







Hadoop手动升级HA配置手册
1 Hadoop组件升级
本文是Apache hadoop、Hbase升级至CDH版hadoop、Hbase,同时涵盖了Hadoop HA的配置的操作手册..
2 Hadoop升级
2.1 Hadoop升级准备
2.1.1 环境说明
Hadoop原始版本、升级版本分别为:Apache Hadoop 1.2.1,hadoop2.5.0-CDH5.3.3
2.1.2 升级准备
2.1.2.1 升级JDK
#如果JDK版本已经是1.7以上,此步可略过
rpm –ivh oracle-j2sdk1.7-1.7.0+update67-1.x86_64.rpm
注:默认安装在/usr/java目录内
2.1.2.2 停Hbase相关外围应用、停Hbase服务
stop-hbase.sh
注:此时zookeeper和Hadoop相关主进程皆不需要停.
2.1.2.3 备份Namenode元数据
#hadoop先进入安全模式,合并edits并备份namenode元数据
hadoop dfsadmin -safemode enter
hadoop dfsadmin -saveNamespace
stop-all.sh
cp /app/data/name/*/app/data/name_bak/
注:这里的/app/data/name/来至Hadoop1.2.1里hdfs-site.xmldfs.name.dir的配置
2.1.2.4 上传新版Hadoop并做好相关配置文件的设置
#上传并解压安装包hadoop-2.5.0-cdh5.3.3.tar.gz到namenode所在机器上,如:/app/
tar –zxvf hadoop-2.5.0-cdh5.3.3.tar.gz
# 检查主节点安装包执行目录是否有执行权限
#配置如下参数文件:
#core-site.xml,hadoop-env.sh,hdfs-site.xml,mapred-site.xml,slaves,yarn-site.xml,yarn-evn.sh,master
a) 配置core-site.xml
#基本沿用1代时的配置.
b) hadoop-env.sh
exportJAVA_HOME=/usr/java/jdk1.7.0_67-cloudera/
export HADOOP_HEAPSIZE=70000
c) hdfs-site.xml
#修改参数如下参数的名称以兼容2代, 其它参数沿用.
#修改参数dfs.name.dir为dfs.namenode.name.dir
#修改参数dfs.data.dir为dfs.datanode.data.dir
d) mapred-site.xml
#新增yarn参数,之前1代的参数可以注释掉
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.system.dir</name>
<value>/home/shenl/hadoop1.2.1/system</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/home/shenl/hadoop1.2.1/local</value>
</property>e) slaves
沿用1代的配置
f) yarn-site.xml
<property>
<name>yarn.resourcemanager.address</name>
<value>master1:8032</value> </property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master1:8033</value>
</property> <property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master1:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>注:这里master1是namenode的主机名
g) yarn-env.sh
#修改JAVA_HOME
exportJAVA_HOME=/usr/java/jdk1.7.0_67-cloudera/
h) master
#新增master文件,填写namenode的主机名
2.1.2.5 在Namenode节点里分发已经配置好的2代hadoop
scp -rq /app/hadoop-2.5.0-cdh5.3.3 hadoop@datanode1:/app/&&
scp -rq /app/hadoop-2.5.0-cdh5.3.3 hadoop@datanode2:/app/&&
2.1.2.6 在所有节点上配置HADOOP_HOME被生效
vi ~/bash_profile
export HADOOP_HOME=/home/shenl/hadoop-2.5.0-cdh5.3.3
source ~/.bash_profile
which hadoop
which hadoop-daemon.sh
2.2 Hadoop升级回滚
2.1升级Hadoop
2.1.1 升级Namenode
#观察namenode日志
tail-f hadoop-hadoop-namenode-bigdata01.log
hadoop-daemon.shstart namenode -upgrade

注:Namenode日志稳定后,即可任务升级成功
2.1.2 升级Datanode
#升级Datanode,可以在Namenode里对所有时间节点同时升级
hadoop-daemons.shstart datanode
#数据节点日志如下:

