







YOLO9000
原文为Joseph Redmon与Ali Farhadi的文章“YOLO9000: Better, Faster, Stronger”。本想总结一下,看完发现整篇文章多余的话有点少。YOLO的实时性众所周知,所以还等什么,皮皮虾我们走~
摘要
多尺度训练YOLOv2;权衡速度和准确率,运行在不同大小图像上。YOLOv2测试VOC 2007 数据集: 67 FPS时, 76.8 mAP; 40 FPS时, 78.6 mAP。
联合训练物体检测和分类,可检测未标签检测数据的物体的类别。ImageNet检测验证集上,YOLO9000仅用 200 类中的 44 类检测数据获得 19.7 mAP;对COCO中缺少的 156 类检测数据获得 16.0 mAP。

1. 简介
神经网络引入后,检测框架变得更快更准确。然而,大多数检测方法受限于少量物体。相比分类和加标签等其它任务的数据集,目前物体检测的数据集有限。
将检测扩展到分类层面。然而,标注检测图像相比其它任务更加昂贵。因此,提出新方法扩展目前检测系统的范围。对物体分类的分层视图可合并不同的数据集。
检测和训练数据上联合训练物体检测器,用有标签的检测图像来学习精确定位,同时用分类图像来增加词汇和鲁棒性。
原YOLO系统上生成YOLOv2检测器;在ImageNet中超过 9000 类的数据和COCO的检测数据上,合并数据集和联合训练YOLO9000。
2. 更好
相比Fast R-CNN对YOLO误差分析,显示YOLO有显著的定位误差。YOLO与其它基于区域建议的方法召回率相对较低。因此,保持分类准确率的同时,着重改善召回率和定位。
计算机视觉一般倾向更大更深的模型。训练更大网络或集成多个模型通常会有更好的效果。然而,我们希望YOLOv2检测器保留速度的同时更加精确,因此,简化网络来易于学习表示。结果见表 2 。
