









一,先说一下为什么要分表
当一张的数据达到几百万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了。分表的目的就在于此,减小数据库的负担,缩短查询时间。
根据个人经验,mysql执行一个sql的过程如下:
1,接收到sql;2,把sql放到排队队列中 ;3,执行sql;4,返回执行结果。在这个执行过程中最花时间在什么地方呢?第一,是排队等待的时间,第二,sql的执行时间。其实这二个是一回事,等待的同时,肯定有sql在执行。所以我们要缩短sql的执行时间。
mysql中有一种机制是表锁定和行锁定,为什么要出现这种机制,是为了保证数据的完整性,我举个例子来说吧,如果有二个sql都要修改同一张表的同一条数据,这个时候怎么办呢,是不是二个sql都可以同时修改这条数据呢?很显然mysql对这种情况的处理是,一种是表锁定(myisam存储引擎),一个是行锁定(innodb存储引擎)。表锁定表示你们都不能对这张表进行操作,必须等我对表操作完才行。行锁定也一样,别的sql必须等我对这条数据操作完了,才能对这条数据进行操作。如果数据太多,一次执行的时间太长,等待的时间就越长,这也是我们为什么要分表的原因。
二,分表
1,做mysql集群,例如:利用mysql cluster ,mysql proxy,mysql replication,drdb等等
有人会问mysql集群,根分表有什么关系吗?虽然它不是实际意义上的分表,但是它启到了分表的作用,做集群的意义是什么呢?为一个数据库减轻负担,说白了就是减少sql排队队列中的sql的数量,举个例子:有10个sql请求,如果放在一个数据库服务器的排队队列中,他要等很长时间,如果把这10个sql请求,分配到5个数据库服务器的排队队列中,一个数据库服务器的队列中只有2个,这样等待时间是不是大大的缩短了呢?这已经很明显了。所以我把它列到了分表的范围以内,我做过一些mysql的集群:
linux mysql proxy 的安装,配置,以及读写分离
mysql replication 互为主从的安装及配置,以及数据同步
优点:扩展性好,没有多个分表后的复杂操作(php代码)
缺点:单个表的数据量还是没有变,一次操作所花的时间还是那么多,硬件开销大。
1. 先了解一下你是否应该用MySQL集群。
减少数据中心结点压力和大数据量处理,采用把MySQL分布,一个或多个application对应一个MySQL数据库。把几个MySQL数据库公用的数据做出共享数据,例如购物车,用户对象等等,存在数据结点里面。其他不共享的数据还维持在各自分布的MySQL数据库本身中。
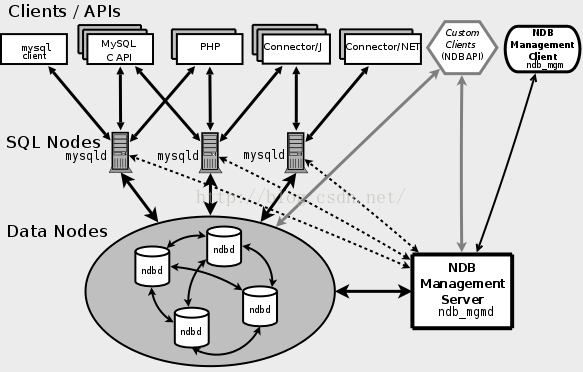
2. 集群MySQL中名称概念.(如上图)
1)Sql结点(SQL node--上图对应为MySQLd):分布式数据库。包括自身数据和查询中心结点数据.
2)数据结点(Data node -- ndbd):集群共享数据(内存中).
3)管理服务器(Management Server – ndb_mgmd):集群管理SQL node,Data node.
方法二、
2,预先估计会出现大数据量并且访问频繁的表,将其分为若干个表
(1)预先估计某个大表的数据量,按实际情况将其均分为固定数量表
根据分表算法,将数据平均分散到不同的数据表中,常见处理方式有对自增id取模、对某个字段进行hash。比如某系统用户预计支持1亿用户数,分100个表存储用户数据,按照自增id的最后2位来分表,对100取模,那么用户数据表就是user_01~user_99。
(2)按时间拆分
对于那种根据时间增长较快的数据可以按时间拆分,根据业务实际情况按天、按月、按年等进行拆分。比如进销存数据,我们可以按月分表,形如jxc_data_201201、jxc_data_201202
(3)按每个表固定记录行数拆分
一般根据自增长ID拆表,每张表存储指定数量的数据。一张表的数据行数到了指定数量,就自动保存到新的表里。
优点:避免一张表出现几百万条数据,缩短了一条sql的执行时间
缺点:当一种规则确定时,打破这条规则会很麻烦,上面的例子中我用的hash算法是crc32,如果我现在不想用这个算法了,改用md5后,会使同一个用户的消息被存储到不同的表中,这样数据乱套了。扩展性很差。
三、分表之后的处理
分表之后,麻烦的事情来了,业务数据分散在各个分表中,之前的业务功能如何保证呢?比如说我要插入一条记录、更新一条记录、删除一条记录、查询统计数据,现在要怎么处理呢。
如何你用的user分表的存储引擎是MyISAM,那么恭喜你,这里有一种很简单的处理方法。
利用merge存储引擎将拆分的表合并成一张表
在我们查询这个merge表就相当于查询所有字表的数据了,非常方便。当然merge表还是有一定的限制的,具体请查看mysql官方手册。
这里引用MYSQL参考手册中的片段来说明如何操作
下面例子说明如何创建一个MERGE表:
mysql> CREATE TABLE t1(
mysql> CREATE TABLE t2(
mysql> INSERT INTO t1(message) VALUES ('Testing'),('table'),('t1');
mysql> INSERT INTO t2(message) VALUES ('Testing'),('table'),('t2');
mysql> CREATE TABLEtotal (
注意,一个列在MERGEN表中被索引,但没有被宣告为一个PRIMARY KEY,因为它是在更重要的MyISAM表中。这是必要的,因为MERGE表在更重要的表中的设置上强制非唯一性。
创建MERGE表之后,你可以发出把一组表当作一体来操作的查询:
mysql> SELECT * FROMtotal;
+---+---------+
| a | message |
+---+---------+
| 1 | Testing |
| 2 | table
| 3 | t1
| 1 | Testing |
| 2 | table
| 3 | t2
+---+---------+
根据这个方法的介绍,我们可以创建一张user的合并表,然后对这张表进行查询即可达到查询分表所有的数据的效果。
-----------------------------------------我是分割线---------------------------------
实际使用中,会限制页面的显示记录,理论上数据库操作100w条记录(联合查询)延迟时间可以接受,对于分表,页面会对每一张表分别联合查询,将每一张表的数据分别显示。
如果要对所有的数据一起操作,要建一个日志服务器单独处理日志。














 67
67











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









