







 本文档详细介绍了如何在solrcloud 5.5.0集群上配置IK分词器,并修改managed-schema以适应需求。通过将IKAnalyzer-solr5-5.x.jar分发到所有节点,修改managed-schema以添加分词字段,然后重启solr服务器。接下来,创建collection并连接到zookeeper进行管理。最后,展示了如何编写SolrCloud应用,使用MapReduce从HBase读取数据并生成索引。
本文档详细介绍了如何在solrcloud 5.5.0集群上配置IK分词器,并修改managed-schema以适应需求。通过将IKAnalyzer-solr5-5.x.jar分发到所有节点,修改managed-schema以添加分词字段,然后重启solr服务器。接下来,创建collection并连接到zookeeper进行管理。最后,展示了如何编写SolrCloud应用,使用MapReduce从HBase读取数据并生成索引。
solrcloud集群情况
solrcloud集群已经安装完成。
solr版本:5.5.0,zookeeper版本:3.4.6
solr的操作用户、密码: solr/solr123
solr使用的zookeeper安装位置:/opt/zookeeper-3.4.6
solr安装位置:/opt/solr-5.5.0
solr端口:8983
zookeeper端口:9983
5台机器,每台机器上安装的都有solr和zookeeperzookeeper启动:/opt/zookeeper-3.4.6/bin/zkServer.sh start zookeeper停止:/opt/zookeeper-3.4.6/bin/zkServer.sh stop zookeeper状态:/opt/zookeeper-3.4.6/bin/zkServer.sh status solr启动:/opt/solr-5.5.0/bin/solr start solr停止:/opt/solr-5.5.0/bin/solr stop solr状态:/opt/solr-5.5.0/bin/solr status solr访问:http://10.1.202.67:8983/solr/ http://10.1.202.68:8983/solr/ http://10.1.202.69:8983/solr/ http://10.1.202.70:8983/solr/ http://10.1.202.71:8983/solr/复制IK分词到solr中
注意:IK分词不要用之前IKAnalyzer2012FF_u1.jar的版本,以前版本不支持solr5.0以上,需要用IKAnalyzer2012FF_u2.jar,或者在github上下载源码,然后自己编译,github连接如下:
https://github.com/EugenePig/ik-analyzer-solr5/blob/master/README.md
本人用的是自己编译的ik分词包Ik-analyzer-solr5-5.x.jar
scp ./Ik-analyzer-solr5-5.x.jar solr@10.1.202.67:/opt/solr-5.5.0/server/solr-webapp/webapp/WEB-INF/lib
scp ./Ik-analyzer-solr5-5.x.jar solr@10.1.202.68:/opt/solr-5.5.0/server/solr-webapp/webapp/WEB-INF/lib
scp ./Ik-analyzer-solr5-5.x.jar solr@10.1.202.69:/opt/solr-5.5.0/server/solr-webapp/webapp/WEB-INF/lib
scp ./Ik-analyzer-solr5-5.x.jar solr@10.1.202.70:/opt/solr-5.5.0/server/solr-webapp/webapp/WEB-INF/lib
scp ./Ik-analyzer-solr5-5.x.jar solr@10.1.202.71:/opt/solr-5.5.0/server/solr-webapp/webapp/WEB-INF/lib3.managed-schema修改
solr5.5.0版本已经没有schema.xml的文件,替代用的是managed-schema,在solr-5.5.0/server/solr/configsets/目录下,在此目录下复制sample_techproducts_configs文件夹,命令如下:
cp sample_techproducts_configs poc_configs
编辑poc_configs/conf/managed-schema 增加ik分词字段类型和ik分词字段
vim managed-schema
<fields>
<field name="title_ik" type="text_general" indexed="true" stored="true"/>