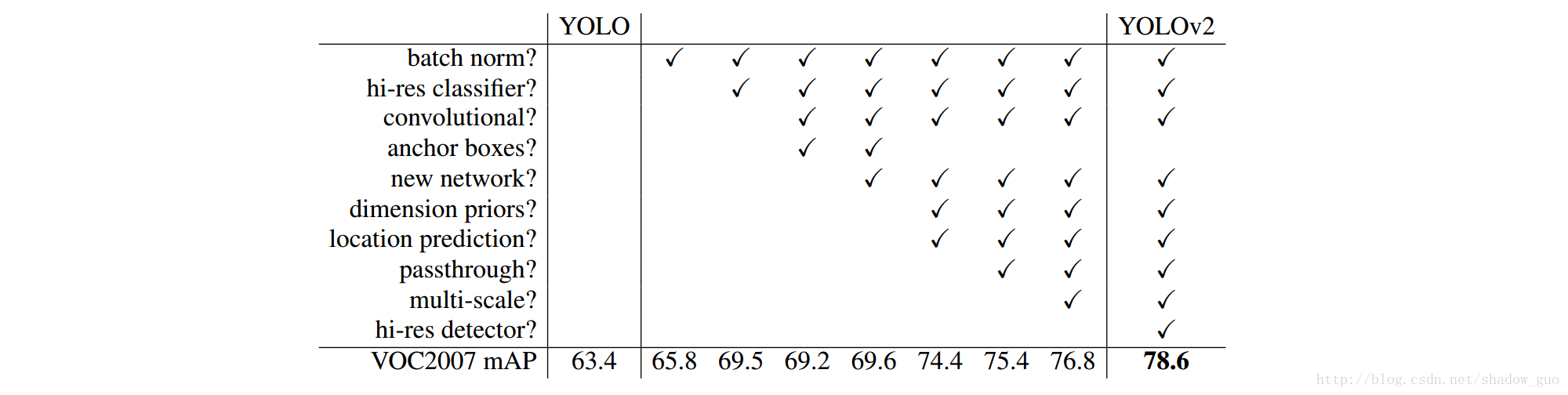
2.1 块归一化(Batch Normalization)
无需其它形式的正则,块归一化收敛时显著变好。块归一化有助于模型正则,可从未过拟合的模型中删除dropout。YOLO上所有卷积层上添加块归一化,mAP提高
2.2 分类器输入更高分辨率
所有领先的检测方法都使用ImageNet上预训练好的分类器。从AlexNet起,大多分类器的输入图像分辨率都小于
256×256
。
- 原YOLO:
224×224
大小的图像上训练分类器,检测时分辨率提高至448。网络须同时切换至学习物体检测,并调整至新的输入分辨率。
- YOLOv2:ImageNet上按
448×448
分辨率,微调分类网络
10
个周期(epochs);检测数据上微调网络。高分辨率的分类网络使mAP提高
4
%。
2.3 用锚箱(Anchor Boxes)的卷积
YOLO用卷积特征提取器顶部的全连接层来直接预测边界框的坐标。
Faster R-CNN用精心挑选的先验来预测边界框。Faster R-CNN中的区域建议网络(RPN)仅用卷积层直接预测锚箱的偏移和置信度。因预测层为卷积层,RPN预测特征图中每个位置上锚箱的偏移。
预测偏移而非坐标,简化了问题,且使网络更易学。
删除YOLO的全连接层,用锚箱预测边界框:删除一池化层使网络卷积层的输出有更高的分辨率。将网络输入图像的分辨率从
输入图像分辨率为
416×416
,YOLO卷积层按
32
倍数下采样图像,输出特征图大小为
13×13
。
锚箱的使用从空间位置中解耦出类别预测,并预测每个锚箱的类别和物体(objectness):