注:在namenode日志里看到所有的数据节点成功方可认为升级完成
2.1.3 升级Datanode
#namenode节点上执行, YARN验证
yarn-daemon.sh startresourcemanager
yarn-daemons.shstart nodemanager
mr-jobhistory-daemon.shstart historyserver
#执行wordcount验证:
hadoopjar/home/shenl/hadoop-2.5.0-cdh5.3.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0-cdh5.3.3.jarwordcount /shenl/gc.log /shenl3/
注:检测控制台执行过程 map 100% reduce 100% 即任务执行成功 或则到 8088端口查看作业情况.
2.2 回滚hadoop
#还原回1代Hadoop的环境变量,并生效,参数文件指向1代
2.2.2.1 回滚Namenode
hadoop-daemon.shstart namenode -rollback
2.2.2.2 回滚Datanode
hadoop-daemons.shstart datanode –rollback
3 Hbase升级
3.1 Hadoop升级准备
3.1.1 环境说明
Hbase原始版本、升级版本分别为:Hbase 0.96.1.1 ,hbase0.98.6-cdh5.3.3
3.1.2 升级准备
3.1.2.1 上传并解压安装文件
上传并解压安装包(hbase-0.98.6-cdh5.3.3.tar.gz)到Hmaster机器上,如目录:/app/
tar–zxvf hbase-0.98.6-cdh5.3.3.tar.gz
3.1.2.2 修改hbase-env.sh里的相关参数
#修改引用的JDK
export JAVA_HOME=/usr/java/jdk1.7.0_67-cloudera/
export HBASE_HEAPSIZE=8000
export HBASE_PID_DIR=/home/shenl/pids/hbase96
3.1.2.3 拷贝1代hbase的相关参数
#拷贝1代hbase的conf下的Hbase-site.xml、regionserver到2代的conf下.
3.1.2.4 拷贝hmaster里hbase到各slave节点
#分发2代hbase到各个节点
scp -r /app/hbase-0.98.6-cdh5.3.3hadoop@datanode1:/app/
3.1.2.5 各节点里修改Hbase的环境变量
#修改用户的环境变量,指定$HBASE_HOME并追加$HBASE_HOME/bin到PATH
vi ~/.bash_profile
exportHBASE_HOME=/home/impala/hbase-0.98.6-cdh5.3.3
source ~/.bash_profile
3.2 Hbase升级回滚
4.1 升级Hbase
执行升级检查和升级命令(Hmaster节点)
hbase upgrade –check
hbase upgrade –execute
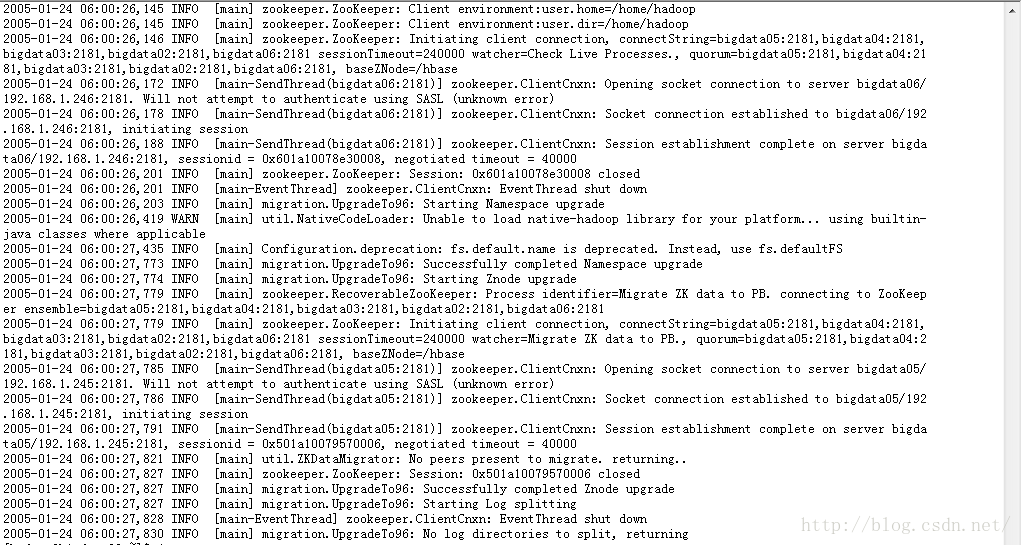
#启动hbase (Hmaster节点上执行)
start-hbase.sh
4.2回滚hbase
修改回之前的环境变量,生效后启动即可.
5 Hadoop HA配置
5.1 Hadoop Yarn HA配置
5.1.1 hdfs-site.xml参数配置,注意看HASupport部分
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl"href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/shenl/home/impala/data/hadoop1.2.1</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/shenl/home/impala/dfs_data01/dfs1.2.1</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/shenl/var/hadoop1.2.1/tmp</value>
</property>
<property>
<name>dfs.http.address</name>
<value>master1:50070</value>
</property>
<property>
<name>dfs.datanode.du.reserved</name>
<value>10737418240</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>data1:50090</value>
<description>
The secondary namenode http server address and port.
If the port is 0 then the server will start on a freeport.
</description>
</property>
<property>
<name>dfs.datanode.max.xcievers</name>
<value>4096</value>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>/home/shenl/home/impala/src/hadoop-1.2.1/conf/slaves.ex</value>
</property>
<!-- HA Configure -->
<property>
<name>dfs.nameservices</name>
<value>zzg</value>
</property>
<property>
<name>dfs.ha.namenodes.zzg</name>
<value>master1,data1</value>
</property>
<property>
<name>dfs.namenode.rpc-address.zzg.master1</name>
<value>master1:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.zzg.data1</name>
<value>data1:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.zzg.master1</name>
<value>master1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.zzg.data1</name>
<value>data1:50070</value>
</property>
<property>
<name>dfs.namenode.servicerpc-address.zzg.master1</name>
<value>master1:53310</value>
</property>
<property>
<name>dfs.namenode.servicerpc-address.zzg.data1</name>
