







One of Oozie’s strengths is that it was custom built from the ground up for Hadoop. This not only means that Oozie works well on Hadoop, but that the authors of Oozie had an opportunity to build a new system incorporating much of their knowledge about other legacy workflow systems. Although some users view Oozie as just a workflow system, it has evolved into something more than that. The ability to use data availability and time-based triggers to schedule workflows via the Oozie coordinator is as important to today’s users as the workflow. The higher-level concept of bundles, which enable users to package multiple coordinators into complex data pipelines, is also gaining a lot of traction as applications and pipelines moving to Hadoop are getting more complicated.
Recurrent Problem
Hadoop, Pig, Hive, and many other projects provide the foundation for storing and processing large amounts of data in an efficient way. Most of the time, it is not possible to perform all required processing with a single MapReduce, Pig, or Hive job.Multiple MapReduce, Pig, or Hive jobs often need to be chained together, producing and consuming intermediate data and coordinating their flow of execution.
As developers started doing more complex processing using Hadoop, multistage Hadoop jobs became common. This led to several ad hoc solutions to manage the execution and interdependency of these multiple Hadoop jobs. Some developers wrote simple shell scripts to start one Hadoop job after the other. Others used Hadoop’s JobControl class, which executes multiple MapReduce jobs using topological sorting. One development team resorted to Ant with a custom Ant task to specify their MapReduce and Pig jobs as dependencies of each other—also a topological sorting mechanism. Another team implemented a server-based solution that ran multiple Hadoop jobs using one thread to execute each job.
As these solutions started to be widely used, several issues emerged. It was hard to track errors and it was difficult to recover from failures. It was not easy to monitor progress. It complicated the life of administrators, who not only had to monitor the health of the cluster but also of different systems running multistage jobs from client machines. Developers moved from one project to another and they had to learn the specifics of the custom framework used by the project they were joining. Different organizations were using significant resources to develop and support multiple frameworks for accomplishing basically the same task.
A Common Solution: Oozie
It was clear that there was a need for a general-purpose system to run multistage Hadoop jobs with the following requirements:
- It should use an adequate and well-understood programming model to facilitate its adoption and to reduce developer ramp-up time.
- It should be easy to troubleshot and recover jobs when something goes wrong.
- It should be extensible to support new types of jobs.
- It should scale to support several thousand concurrent jobs.
- Jobs should run in a server to increase reliability.
- It should be a multitenant service to reduce the cost of operation.
A Simple Oozie Job
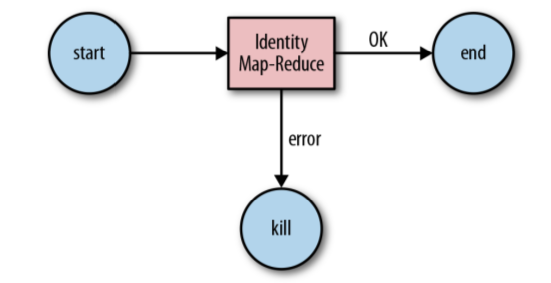
We’ll create an Oozie workflow application named identity-WF that runs an identity MR job, and the job just echoes its input as output and does nothing else.
$ git clone https://github.com/oozie-book/examples.git
$ cd examples/chapter-01/identity-wf
$ mvn clean assembly:single
...
[INFO] BUILD SUCCESS
...
$ tree target/example
The workflow.xml file contains the workflow definition of application identity-WF.
Why XML?
By using XML, Oozie application developers can use any XML editor tool to author their Oozie application. The Oozie server uses XML libraries to parse and validate the correctness of an Oozie application before attempting to use it, significantly simplifying the logic that processes the Oozie application definition. The same holds true for systems creating Oozie applications on the fly.
identity-WF Oozie workflow XML (workflow.xml)
<workflow-app xmlns="uri:oozie:workflow:0.4" name="identity-WF">
<parameters>
<property>
<name>jobTracker</name>
</property>
<property>
<name>nameNode</name>
</property>
<property>
<name>exampleDir</name>
</property>
</parameters>
<start to="identity-MR"/>
<action name="identity-MR">
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${exampleDir}/data/output"/>
</prepare>
<configuration>
<property>
<name>mapred.mapper.class</name>
<value>org.apache.hadoop.mapred.lib.IdentityMapper</value>
</property>
<property>
<name>mapred.reducer.class</name>
<value>org.apache.hadoop.mapred.lib.IdentityReducer</value>
</property>
<property>
<name>mapred.input.dir</name>
<value>${exampleDir}/data/input</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>${exampleDir}/data/output</value>
</property>
</configuration>
</map-reduce>
<ok to="success"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>The Identity Map-Reduce job failed!</message>
</kill>
<end name="success"/>
</workflow-app>The example application consists of a single file, workflow.xml. We need to package and deploy the application on HDFS before we can run a job.
hanying@master$ hdfs dfs -mkdir -p /user/hanying
hanying@master$ hdfs dfs -put target/example/ch01-identity ch01-identity //会存到/user/hanying目录下
hanying@master$ hdfs dfs -ls -R /user/hanying/ch01-identity #同$ hdfs dfs -ls -R ch01-identity
Before we can run the Oozie job, we need a job.properties file in our local filesystem that specifies the required parameters for the job and the location of the application package in HDFS:

$export OOZIE_URL=http://localhost:11000/oozie
$oozie job -run -config target/example/job.propertieserror:
SLF4J: Class path contains multiple SLF4J bindings.
...
Error: HTTP error code: 500 : Internal Server Error
Solution of SLF4J:http://www.slf4j.org/codes.html#multiple_bindings
remove the conflict jar.
Solution of Error: HTTP error code: 500 : Internal Server Error
oozie-error.log


http://oozie.apache.org/docs/4.2.0/AG_Install.html #To use a Self-Signed Certificate
$sudo keytool -genkeypair -alias tomcat2 -keyalg RSA -dname "CN=localhost" -storepass password -keypass password
$sudo keytool -exportcert -alias tomcat2 -file ./certificate.cert
#生成certificate.cert文件
$sudo keytool -import -alias tomcat -file certificate.cert
#是
证书已添加到密钥库中Error:
2016-05-20 09:55:49,729 ERROR ShareLibService:517 - SERVER[master] org.apache.oozie.service.ServiceException: E0104: Could not fully initialize service [org.apache.oozie.service.ShareLibService], Not able to cache sharelib. An Admin needs to install the sharelib with oozie-setup.sh and issue the 'oozie admin' CLI command to update the sharelib
org.apache.oozie.service.ServiceException: E0104: Could not fully initialize service [org.apache.oozie.service.ShareLibService], Not able to cache sharelib. An Admin needs to install the sharelib with oozie-setup.sh and issue the 'oozie admin' CLI command to update the sharelibFix it:
#stop oozie
#edit oozie-site.xml
<property>
<name>oozie.service.HadoopAccessorService.hadoop.configurations</name>
<value>*=/home/hanying/hadoop/etc/hadoop</value>
</property>
hanying@master:/usr/local/src/oozie-4.2.0$ sudo -u oozie bin/oozie-setup.sh sharelib create -fs hdfs://master:8020 -locallib share/Error:
hanying@master:/usr/local/src/oozie-4.2.0$ sudo -u oozie bin/oozie-setup.sh sharelib create -fs hdfs://master:8020 -locallib share/
setting CATALINA_OPTS="$CATALINA_OPTS -Xmx1024m"
the destination path for sharelib is: /user/oozie/share/lib/lib_20160520173926
Error: User: oozie is not allowed to impersonate oozie
Stack trace for the error was (for debug purposes):Fix it:
#1.Add the following content to core-site.xml
<property>
<name>hadoop.proxyuser.oozie.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.oozie.groups</name>
<value>*</value>
</property>
#2.Restart all.make sure your hadoop service is started
The default Hadoop ports are as follows: (HTTP ports, they have WEB UI):
| Daemon | Default Port | Configuration Parameter |
|---|---|---|
| Namenode | 50070 | dfs.http.address |
| Datanodes | 50075 | dfs.datanode.http.address |
| Secondarynamenode | 50090 | dfs.secondary.http.address |
| Backup/Checkpoint node? | 50105 | dfs.backup.http.address |
| Jobracker | 50030 | mapred.job.tracker.http.address |
| Tasktrackers | 50060 | mapred.task.tracker.http.address |
Internally, Hadoop mostly uses Hadoop IPC, which stands for Inter Process Communicator, to communicate amongst servers. The following table presents the ports and protocols that Hadoop uses. This table does not include the HTTP ports mentioned above.
| Daemon | Default Port | Configuration Parameter |
|---|---|---|
| Namenode | 8020 | fs.default.name |
| Datanode | 50010 | dfs.datanode.address |
| Datanode | 50020 | dfs.datanode.ipc.address |
| Backupnode | 50100 | dfs.backup.address |














 1032
1032











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