- 物体预测:同YOLO,仍为预测建议框与真实框的IOU;
- 类别预测:给定已存在物体,预测该类的条件概率。
使用锚箱,准确度略降。YOLO对每幅图仅预测98个建议框,而用锚箱模型可预测上千个建议框。无锚箱时的中间模型得 69.5 mAP和 81 %召回率;有锚箱时的模型得 69.2 mAP和 88 %召回率。mAP略减,但召回率的提高说明模型仍可能改进。
2.4 维度聚类
YOLO中用锚箱会碰到两个问题。第1个问题:锚箱的维度为手动挑选,网络可学习合适地调整锚箱,但为网络挑选更好的先验能更容易学到更好的检测器。
训练集边界框上用K-means聚类来自动找好的先验:用标准K-means(欧几里德距离)时,更大的边界框会产生更大的误差。而获得好的IOU分数的先验应与建议框的大小无关。因此,使用如下距离测量:
选多个k值,画出最近中心的平均IOU,如下图。权衡模型复杂度和高召回率,选择 k=5 。聚类的中心与手动挑选的锚箱明显不同, 窄长的边界框更多。
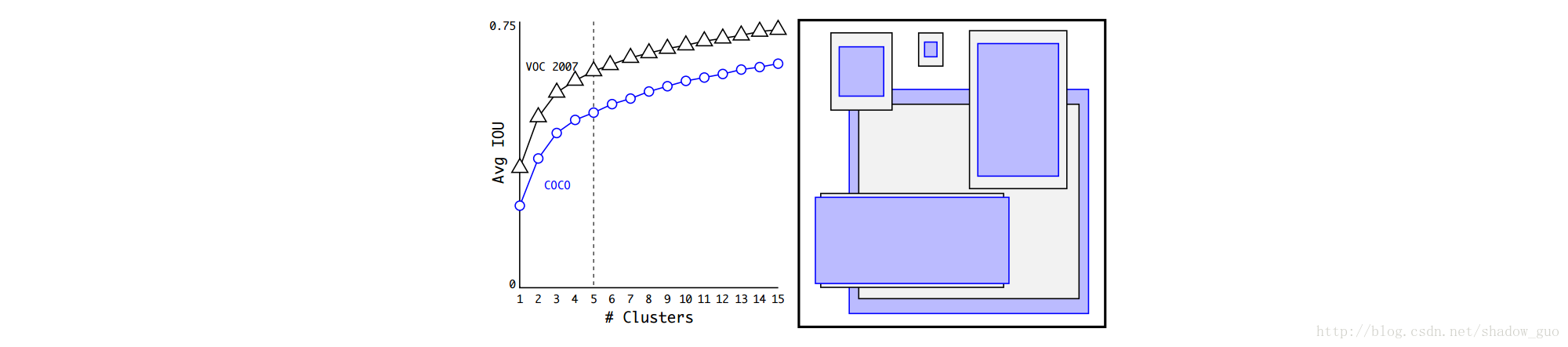
比较表1中聚类策略的最近先验与手动挑选的锚箱的平均IOU。
5
个先验中心(
K-means生成的边界框有更好的表示,任务更易学。

2.5 直接预测位置
YOLO中用锚箱时遇到的第2个问题:模型不稳定,尤其是早期迭代时。大多不稳定来自预测锚箱的位置
(x,y)
。区域建议网络预测值
tx
和
ty
,中心坐标
(x,y)
计算如下:
如, tx=1 时, x=wa+xa ,预测的位置右移一个锚箱宽度; tx=−1 时, x=xa−wa ,预测的位置左移相同的宽度。
该公式无约束,使锚箱可到达图像中任意位置。随机初始化的模型要花很长时间稳定,才可预测出合理的偏移。
