







 本文对比分析了梯度下降、随机梯度下降、批量梯度下降及其变种,探讨了它们的优缺点,包括动量法、Adagrad、Adam等优化策略在处理局部最优和非凸目标函数时的效果。
本文对比分析了梯度下降、随机梯度下降、批量梯度下降及其变种,探讨了它们的优缺点,包括动量法、Adagrad、Adam等优化策略在处理局部最优和非凸目标函数时的效果。
1.前言
这几种方法呢都是在求最优解中经常出现的方法,主要是应用迭代的思想来逼近。在梯度下降算法中,都是围绕以下这个式子展开:
其中在上面的式子中hθ(x)代表,输入为x的时候的其当时θ参数下的输出值,与y相减则是一个相对误差,之后再平方乘以1/2,并且其中
注意到x可以一维变量,也可以是多维变量,实际上最常用的还是多维变量。我们知道曲面上方向导数的最大值的方向就代表了梯度的方向,因此我们在做梯度下降的时候,应该是沿着梯度的反方向进行权重的更新,可以有效的找到全局的最优解。这个θ的更新过程可以描述为:
就是根据每一个x的分量以及当时的偏差值进行θ的更新,其中α为步长,一开始没搞清楚步长和学习速率的关系。这里提一下其实这两个是一个概念,叫法不一样,最优化问题中叫步长,但一般在神经网络中也叫学习速率,比较好理解。
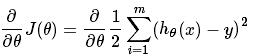
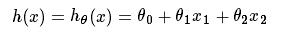
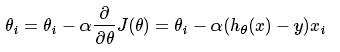
2.梯度下降、随机梯度下降、批量(小批量)梯度下降算法对比
下面是楼燚航的理解,个人感觉还是非常透彻的:
- 梯度下降:梯度下降就是上面的推导,要留意,在梯度下降中,对于θ的更新,所有的样本都有贡献,也就是参与调整θ.其计算得到的是一个标准梯度。因而理论上来说一次更新的幅度是比较大的。如果样本不多的情况下,当然是这样收敛的速度会更快啦~
- 随机梯度下降:可以看到多了随机两个字,随机也就是说用样本中的一个例子来近似所有的样本,来调整θ,因而随机梯度下降是会带来一定的问题,因为计算得到的并不是准确的一个梯度,容易陷入到局部最优解中
- 批量梯度下降:其实批量的梯度下降就是一种折中的方法,他用了一些小样本来近似全部的,其本质就是随机指定一个例子替代样本不太准,那我用个30个50个样本那比随机的要准不少了吧,而且批量的话还是非常可以反映样本的一个分布情况的。
2.1 梯度下降算法
这里同样引入楼燚航给的一个例子:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









