







一、 集合框架中的接口
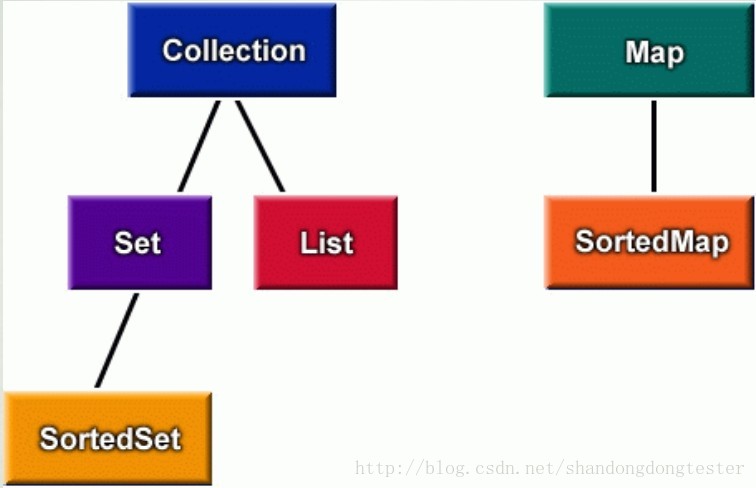
所谓框架就是一个类库的集合。集合框架就是一个用来表示和操作集合的统一的架构,包含了实现集合的接口与类。
二、List接口主要有2个实现类:ArrayList、LinkedList
·ArrayList
1. ArrayList 底层采用数组实现,但是用不带参数的构造方法生产 ArrayList 对象时,实际上会在底层生成一个长度为 10 的 Object 类型的数组。 如果增加的元素超过10个,那么ArrayList底层会新生成一个数组,长度为原数组的1.5倍+1,然后将原数组的内容复制到新数组当中,并且后续增加的内容都会放到新数组当中。当新数组无法容纳增加的元素时,重复该过程。
2. 对于 ArrayList 元素的删除操作,需要将被删除元素的后续元素向前移动,代价比较高。
3. 集合当中只能放置对象的引用,无法放置原生数据类型,我们需要使用原生数据类型的包装类才能加入到集合当中。
4. 集合当中放置的都是 Object 类型,因此取出来的也是 Object 类型,那么必须要使用强制类型转换将其转换为真正的类型(放置进去的类型)。
·LinkedList
1. LinkedList 底层主要由双向链表实现。
2. 添加数据:LinkedList list = new LinkedList(); list.add("elements");
当向 ArrayList 添加啊一个对象时,实际上就是将该对象放置到了 ArrayList 底层所维护的数组当中;当向 LinkedList 中添加一个对象时,实际上 LinkedList 内部会生成一个Entry 对象,该 Entry 对象的结构为:
// Entry类的伪代码
Entry{
Entry prevoius;
Object element;
Entry next;
}
Entry entry = new Entry();
entry.element = "elements";
list.add(entry);
· 关于ArrayList 与 LinkedList 的比较分析:
a) ArrayList 底层采用数组实现,LInkedList 底层采用双向链表实现。
b) 当执行插入或者删除操作时,采用 LinkedList 比较好。
c) 当执行搜索操作时,采用 ArrayLIst 比较好。
三、 Set 接口
Set的特点:1. 是无序的、没有重复的。
set接口实现类常用的是HashSet。
package com.bob.set;
import java.util.HashSet;
public class SetTest2 {
public static void main(String[] args) {
// TODO Auto-generated method stub
HashSet set = new HashSet();
/*
set.add(new People("zhangsan"));
set.add(new People("lisi"));
set.add(new People("zhangsan"));
People p1 = new People("zhangsan");
set.add(p1);
set.add(p1);
*/
String s1 = new String("a");
String s2 = new String("a");
set.add(s1);
set.add(s2);
System.out.println(set);
}
}
class People{
String name;
public People(String name){
this.name = name;
}
}
1. 关于 Object 类的 equals 方法的特点(Object 的 equals 方法是比较两个对象是否相等)。
在一个非空的对象引用上它实现一个相等性的关系,它满足以下条件:
a) 自反性:x.equals(x)应该返回 trueb) 对称性:x.equals(y)为 true,那么 y.equals(x)也为 true。
c) 传递性:x.equals(y)为 true 并且 y.equals(z)为 true,那么 x.equals(z)也应该为 true。
d) 一致性:x.equals(y)的第一次调用为 true,那么 x.equals(y)的第二次、第三次、第 n次调用也应该为 true,前提条件是在比较之间没有修改 x 也没有修改 y。
e) 对于非空引用 x,x.equals(null)返回 false。
注意:通常重写 equals() 方法的时候我们也会 重写 hashCode() 方法,这样以保证对hashCode()方法的一般性契约,表明相等的对象也有相同的hash Code
2. Object 类中的 hashCode() 方法:
定义: public int hashCode(); 返回一个对象的 hash code 值。这个方法是为了更好的支持 java.util.Hashtable 这个类。
关于 Object 类的 hashCode()方法的特点:
a) 在 Java 应用的一次执行过程当中,对于同一个对象的 hashCode 方法的多次调用,他们应该返回同样的值(前提是该对象的信息没有发生变化) 。
b) 对于两个对象来说,如果使用 equals 方法比较返回 true,那么这两个对象的 hashCode值一定是相同的。
c) 对于两个对象来说,如果使用 equals 方法比较返回 false,那么这两个对象的 hashCode值不要求一定不同(可以相同,可以不同) ,但是如果不同则可以提高应用的性能。
d) 对于 Object 类来说,不同的 Object 对象的 hashCode 值是不同的(Object 类的 hashCode值表示的是对象的地址) 。
3. 当使用 HashSet 时, hashCode()方法就会得到调用,判断已经存储在集合中的对象的hash code 值是否与增加的对象的 hash code 值一致;如果不一致,直接加进去;如果一致,再进行 equals 方法的比较,equals 方法如果返回 true,表示对象已经加进去了,就不会再增加新的对象,否则加进去。(所以当调用set 的 add() 方法的时候底层是通过 hashCode() 和 equals() 方法共同协作完成的。)
4. 如果我们重写 equals 方法,那么也要重写 hashCode 方法,反之亦然。
//覆写hashCode()和equals()方法实现比较人名相同就不添加对象
package com.bob.set;