除了预测偏移,同YOLO一样,预测相对网格单元的位置坐标。真实边界框的位置范围落入 [0,1] 之间。Logistic激活约束网络预测落入该范围。
对输出特征图中的每个单元,网络预测
5
个边界框。网络预测每个边界框的
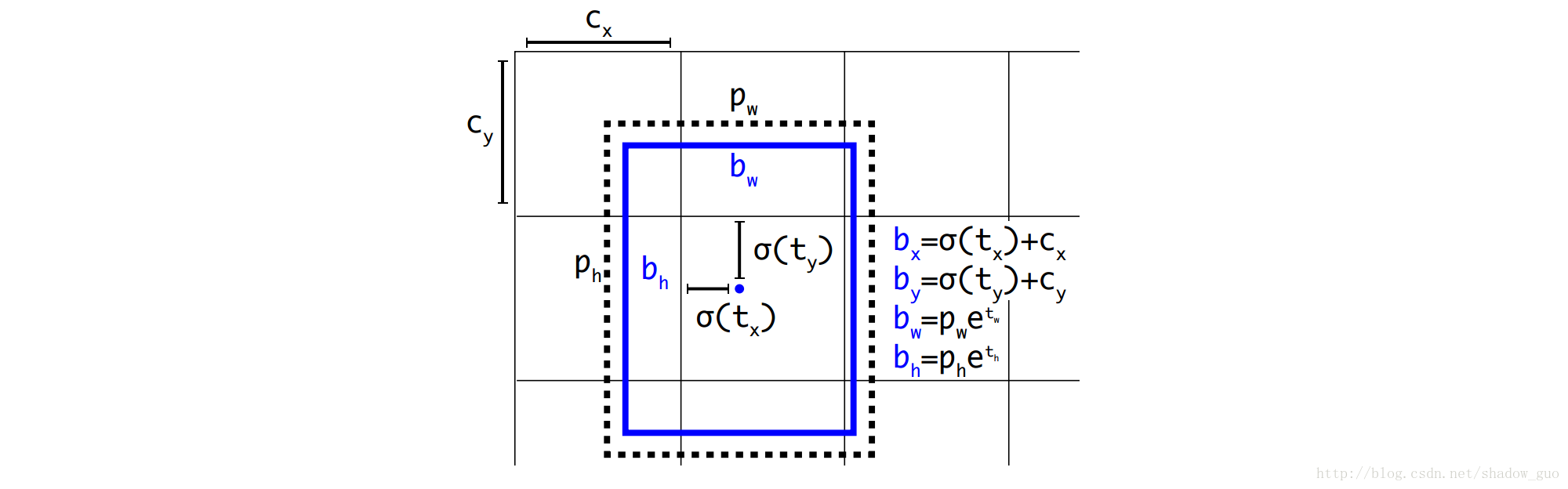
约束位置预测更易学参数化,使网络更稳定。带直接预测边界框的中心位置聚类相比带锚箱的中心位置聚类提高近 5 %。
2.6 细粒度特征
更改后的YOLO在
类似残差网络的恒等映射,穿越层堆叠相邻特征至不同的通道(而非空间位置)来关联高分辨率特征和低分辨率特征。此时关联原有的特征, 26×26×512 个特征图变为 13×13×2048 个特征图。扩展的特征图上运行的检测器有更精细的特征,性能提高 1 %。
2.7 多尺度训练
原YOLO的输入分辨率为
每隔几次迭代改变网络结构:每 10 个图像块,网络会选择新的图像大小。因网络下采样因子为 32 : {320,352,...608} 。因此,可选的最小分辨率为 320×320 ,且最大分辨率为 608×608 。缩放网络至相应维度,继续训练。
缩放网络至不同的维度:对图像输入分辨率最大时的网络,每个卷积层输出的特征图维度固定。所以,对不同分辨率的图像,应是优先保留顶层的权重,底层的卷积层用相同分辨率的输入图像替换来完成训练,同时屏蔽高于输入图像分辨率的卷积层。
输入
288×288
大小的图像时,YOLOv2的mAP接近Fast R-CNN的mAP时,运行速度超过
90
FPS;输入高分辨率的图像时,YOLOv2实时运行,且在VOC 2007上的mAP为
78.6
。YOLOv2与VOC 2007上其他框架的比较见表
3
和图
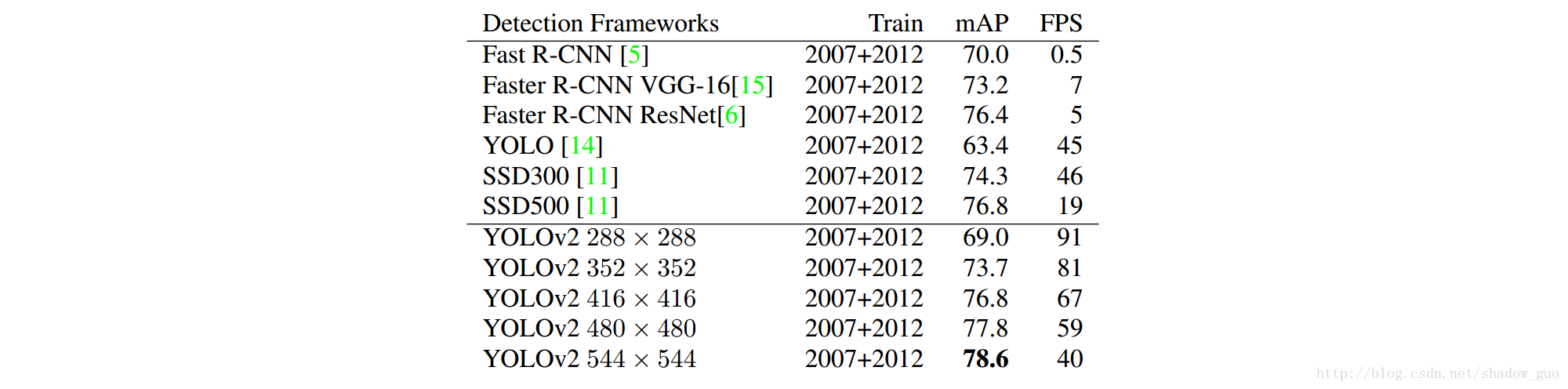