<field name="content_ik" type="text_ik" indexed="true" stored="false"/>
<field name="content_outline" type="text_general" indexed="false" stored="true"/>
</fields>
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" useSmart="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" useSmart="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>注:content_ik字段太长,不能够存储文件,只能生产索引,也没有必要存储原文,导致数据量加大,搜索可能会受影响,内容的前50个字段截取出来存储到content_outline,方便查看内容的大致内容
重启solr服务器
./solr_stop_all.sh
#!/bin/bash
PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin
slaves="dn-1 dn-2 dn-3 dn-4 dn-5"
cmd="/opt/solr-5.5.0/bin/solr stop"
for slave in $slaves
do
echo $slave
ssh $slave $cmd
done./solr_start_all.sh
#!/bin/bash
PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin
slaves="dn-1 dn-2 dn-3 dn-4 dn-5"
cmd="/opt/solr-5.5.0/bin/solr start"
for slave in $slaves
do
echo $slave
ssh $slave $cmd
done分词测试
使用text_ik分词:
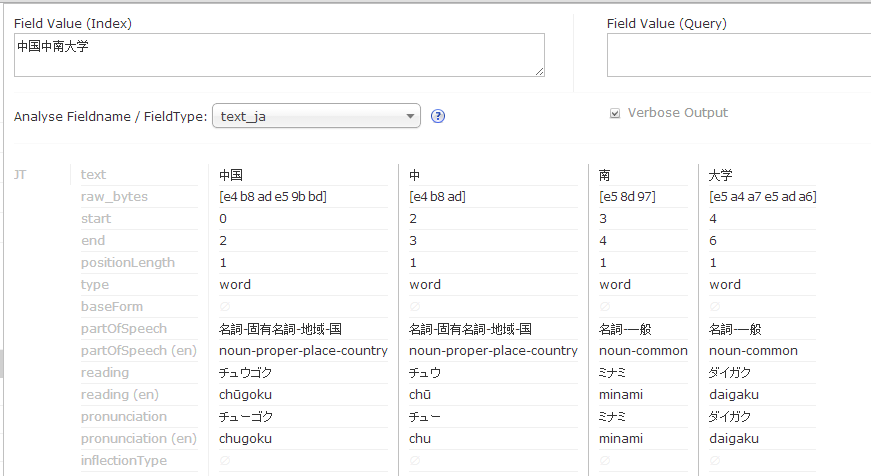
- 创建collection
编辑完成后可以创建collection,命令如下:
/opt/solr-5.5.0/bin/solr create -c collection1 -d /opt/solr-5.5.0/server/solr/configsets/poc_configs/conf -shards 5 -replicationFactor 2
创建完成后在访问页面出现一下内容:
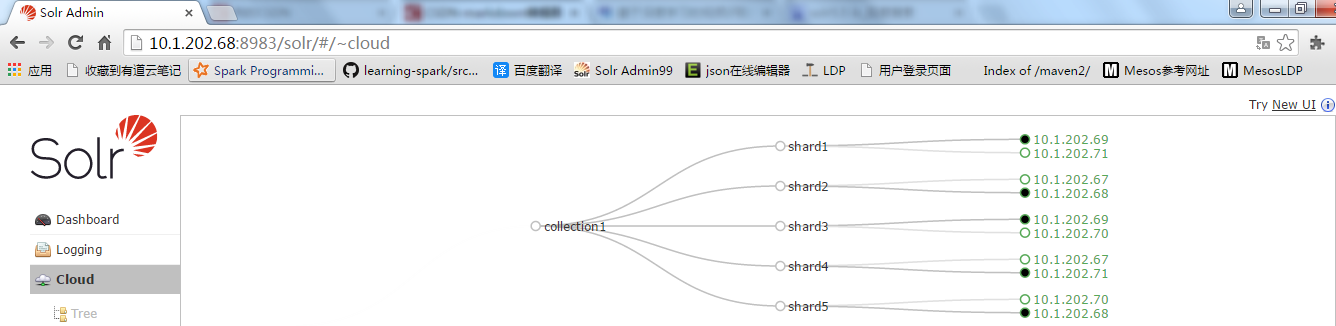
配置文件并不会生成到solr目录下,而是增加到zookeeper上
连接zookeeper
/opt/zookeeper-3.4.6/bin/zkCli.sh -server 10.1.202.67:9983

当创建失败collection时,可以通过命令删除,命令如下:
/opt/solr-5.5.0/bin/solr delete -c collection1 -deleteConfig true
注:-deleteConfig true是删除zookeeper上的配置文件,防止下次创建时直接用此配置项或者报错
如果还是不行,那说明zookeeper上的配置文件没有删除,直接登录zookeeper,通过rmr /configs/collection1命令删除配置项。编写solrCloud通过mapreduce读取hbase的字段生成索引
主方法:
public class SolrHBaseMoreIndexer {
public static Logger logger = LoggerFactory.getLogger(SolrHBaseMoreIndexer.class);
private static void hadoopRun(String[] args){
String tbName = ConfigProperties.getHBASE_TABLE_NAME();
try {
Job job = new Job(ConfigProperties.getConf(), "SolrHBaseMoreIndexer");
job.setJarByClass(SolrHBaseMoreIndexer.class);
Scan scan = new Scan();
//开始和结束并不是ID,而是hbase的rowkey,rowkey是通过数字排序,而是通过字符串进行排序,所 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1946
1946

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