<value>data1:53310</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://data1:8485;data2:8485;data3:8485/zzg</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/shenl/usr/local/cloud/data/hadoop/ha/journal</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.zzg</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>data1:2181,data2:2181,data3:2181</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/shenl/.ssh/id_rsa</value>
</property>
</configuration>5.1.2 yarn-site.xml参数配置,注意看HA Support部分.
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>master1:8032</value> </property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master1:8033</value>
</property> <property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master1:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!-- HA Support -->
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.zk-state-store.address</name>
<value>data1:2181,data2:2181,data3:2181</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>data1:2181,data2:2181,data3:2181</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>zzg</value>
</property>
<property>
<name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name>
<value>5000</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>master1:23140</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>master1:23130</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>master1:23188</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>master1:23125</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>master1:23141</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm1</name>
<value>master1:23142</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>data1:23140</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>data1:23130</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>data1:23188</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>data1:23125</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>data1:23141</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm2</name>
<value>data1:23142</value>
</property>
<property>
<description>Address where the localizer IPCis.</description>
<name>yarn.nodemanager.localizer.address</name>
<value>0.0.0.0:23344</value>
</property>
<property>
<description>NM Webapp address.</description>
<name>yarn.nodemanager.webapp.address</name>
<value>0.0.0.0:23999</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/home/shenl/usr/local/cloud/data/hadoop/yarn/local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/home/shenl/usr/local/cloud/data/logs/hadoop</value>
</property>
<property>
<name>mapreduce.shuffle.port</name>
<value>23080</value>
</property>
<property>
<name>yarn.client.failover-proxy-provider</name>
<value>org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider</value>
</property>
</configuration>5.2 Hadoop HA初始化
5.2.1停hbase和hadoop服务
stop-habase.sh
stop-all.sh
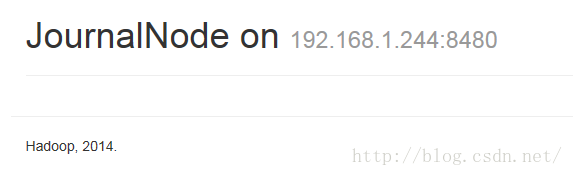
5.2.2启动JournalNode服务
hadoop-daemon.sh start journalnode
注: hdfs-site.xml里8485端口对应的节点上执行.
#验证:访问web页面 data2:8480, data3:8480, data4:8480 或则jps查看进程
5.2.3 格式化所有JournalNode
hdfs namenode -initializeSharedEdits -force
注:
1 这里默认master1为主namenode,data1为备namenode,如上命令在master1里执行)
2 这个操作影响的参数和目录为 HDFS-SITE.xml里的dfs.journalnode.edits.dir 参考值为:/home/shenl/data/hadoop/ha/journal
3 这一操作主要完成格式化所有JournalNode,以及将日志文件从master1拷贝到所有JournalNode
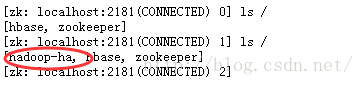
5.2.4 在master1里执行ZookeeperHA格式化
hdfs zkfc -formatZK