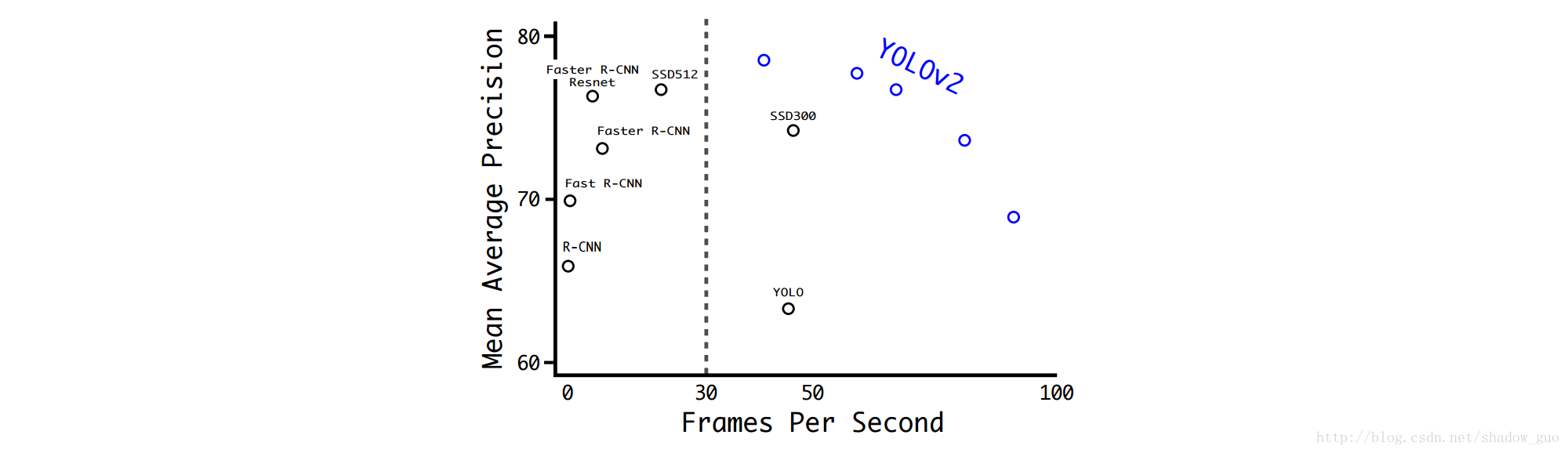
2.8 更多实验
VOC 2007+2012上,YOLOv2运行快过其它方法,mAP为
73.4
,见表
4
;COCO上,YOLOv2的mAP为


3. 更快
大多检测框架基于VGG-16来提取特征。VGG-16网络分类强大准确,但却不必要的复杂。VGG-16的卷积层在单幅
YOLO框架基于Googlenet结构,快过VGG-16,
1
次传递仅用
3.1 Darknet-19
类似VGG模型,大多用 3×3 的滤波器且每次池化通道数加一倍。按Network in Network用全局平均池化预测和 1×1 大小的滤波器来压缩 3×3 大小卷积间的特征表示。块归一化来稳定训练,加快收敛和正则化模型。
最终的模型 Darknet-19有
19
个卷积层和
5
个池化层,见表
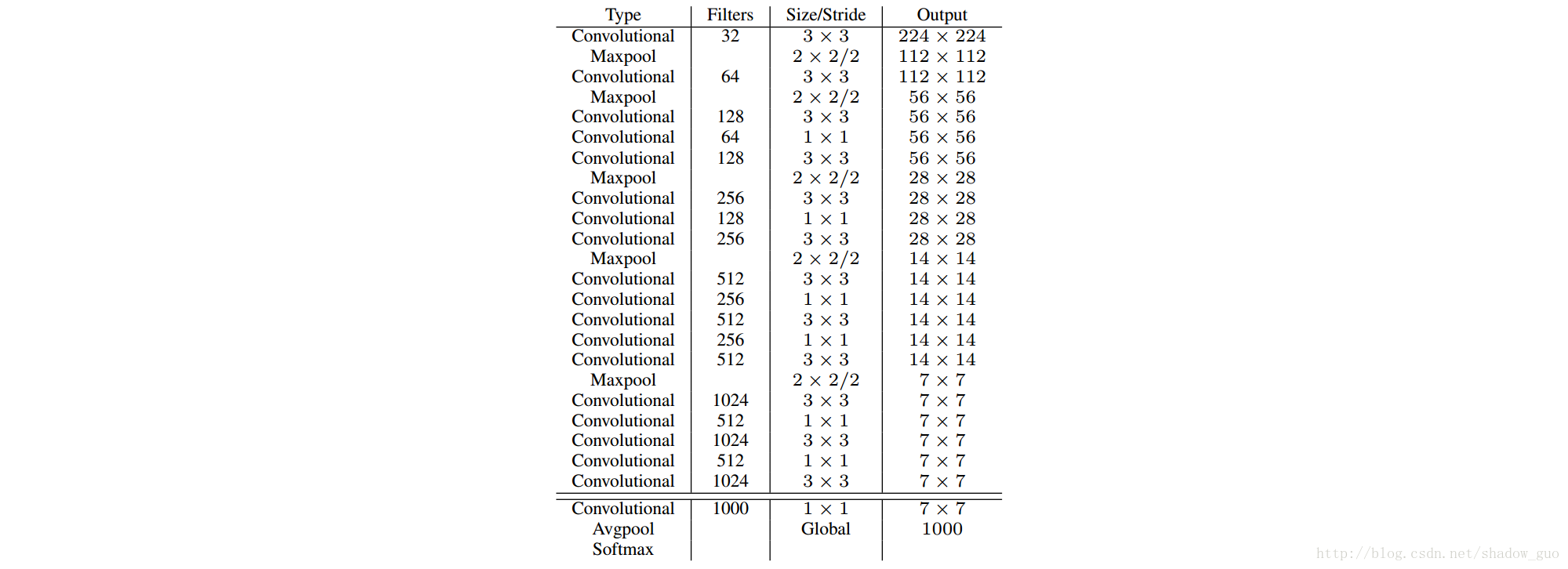
3.2 分类训练
标准Imagenet 分类数据集(1000类)上训练网络
160
个周期(epoch)。训练Darknet网络框架:学习率为
0.1
,多项式速率衰减(?)的幂为
4
,权重衰减为
224×224
大小图像上开始训练,
448×448
大小图像上微调。微调时用初始的参数。仅
10
步训练后,学习率用
10−3
微调。更高分辨率上网络的top-1和top-5准确率为
76.5
%和
93.3
%。
3.3 检测训练
删除最后一卷积层,不用
3
个
训练网络时的初始学习率为
4. 更强
联合训练检测和分类。检测时用有标签图像来预测边界框坐标,物体(objectness)和分类日常物体。用有类标签的图像来扩展可检测的类数目。
训练检测时,基于整个YOLOv2损失函数来反向传播;训练分类时,仅用网络结构中的分类部分来反传损失。
