







扩展性和容错的解决方案
现在已经有了Federation集群,这样就能提供Hadoop大集群的解决方案。不过对于单个namenode server,还是需要HA QJM来提供单点故障的解决方案,使得其可以自动的故障切换。
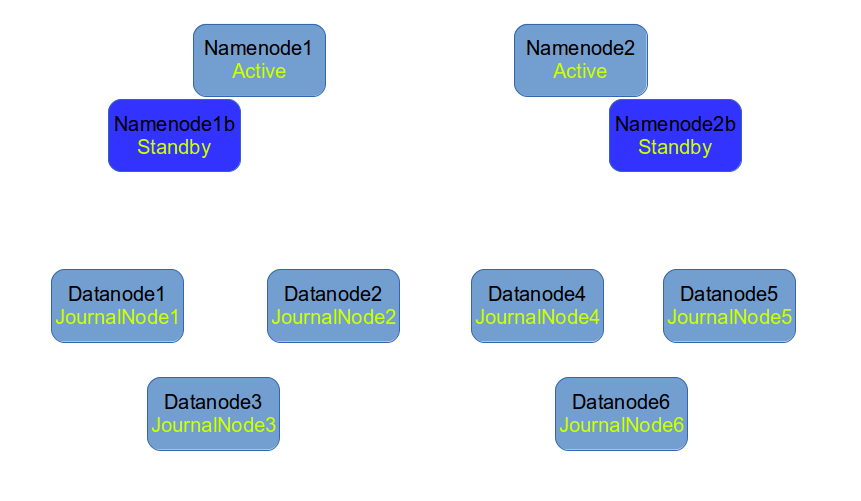
之前我已经有了两个namenode1和namenode2 server,分别用于管理两个namespace。现在把它们看成active machine, 并clone出两个虚拟机,作为它们的standby machine.
同时QJM需要至少3个JournalNodes,为了省机器,就用datanode1, datanode2和datanode3作为namenode1的JournalNodes. 再创建三个datanode server,同时也作为namenode2的JournalNodes.
架构图:
配置
添3个datanode到federation中
从datanode1中clone出虚拟机,然后复制到另一台物理主机中,安装后,再克隆出2份
完成之后,发现一个奇怪的现象,每个namenode只能看到3台datanode server, 而且每次看到的还不同。
hduser@namenode1:~$ hdfs dfsadmin -printTopology
Rack: /168/1
192.168.1.73:50010 (datanode1)
192.168.1.74:50010 (datanode2)
192.168.1.75:50010 (datanode3)
hd 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2930
2930











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