5.2.5 拷贝主namenode元数据到备节点内
scp -r home/impala/data/hadoop1.2.1/* hadoop@data1:/home/shenl/data/hadoop1.2.1
注:
拷贝master1节点内的dfs.namenode.name.dir和共享dfs.namenode.shared.edits.dir目录的内容到data1的相应目录内.
5.2.6 在master1里启动namenode
hadoop-daemon.sh start namenode
5.2.7 在data1里启动namenode
hadoop-daemon.sh start namenode
5.2.8 在master1里启动所有的datanode
hadoop-daemons.sh start datanode
注:此时 查看页面master1:35070、data1:35070,两个namenode都是出于standby的状态,因为还未开启选举服务。
5.2.9 在master1和data1内启动自动选举服务
hadoop-daemon.sh start zkfc

5.2.10 在master1里执行命令验证HA是否正常
hdfshaadmin -getServiceState master1
hdfshaadmin -DFSHAadmin -failover master1 data1
#或则kill -9 active的namenode,验证standy的namenode是否变为active
5.3 YARN HA验证
5.3.1 配置YARN HA参数
#HA 参数已经在HADOOP HA时配置好
5.3.2 验证
1) 分别在主namenode和备namenode里执行
yarn-daemon.shstart resourcemanager
2) 在主namenode里执行
yarn-daemons.shstart nodemanager
3) 在主namenode里执行
mr-jobhistory-daemon.shstart historyserver
4) 执行Yarn HA状态验证脚本
yarn rmadmin -getServiceState rm1
yarn rmadmin -getServiceState rm2
5) kill-9 active的nodemanager 测试
6) 验证wordcont MR程序,执行如下命令:
hadoopjar /home/shenl/hadoop-2.5.0-cdh5.3.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0-cdh5.3.3.jarwordcount /shenl/gc.log /shenl3/
如果成功,视为Yarn HA可用.
6 Hbase HA配置
6.1 Hbase HA配置
6.1.1 配置Hbase HA参数
1) 拷贝配置了Hadoop HA的core-site.xml,hdfs-site.xml到Hmaster节点的conf目录
cp/home/shenl/hadoop-2.5.0-cdh5.3.3/etc/hadoop/core-site.xml .
cp/home/ shenl /hadoop-2.5.0-cdh5.3.3/etc/hadoop/hdfs-site.xml .
2) Hmaster的conf目录里新增backup-master文件,填写作为备份master的主机名(如data1)
3) scpHmaster节点的conf的内容到各个从节点
4) 在hbase主节点里执行start-hbase.sh
6.2 Hbase HA验证
kill -9 一个active的Hmaster,在Hbase shell执行
put 'shenl' ,'row11','a:name','hello'
7 Hadoop升级最终化
#集群稳定后,执行最终化以提交本次升级任务.
hadoop dfsadmin –finalizeUpgrade
8 总结
结合日志分析具体问题.
















 3516
3516











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