联合训练的挑战:检测数据集只有日常物体和一般的标签,如“狗”或“船”;分类数据集标签的范围更广更深。 Imagenet有上千种狗,如“诺福克梗犬”,“约克郡犬”和“贝得灵顿厚毛犬”等。所以,训练两个数据集时,须合并标签。
大多方法对所有可能的类别用 1 个softmax层来计算最后的概率分布。用softmax时假设类间互斥。合并数据集出现的问题:“诺福克梗犬”和“狗”类不互斥。
4.1 分层分类
Imagenet的标签取自WordNet(排列概念及其关联的语言数据库)。WordNet中,“诺福克梗犬”和“约克郡犬”为“小猎狗”的难判名,“小猎狗”为“狗”的一类,是“犬科动物”。大多方法却用扁平的标签结构。
WordNet的结构为有向图,而非树。如,“狗”是“犬科动物”类和“家畜”类,两者为WordNet中的同义词集。为简化问题,不用完整的图结构,仅用Imagenet中的概念来搭建分层树。
为搭建分层树,检查Imagenet中的视觉名词,从WordNet图至根节点(“物体”)寻找这些名词的路径。图中很多同义词集仅有
最终得到WordTree,视觉名词的分层模型。用WordTree分类时,给定同义词集,预测每个节点的条件概率来获得该词集中每个难判名的概率。如,“小猎狗(terrier)”节点上预测:
沿特定节点至树的根节点,乘以路径上的条件概率,即可计算该特定节点上的绝对概率。如,计算图中为“约克郡犬”的绝对概率:
分类时,假设图中包含物体: Pr(physical object)=1 。
1000
类Imagenet上搭WordTree,训练Darknet-19模型。搭建WordTree1k时,添加所有中间节点,标签空间从
1000
扩展至
1369
