







梯度下降法是求解无约束最优问题中常用到的一种学习方法,形式简单,属于一阶收敛,在空间进行线性搜索。在前面讲到的逻辑斯蒂回归模型中,就常用到梯度下降法来学习参数。
首先给出问题定义(统计学习方法附录A):
假设f(x)是
Rn
上具有一阶连续偏导的函数,求解的目标问题如下:
x∗
表示目标函数
f(x)
的极小值点。
梯度下降法通过迭代的方法不断更新
x
的值,直至
若第k次迭代时
其中, gk 为在 x(k) 点的梯度。有如下等式来对 x(k+1) 更新:
其中,
pk=−gk
是该点的负梯度,表示更新
x
时的搜索方向;
在实际运用中最简单方法是通过多次实验选取最合适的步长作为定长来使用。
综上,梯度下降法的步骤如下:
(1)、取初始值
x(0)
,置k=0;
(2)、计算
f(x(k))
;
(3)、计算梯度
gk=g(x(k))
,当
||gk||<ϵ
时,说明已经收敛,停止迭代,记
x∗=x(k)
;否则,令
pk=−gk
;
(4)、使用等式
x(k+1)=x(k)+λkpk
来更新
x
,并求
(5)、否则,置
k=k+1
,转(3)。
梯度下降法通常在离极值点远的地方下降很快,但在极值点附近时会收敛速度很慢。并且,在目标函数是凸函数时,梯度下降法的解是全局最优解。而在一般情况下,梯度下降法不保证求得全局最优解。
示例
若对一个线性数据集通过梯度下降法求得线性方程的参数
theta,即上面的xk
。设在训练数据上的损失函数为:
J(θ)=12m∑i=1m(hθ(xi)−yi)2
其中, hθ(x)=θ⋅x , θ为增广向量
对 J(θ) 求偏导,得:
J′(θ)=12m×2∑mi=1(hθ(xi)−yi)×h′θ(xi)
=1m∑mi=1(hθ(xi)−yi)×xi
用式子
θj←θj−λ⋅J′(θ)
对 θj 进行更新。
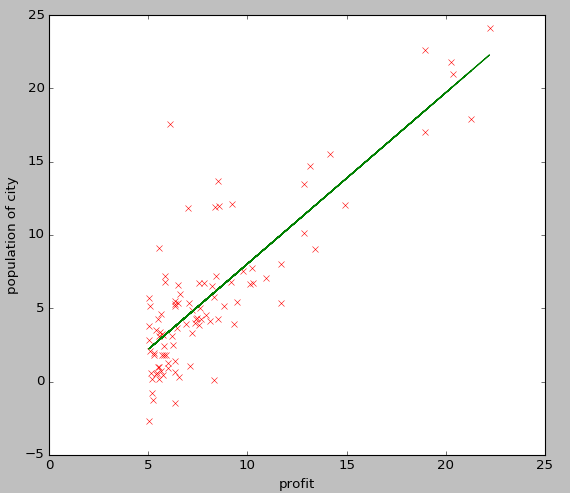
下面是对一个单变量数据集使用梯度下降法得出的线性方程:















 833
833

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









