







上一篇博客里,我们介绍了VJ人脸检测算法的特征,就是基于积分图像的矩形特征,这些矩形特征也被称为Haar like features, 通常来说,一张图像会生成一个远远高于图像维度的特征集,比如一个 24×24 的图像,会生成162336个矩形特征。在实时的人脸检测应用中,不可能把所有的特征都用上,所有需要做特征选择,这篇博客里,我们将要介绍AdaBoost的训练方法和基于AdaBoost的层级分类器。
AdaBoost 分类
AdaBoost 可以同时进行特征选择与分类器训练,简单来说,AdaBoost 就是将一系列的”弱”分类器通过线性组合,构成一个”强”分类器。如下所示:
h(x) 就是一个”强”分类器,而 hj(x) 就是”弱”分类器, hj(x) 其实是一个简单的阈值函数:
θj 就是阈值, sj∈{−1,1} 以及系数 αj 都由训练的时候确定。结合维基百科和IJCV上的文章 Robust Real-Time Face Detection , 训练算法的具体流程如下:
给定一组
N
个训练样本
- 对每一个训练样本
i
赋予一个初始的权值:
wi1=1/N 假设一张图像会产生 M 个特征,对于每一个特征
fj , j=1,2,...M
1) 对权值重新归一化 wij=wij∑Nt=1wtj
2) 遍历训练集中每个样本特征 fj ,寻找最优的 θj , sj 使其分类误差最小即: θj,sj=argminθ,s∑Ni=1wijϵij ,
其中 ϵij={01ifyi=hj(xi,θj,sj)otherwise
3) 更新下一个特征的权值: wj+1,i=wj,i⋅β1−eij , 如果样本 xi 被正确识别则 ei=0 ,否则 ei=1 . βj=ϵj1−ϵj遍历所有的特征, 可以得到最终的分类器 h(x)=sign(∑Mj=1αjhj(x)) , αj=log1βj
层级分类器
在一张正常的图像中,包含人脸的区域只占整张图像中很小的一部分,如果所有的局部区域都要遍历所有特征的话,这个运算量非常巨大,也非常耗时,所以为了节省运算时间,应该把更多的检测放在潜在的正样本区域上。所以有了层级分类器的概念,层级分类器就是为了将任务简化,一开始用少量的特征将大部分的negative 区域剔除,后面再利用复杂的特征将 false positive 区域剔除。
在层级分类器架构中,每一层次含有一个”强”分类器,所有的矩形特征被分成几组,每一组都包含部分矩形特征,这些矩形特征用在层级分类器的每一阶段,层级分类器的每一阶段都会判别输入的区域是不是人脸,如果肯定不是,那么这个区域会被立即舍弃掉,只有那些被判别为可能是人脸的区域才会被传入下一阶段用更为复杂的分类器进一步的判别。其流程图如下所示:
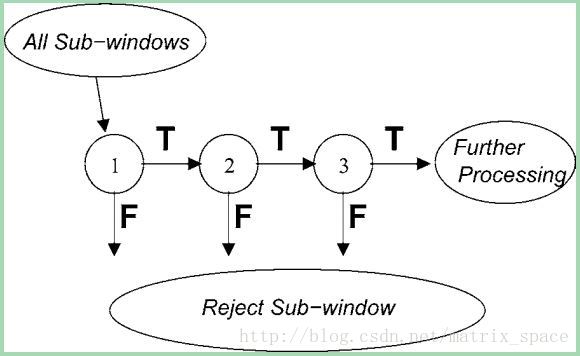
从上图可以看出,所有的局部区域 (sub-windows) 会用比较简单的特征表示,如下图所示。下面的两种特征可以达到100%的检测率,但是也会产生很多的 false positive,一般来说是 50%的FP rate。但是这两种特征对 negative 区域的识别非常高效,所以层级分类器的第一层基本都是用这两种特征加上一个”强”分类器先将大量的negative 区域剔除。对于 false positive 的处理,有赖于后面阶段更多的特征及分类器。

层级分类器的总的识别率
D
或者false positive
我们利用AdaBoost 训练分类器的时候,目标函数是分类误差,分类误差不能同时反映检测率与false positive rate, 我们可以通过改变阈值的方法来调整检测率与false positive rate, 一般来说,高阈值的分类器的检测率以及false positive rate 都会比较低,而低阈值的分类器的检测率及false positive rate都很高。此外,测试更多的特征将使得分类器提高识别率同时降低false positive rate, 但是测试更多的特征,也会耗费更多的时间。所以一个层级分类器,将综合考虑以下几个因素:
- 层级分类器的层次,即需要多少个分类器;
- 每一层分类器需要测试的特征数 ni ;
- 每一层分类器的阈值。
IJCV 的文章提到的算法如下图所示:

一开始需要定义每一层分类器的最大 false positive rate
f
, 以及最小的检测率
只有层级分类器的总得 false positive rate Fi 高于设定的 Ftarget ,就要增加一层分类器。而后面层的负样本都是由前面分类器产生的 false positive 样本。
在IJCV的文章里,VJ 分类器最后一共是38层,并且含有 6060个特征。 作者给出了前面7层的特征数:
2->10->25->25->50->50->50
参考来源:
https://en.wikipedia.org/wiki/Viola%E2%80%93Jones_object_detection_framework
Viola, Jones: Robust Real-Time Face Detection, IJCV 2001














 2242
2242











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