。训练时传递标签,真实标签传递至树的上层节点。若图像标签为“诺福克梗犬”,该图像也应标为“狗”和“哺乳动物”等。为计算条件概率,模型预测
1369
值的
1
个向量,计算所有相同概念下难判名的同义词集的softmax,见图
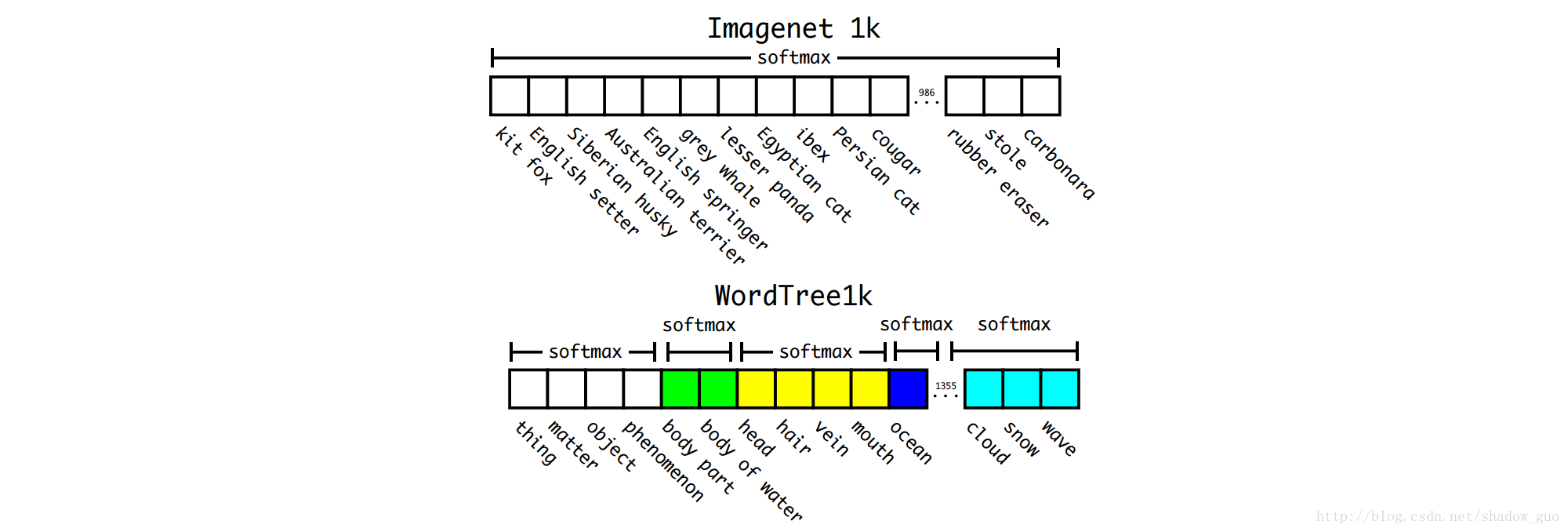
WordTree向量中,除根节点为“physical object”,从左向右名词描述得越来越具体,从而使难判名的同义词集会集中在向量的某段,便于每个softmax的连接。
用与之前相同的训练参数,分层Draknet-19的top-1和top-5准确率分别为 71.9 %和 90.4 %。尽管添加了额外的 369 个概念,并用网络预测树结构,但准确率仅略降。如此分类使新的或未知类上的表现平稳降低。如,网络看到狗,但不确定为哪种狗,此时网络仍会以高置信度来预测狗,但各难判名间的置信度会更低。
该表述同样使用于检测。分类时,假设每幅图会包含
1
个物体;但检测时,YOLOv2物体检测器要给出
4.2 与词数(WordTree)结合的数据集
用WordTree合并Imagenet与COCO的标签,见图
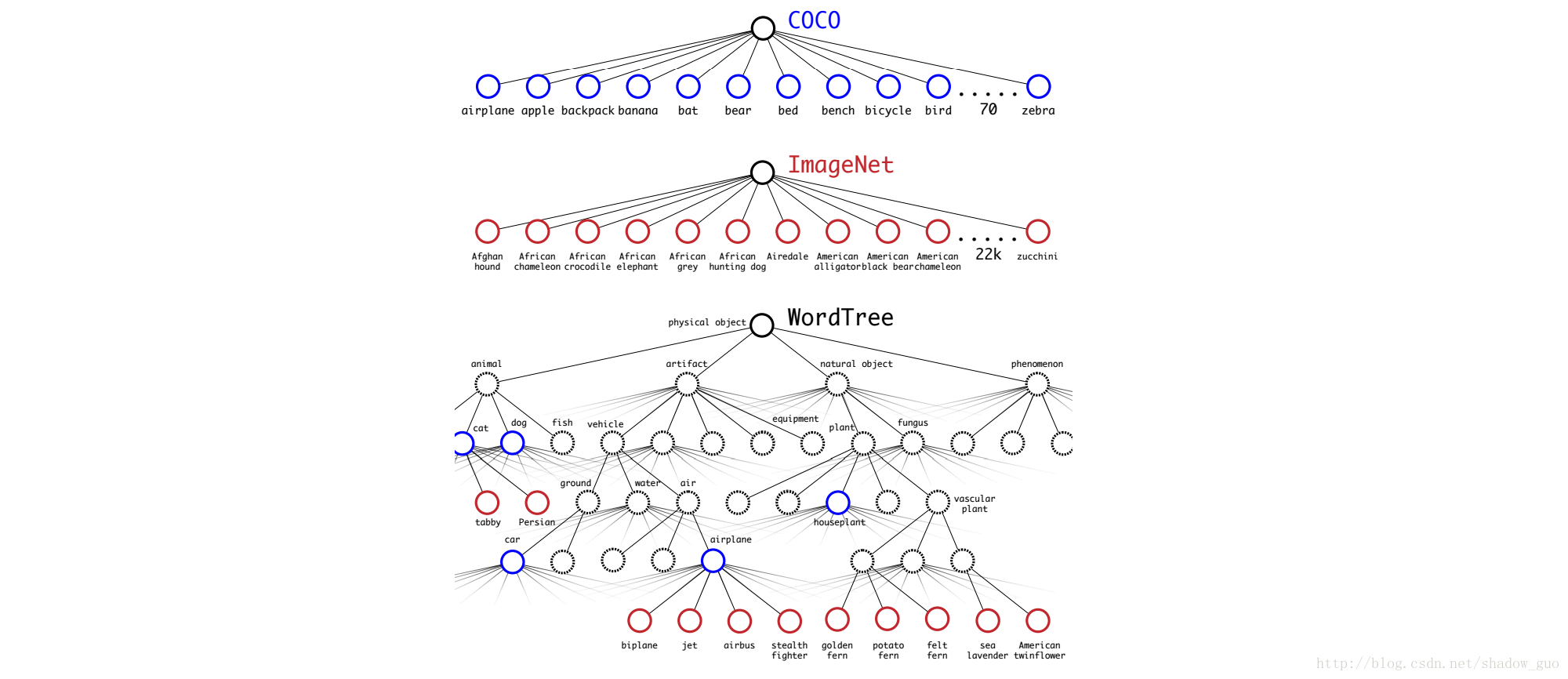
4.3 联合分类与检测
用合并的数据集来联合训练分类和检测模型。为训练极大规模的检测器,合并COCO检测数据集和整个Imagenet的前 9000 类标签,创建出新的数据集。合并后数据集的WordTree有 9418 类。Imagenet为更大的数据集,所以,过采样COCO来平衡合并的数据集,此时,Imagenet大小为过采样COCO的 4 倍。
合并数据集训练YOLO9000。用基YOLOv2结构,但改为
分类时,网络仅反传分类损失。假设预测框与真实标签框的IOU大于