import java.util.HashSet;
public class SetTest3 {
public static void main(String[] args) {
HashSet set = new HashSet();
Student s1 = new Student("zhangsan");
Student s2 = new Student("zhangsan");
set.add(s1);
set.add(s2);
System.out.println(set);
}
}
class Student{
String name;
public Student(String name){
this.name = name;
}
//override hashCode method
public int hashCode(){
return this.name.hashCode();
}
//override equals method
public boolean equals(Object obj){
if(this == obj){
return true;
}
if(null != obj && obj instanceof Student){
Student s = (Student)obj;
if(name.equals(s.name)){
return true;
}
}
return false;
}
}
//也可使用eclipse工具自动生成这2个方法。Source-->generate hashCode() and equals();以上例子中取出来的都是[....]对象,如果想要取出对象的属性需要使用 HashSet 中的 iterator() 方法,此方法返回类型为 iterator 接口(可以使用子类实现接口方式返回此类型) 。iterator() 方法定义在 Iterable 接口中,因为Collection 接口是 iterable 的子接口,所以所有类集中都包含iterator()方法。
package com.bob.set;
import java.util.HashSet;
import java.util.Iterator;
public class IteratorTest {
public static void main(String[] args) {
// TODO Auto-generated method stub
HashSet set = new HashSet();
set.add("a");
set.add("b");
set.add("c");
set.add("d");
// 使用 Iterator必须先调用HashSet类的iterator()方法返回一个Iterator对象
// Iterator iter = set.iterator();
//
// while(iter.hasNext()){
// String value = (String)iter.next();
// System.out.println(value);
// }
for(Iterator iter = set.iterator(); iter.hasNext();){
String value = (String)iter.next();
System.out.println(value);
}
// 对于Set一般采取迭代器(遍历)方式取得元素。
// List也可以通过这种方式取得,但是一般list直接使用下标操纵更加方便。
}
}
5. Set的子接口:SortedSet
SortedSet 中主要常用类:TreeSet
//将对象排序
package com.bob.set;
import java.util.Comparator;
import java.util.Iterator;
import java.util.TreeSet;
public class TreeSetTest2 {
public static void main(String[] args) {
// TODO Auto-generated method stub
TreeSet set = new TreeSet(new PersonComparator()); // 按照此种实例方法规则排序
Person p1 = new Person(10);
Person p2 = new Person(20);
Person p3 = new Person(30);
Person p4 = new Person(40);
set.add(p1);
set.add(p2); // 向TreeSet添加对象TreeSet会自动跟里面已有对象进行比较
set.add(p3);
set.add(p4);
for (Iterator iter = set.iterator(); iter.hasNext();) {
Person p = (Person) iter.next();
System.out.println(p.score);
}
}
}
class Person {
int score;
public Person(int score) {
this.score = score;
}
public String toString() {
return String.valueOf(this.score);
}
}
// 自定义比较规则
class PersonComparator implements Comparator {
@Override
public int compare(Object o1, Object o2) {
// compare()方法返回值意思:
// <0,arg0 < arg1。 arg1在arg0前面
// =0, arg0 == arg1
// <0, arg0 > arg1
Person p1 = (Person) o1; // 集合中放置的是什么类型就转换成什么类型
Person p2 = (Person) o2;
return -(p1.score - p2.score); // 根据返回值来进行排序
}
}
Collections 静态类
package com.bob.set;
import java.util.Collections;
import java.util.Comparator;
import java.util.Iterator;
import java.util.LinkedList;
public class CollectionsTest {
public static void main(String[] args) {
