






统计能够帮助我们更好的理解数据,它是一个丰富多彩且非常庞大的领域,更加适合单独成书而不是作为本系列的一个章节,我们不会深入讨论,代替的是我会刺激你对统计学的兴趣,足够让你更加深入的去了解它。
描述单变量数据
现在我有一集单变量数据集num_friends,里面记录的是每个用户的朋友数量。但是现在有个问题,我该怎么描述它呢:
num_friends = [100, 49, 41, 40, 25,
# ... and lots more
]对于小样本的数据我们可以用肉眼进行观察,但是对于大数据集,这是笨拙且不透明的方法(设想一下你有1百万的数据集)。为了更好的了解数据我们使用统计的方法来提取数据集中的相关特性。
第一种方法,你可以使用Counter统计朋友个数到直方图中:
friend_counts = Counter(num_friends)
xs = range(101) # largest value is 100
ys = [friend_counts[x] for x in xs] # height is just # of friends
plt.bar(xs, ys)
plt.axis([0, 101, 0, 25])
plt.title("Histogram of Friend Counts")
plt.xlabel("# of friends")
plt.ylabel("# of people")
plt.show()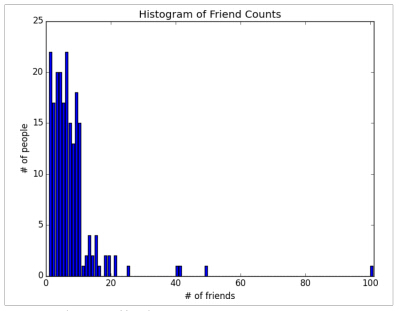
不幸的是,这个图表很难进行讨论,所以我们开始生成一些统计方法,最简单的统计方法就是统计数据集的数量:
num_points = len(num_friends) # 204你也可能会对最大值和最小值感兴趣:
largest_value = max(num_friends) # 100
smallest_value = min(num_friends) # 1特殊情况下你想要知道特定位置上的值:
sorted_values = sorted(num_friends)
smallest_value = sorted_values[0] # 1
second_smallest_value = sorted_values[1] # 1
second_largest_value = sorted_values[-2] # 49上面所述只是个开端。
Central Tendencies(中心趋向)
通常情况下,我们想要知道中心数据的一些概念,通常我们使用均值(mean),数据和除以数据个数:
# this isn't right if you don't from __future__ import division
def mean(x):
return sum(x) / len(x)
mean(num_friends) # 7.333333如果你有2个数据点,那么平均值就是他们之间距离的一半,当你向这个数据集中添加一些点时,这个平均值会在周围移动,它总是依赖每个数据点。
我们有时也会对中位数(median)感兴趣,它是最中间的值(如果你的数据集个数为奇数)或者最中间2个数的平均值(如果你的数据集个数为偶数)。
例如,如果我们有一个包含5个数据点且排序好的向量x,中位数是x[5//2]或者x[2];如果我们有6个数据点,中位数是x[2]和x[3]的平均数。
Notice:中位数不像均值依赖数据中的每个值。例如,如果你让最大点的值更大(或者让最小点的值更小),中位数仍然不变。
中位数函数比你想象的要复杂些,是因为要考虑“偶数”的情况:
def median(v):
"""finds the 'middle-most' value of v"""
n = len(v)
sorted_v = sorted(v)
midpoint = n // 2
if n % 2 == 1:
# if odd, return the middle value
return sorted_v[midpoint]
else:
# if even, return the average of the middle values
lo = midpoint - 1
hi = midpoint
return (sorted_v[lo] + sorted_v[hi]) / 2
median(num_friends) # 6.0很显然,均值是更容易计算,当数据变化时,均值是平滑变化的。如果我们有n个数据点,他们中的一个数据点会变大了很小数量e,均值会变大了e/n。反之为了找到中位数,我们不得不排序数据集,数据集中一个点变化了很小数量e,它可能让中位数变大了e或者变大的程度小于e,亦或是根本没有变(依赖于其余的数据)。
Notice:实际上不进行排序是更有效的方法,这个超出了本系列的范围,请参考《Data Mining Concepts and Techniques Third Edition》(Third Edition)作者:Jiawei Han等,第46页中的近似计算中位数的方法。在这里我们仍采用排序的方法。
同时,均值对数据中的离群值很敏感,如果最友好的用户有200个朋友(代替原先的100),那么均值会升高到7.82,然而中位数仍然不变。如果离群值是一个坏的数据,那么我们计算的均值会给我们一个误导的情形。例如,美国北卡罗来纳州大学平均收入最高的是学地理的,但这并不准确,因为他们把NBA球星乔丹的收入(离群值)也加进去了。
把中位数一般化,我们会得到分位数,至少有p%的观察值小于或者等于该值(分位数),且至少有(100-p)%的观察值大于或者等于该值:
def quantile(x, p):
"""returns the pth-percentile value in x"""
p_index = int(p * len(x))
return sorted(x)[p_index]
quantile(num_friends, 0.10) # 1
quantile(num_friends, 0.25) # 3
quantile(num_friends, 0.75) # 9
quantile(num_friends, 0.90) # 13接下来我们介绍另外一种中心趋向的概念—众数(mode),出现次数最多的值:
def mode(x):
"""returns a list, might be more than one mode"""
counts = Counter(x)
max_count = max(counts.values())
return [x_i for x_i, count in counts.iteritems()
if count == max_count]
mode(num_friends) # 1 and 6但是我们使用最频繁的还是均值。
Dispersion(离散度)
离散度是测量数据集的扩散程度,一般如果离散度取值在0附近表示一点也没有扩散,有很大的数表示扩散程度很高。例如,一个非常简单测量离散度的方法是range,即最大元素与最小元素之差:
# "range" already means something in Python, so we'll use a different name
def data_range(x):
return max(x) - min(x)
data_range(num_friends) # 99当最大值与最小值相等则range为0,只有数据集中所有值都相同时才会发生,意思就是数据一点也没有扩散。相反的,如果range很大,那么最大值比最小值大很多,说明数据扩散程度很高。
和中位数一样,这个range不依赖全部的数据。例如,一个数据集中有100个数据点,且这些数据点不是0就是100;另外还有一个数据集有100个数据点,且所有数据点都是50,可以看出来2个数据集有相同的range,但是明显第一数据集的离散程度要更高。
离散度测量更复杂的方法是方差:
def de_mean(x):
"""translate x by subtracting its mean (so the result has mean 0)"""
x_bar = mean(x)
return [x_i - x_bar for x_i in x]
def variance(x):
"""assumes x has at least two elements"""
n = len(x)
deviations = de_mean(x)
return sum_of_squares(deviations) / (n - 1)
variance(num_friends) # 81.54现在,不管我们的数据是什么单位,中心趋向的数据集必须具有相同的单位,range结果值和数据有一样的单位,另外一方面,方差的单位是原始数据单位的平方,这个很难理解,我们通常使用标准差(standard deviation)来度量数据集的离散度:
def standard_deviation(x):
return math.sqrt(variance(x))
standard_deviation(num_friends) # 9.03range和标准差具有相同的离群值问题,正如我们前面提到的均值。继续使用前面的数据集,如果我们最友好的用户有200个朋友,那么标准差为14.89,比之前高出60%。
一种更加健壮的方法是计算75%分位数与25%分位数之差:
def interquartile_range(x):
return quantile(x, 0.75) - quantile(x, 0.25)
interquartile_range(num_friends) # 6这种方法在具有少量离群值的时候不受影响。
接下来我们将要讨论相关性和辛普森悖论。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