Imagenet检测任务与COCO共享 44 个物体类,所以YOLO9000只能看到大多测试图像的分类数据,而非检测数据。YOLO9000的总体mAP为 19.7 ,未知的 156 物体类上的mAP为 16.0 。该mAP高于DPM,且仅用部分监督(partial supervision)在不同数据集上训练YOLO9000。同时实时检测9000类物体。
分析Imagenet上YOLO9000的表现,发现它很好地学到新动物物种(与COCO中动物类有很好的泛化),但衣物和设备等类学习困难(COCO无对人的衣物类标签,难学到“太阳镜”或“泳裤”),见表 7 <script type="math/tex" id="MathJax-Element-154">7</script>。

YOLO9000的表现换一解释。前面提到,检测器用来检测物体(objectness),分类器用于分类对象(object)类别。训练检测器时,网络会将COCO中所包含的对象类视为物体,但COCO的对象标签不包括衣物和设备,所以,YOLO9000自然不会轻易把衣物或设备等对象视为物体。
作者实验的目的是:验证合并了COCO检测数据集和Imagenet分类数据集后,模型在Imagenet检测数据集上的效果。省去标定巨大的检测数据集的高昂成本,利用有限的检测数据集和巨大的分类数据集来完成巨大的检测数据集上的检测任务。
5. 小结
“更好”和“更快”部分可能并不会有多大影响,毕竟那些小技巧改善的效果有限。但“更强”部分现实意义很强啊,真是有意思~
全文未经校正,有问题欢迎指出。















 580
580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