LinkedList list = new LinkedList();
list.add(new Integer(-3));
list.add(new Integer(-1));
list.add(new Integer(-9));
list.add(new Integer(3));
list.add(new Integer(13));
//使用Collections类中的reverseOrder()方法进行反序
Comparator cmr = Collections.reverseOrder();
Collections.sort(list, cmr);
for(Iterator iter = list.iterator(); iter.hasNext();){
System.out.println(iter.next() + " ");
}
System.out.println("#####################");
//将集合打乱
Collections.shuffle(list);
for(Iterator iter = list.iterator(); iter.hasNext();){
System.out.println(iter.next() + " ");
}
//打印最大数和最小数
System.out.println("minimum value:" + Collections.min(list));
System.out.println("maximum value:" + Collections.max(list));
}
}
四 、 Map(映射)
1. map是一个对象,它会将键映射到它的值上。一个 map 不能包含重复的键,一个键最多映射一个值。(值可以是重复的)
2. Map 的 keySet() 方法返回 Key 的集合, 因为 Map 的键是不能重复的的,因此 keySet()方法的返回类型是 Set;而 Map 的值是可以重复的,因此 values() 方法的返回类型是 Collection, 可以容纳重复的元素。
keySet() 方法返回所有键的集合。返回一个 Set 类型,因为 Set 里面的元素是不能重复的。
values() 方法返回一个 Collection 类型,因为 Collection 是可以重复的。
// put() get() keySet()
package com.bob.set;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Set;
public class MapTest3 {
public static void main(String[] args) {
HashMap map = new HashMap();
map.put("a", "aa");
map.put("b", "bb");
map.put("c", "cc");
map.put("d", "dd");
map.put("e", "ee");
//使用keySet()获取所有key的集合,遍历所有key,或者key对于的值
Set set = map.keySet();
for(Iterator iter = set.iterator() ; iter.hasNext(); ){
String key = (String)iter.next();
String value = (String)map.get(key);
System.out.println(key + "=" + value);
}
}
}
//使用entrySet()方式实现。Map接口中的成员变量Map.Entry类型
package com.bob.set;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
public class MapTest5 {
public static void main(String[] args) {
HashMap map = new HashMap();
map.put("a", "aa");
map.put("b", "bb");
map.put("c", "dd");
map.put("c", "dd");
//获取entry对象,entry对象里面包含了key和value一对的映射视图
Set set = map.entrySet();
//map.entrySet返回的类型是Map.Entry
for(Iterator iter = set.iterator(); iter.hasNext(); ){
Map.Entry entry = (Map.Entry)iter.next();
String key = (String)entry.getKey();
String value = (String)entry.getValue();
System.out.println(key + " : " + value);
}
}
}
3. TreeMap
TreeMap类不仅实现了Map接口,还实现了Map接口的子接口java.util.SortedMap。
五、HashSet 与 HashMap 源代码
1. HashSet 底层是用 HashMap 实现的。当使用 add() 方法将对象添加到 Set 当中时, 实际上是将该对象作为底层所维护的 Map 对象的 key,而 value 则都是同一个 Object 对象(该对象我们用不上);
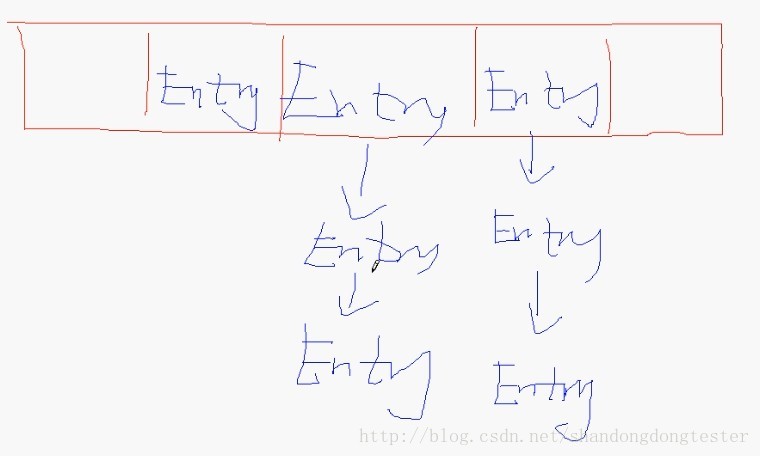
2. HashMap 底层会维护一个数组,我们向 HashMap 中放置的对象实际上是存储在该数组中。
3. 当向 HashMap 中 put 一对键值时,它会根据 key 的 hashCode 值计算出一个位置,该位置就是此对象准备往数组中存放的位置。如果该位置没有对象存在,就将此对象直接放进数组中; 如果该位置已经有对象存在了,则顺着此存在的对象的链开始寻找(Entry 类有一个 Entry 类型的 next 成员变量,指向了该对象的下一个对象),如果该链上有对象的话,在去使用 equals 方法进行比较,如果对此链上的某个对象的 equals 方法比较为 false,则将该对象放到数组当中,然后将数组中该位置以前存在的那个对象链接到此对象的后面(根据操作系统原理,当前被使用的元素,在不久的将来更有可能会被使用,所以替换了之前的位置)。
HashMap 的内存实现布局














 1252
1252











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









