SquirrelFish, we mentioned that we thought that the basic design had lots of room for improvement from optimizations at the bytecode level. Thanks to hard work by Oliver Hunt, Geoff Garen, Cameron Zwarich, myself and others, we implemented lots of effective optimizations at the bytecode level.
One of the things we did was to optimize within opcodes. Many JavaScript operations are highly polymorphic - they have different behavior in lots of different cases. Just by checking for the most common and fastest cases first, you can speed up JavaScript programs quite a bit.
In addition, we’ve improved the bytecode instruction set, and built optimizations that take advantage of these improvements. We’ve added combo instructions, peephole optimizations, faster handling of constants and some specialized opcodes for common cases of general operations.
2. Polymorphic Inline Cache
One of our most exciting new optimizations in SquirrelFish Extreme is a polymorphic inline cache. This is an old technique originally developed for the Self language, which other JavaScript engines have used to good effect.
Here is the basic idea: JavaScript is an incredibly dynamic language by design. But in most programs, many objects are actually used in a way that resembles more structured object-oriented classes. For example, many JavaScript libraries are designed to use objects with “x” and “y” properties, and only those properties, to represent points. We can use this knowledge to optimize the case where many objects have the same underlying structure - as people in the dynamic language community say, “you can cheat as long as you don’t get caught”.
So how exactly do we cheat? We detect when objects actually have the same underlying structure — the same properties in the same order — and associate them with a structure identifier, or StructureID. Whenever a property access is performed, we do the usual hash lookup (using our highly optimized hashtables) the first time, and record the StructureID and the offset where the property was found. Subsequent times, we check for a match on the StructureID - usually the same piece of code will be working on objects of the same structure. If we get a hit, we can use the cached offset to perform the lookup in only a few machine instructions, which is much faster than hashing.
Here is the classic Self paper that describes the original technique. You can look at Geoff’s implementation of the StructureID class in Subversion to see more details of how we did it.
We’ve only taken the first steps on polymorphic inline caching. We have lots of ideas on how to improve the technique to get even more speed. But already, you’ll see a huge difference on performance tests where the bottleneck is object property access.
3. Context Threaded JIT
Another major change we’ve made with SFX is to introduce native code generation. Our starting point is a technique called a “context threaded interpreter”, which is a bit of a misnomer, because this is actually a simple but effective form of JIT compiler. In the original SquirrelFish announcement, we described our use of direct threading, which is about the fastest form of bytecode intepretation short of generating native code. Context threading takes the next step and introduces some native code generation.
The basic idea of context threading is to convert bytecode to native code, one opcode at a time. Complex opcodes are converted to function calls into the language runtime. Simple opcodes, or in some cases the common fast paths of otherwise complex opcodes, are inlined directly into the native code stream. This has two major advantages. First, the control flow between opcodes is directly exposed to the CPU as straight line code, so much dispatch overhead is removed. Second, many branches that were formerly inside opcode implmentations are now inline, and made visible and highly predictable to the CPU’s branch predictor.
Here is a paper describing the basic idea of context threading. Our initial prototype of context threading was created by Gavin Barraclough. Several of us helped him polish it and tune the performance over the past few weeks.
One of the great things about our lightweight JIT is that there’s only about 4,000 lines of code involved in native code generation. All the other code remains cross platform. It’s also surprisingly hackable. If you thought compiling to native code is rocket science, think again. Besides Gavin, most of us have little prior experience with native codegen, but we were able to jump right in.
Currently the code is limited to x86 32-bit, but we plan to refactor and add support for more CPU architectures. CPUs that are not yet supported by the JIT can still use the interpreter. We also think we can get a lot more speedups out of the JIT through techniques such as type specialization, better register allocation and liveness analysis. The SquirrelFish bytecode is a good representation for making many of these kinds of transforms.
4. Regular Expression JIT
As we built the basic JIT infrastructure for the main JavaScript language, we found that we could easily apply it to regular expressions as well, and get up to a 5x speedup on regular expression matching. So we went ahead and did that. Not all code spends a bunch of time in regexps, but with the speed of our new regular expression engine, WREC (the WebKit Regular Expression Compiler), you can write the kind of text processing code you’d want to do in Perl or Python or Ruby, and do it in JavaScript instead. In fact we believe that in many cases our regular expression engine will beat the highly tuned regexp processing in those other languages.
Since the SunSpider JavaScript benchmark has a fair amount of regexp content, some may feel that developing a regexp JIT is an “unfair” advantage. A year ago, regexp processing was a fairly small part of the test, but JS engines have improved in other areas a lot more than on regexps. For example, most of the individual tests on SunSpider have gotten 5-10x faster in JavaScriptCore — in some cases over 70x faster than the Safari 3.0 version of WebKit. But until recently, regexp performance hadn’t improved much at all.
We thought that making regular expressions fast was a better thing to do than changing the benchmark. A lot of real tasks on the web involve a lot of regexp processing. After all, fundamental tasks on the web, like JSON validation and parsing, depend on regular expressions. And emerging technologies — like John Resig’s processing.js library — extend that dependency ever further.














 115
115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









