






原文地址:How to avoid the Top 5 SharePoint Performance Mistakes
目前SharePoint毫无疑问是一个快速发展的平台,微软真是赚了不少钱。SharePoint从一个小的列表和文档管理系统,发展到一个拥有自己的数据库,基于ASP.NET技术并提供API的开发平台,也不过用了大概十年的时间。
很多年过去了,很多东西都变了,但是也有一些东西没有改变,例如SharePoint还是把所有的items都保存在数据库中的一个表中。因此引发了第一个性能问题:
#1:遍历list中的items
获取SPList对象 有两种方式,要么使用当前的SPContext对象,要么使用list的名字创建一个SPList对象。SPList对象有一个Items属性,这个属性返回一个SPListItemCollection对象,下面的代码从SPList对象中获取前100条item,然后将它们的Title打印出来:
SPList activeList = SPContext.Current.List;
for(int i=0;i<100 && i<activeList.Items.Count;i++) {
SPListItem listItem = activeList.Items[i];
htmlWriter.Write(listItem["Title"]);
}看上去不错?尽管上面的代码可以正常工作,但是这样的代码是头号性能杀手。问题出在获取Items属性的方式。Items属性从内容数据库中查询所有的item,每当访问一次Items属性,就要查询一次,而且,查询出来的item,没有缓存起来。在代码的循环体中,每次循环我们都要访问这个属性两次!一次用来获取item的数量,另一个使用索引获得item。分析具体的SQL语句,可以看到下面的结果:

(这张图说明在上面的代码的执行过程中,会执行200次SQL查询)
问题:重复执行SQL查询,以上面的代码为例,200次SQL查询耗费了1秒多的时间。
解决方法:很简单,先把Items取出并保存在一个变量中,然后使用这个变量:
SPListItemCollection items = SPContext.Current.List.Items;
for(int i=0;i<100 && i<items.Count;i++) {
SPListItem listItem = items[i];
htmlWriter.Write(listItem["Title"]);
}
#2:向内容数据库请求过多的数据
如果我们仔细看上面的截图,就可以发现,通过Items属性来获取item,最终转换成的SQL语句是SELECT TOP 2147483648... ,并且返回了SPList中定义的所有的column的值。但是这些数据,我们大部分是用不上的。很多开发人员都没有意识到,其实使用一个SPQuery对象,就可以获取真正需要的数据。SPQuery对象可以:
a) 限制返回的item数量
b) 限制返回的column数量
c) 使用CAML返回指定的item
先说第一个,限制返回的item数量。如果我只想获取list中的前100条item,例如使用分页,每页100条数据,就可以使用SPQuery的RowLlimit和ListItemCollectionPosition属性,在这里Page through SharePoint lists可以找到完整的代码示例:
SPQuery query = new SPQuery();
query.RowLimit = 100; // 只获取前100条item
query.ListItemCollectionPosition = prevItems.ListItemCollectionPosition; // 从上一个位置开始
SPListItemCollection items = SPContext.Current.List.GetItems(query);

再说第二个,限制返回column的数量。如果只想获取需要的column,你可以使用SPQuery.ViewFields属性。默认情况下,SharePoint会返回list中所有的column,这就造成了数据库、带宽和内存的额外负担,下面的代码通过ViewFields属性,只获取ID,Text Field和XZY这三个column的数据:
SPQuery query = new SPQuery();
query.ViewFields = "<FieldRef Name='ID'/><FieldRef Name='Text Field'/><FieldRef Name='XYZ'/>";
//译者注:虽然指定了三个column,但是这段代码还是会获取额外的一些column返回,如果只返回这三个column的数据,需要指定 query.ViewFieldsOnly = true;
下面是不使用ViewFields和使用ViewFields的SQL查询语句对比:
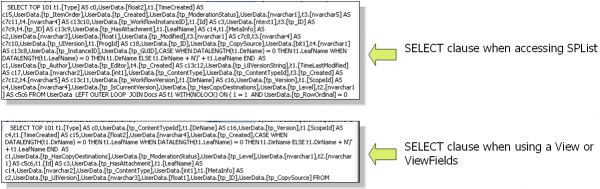
最后一个,使用CAML返回指定的item。CAML允许你精确的指定返回哪些数据。我们需要指定一个类似于SQL中的WHERE语句的字符串,例如我们需要获取ID为15的item,可以使用下面的方法:
SPQuery query = new SPQuery();
query.Query = “<Where><Eq><FieldRef Name=\”ID\”/><Value Type=\”Number\”>15</Value></Eq></Where>”;
问题:开发者通常使用最方便的方法来获取数据,但往往获取了过多的,不需要的数据。
解决方法:使用SPQuery对象和它的属性来减少不必要的数据。
了解更多:Only request the data you really need and Page through SharePoint lists
#3:SPSite和SPWeb可能导致内存泄露
在开头的时候我说过“很多东西都变了,但是也有一些东西没有改变”,SharePoint的一些核心功能,仍旧使用COM组件。倒不是说COM组件有什么问题,但是现在都是托管代码的时代了,使用COM组件就需要释放资源。SPSite和SPWeb对象都包含COM对象的引用,因此用完之后一定记得显式的释放掉。
问题:没有正确释放SPSite和SPWeb对象的后果就是内存泄露,最终导致内存不足,只能重启IIS。重启IIS意味着所有的session丢失,页面缓存丢失,用户重新打开页面会变慢。
解决方法:使用工具来检测哪些对象导致的内存泄露,对于SPSite和SPWeb对象,可以参考最佳实践,微软也提供了一个工具来检测你的代码:SPDisposeCheck。
下面的截图显示了使用synaTrace检测到的内存泄露情况:
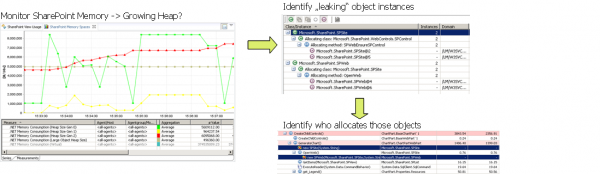
了解更多:identifying memory problems introduced by custom code
#4:使用索引未必会提高性能
在我刚刚开始研究SharePoint的时候,就发现了一些“有趣”的东西,例如使用一个数据库表来存储所有的item,然后告诉我们可以定义一些索引来优化性能,感觉有点儿奇怪。但是事实就是这样的,如果我们到内容数据库中查看“AllUserData”这个表,你会看到这个表确实包含所有可能的column,例如有64个nvarchar,16个int, 12个floats...
如果你在你的“My SharePoint list 1”的第一个column上定义了一个索引,在了另一个列表“My SharePoint List 2”的第二个column上定义了索引,以此类推,最后你的内容数据库中会充斥着索引。关于索引和AllUserData表,可以参考这个:SharePoint: List Performance - How list column indices really work under the hood
问题:索引column可以提高访问SharePoint列表的速度,但是,由于SharePoint的数据库设计,索引有以下的限制:
a) 对每一个索引,SharePoint将每个item的索引值保存在其他的表中,如果一个表有10000个item,那么SharePoint会在AllUserData中保存10000条记录,外加NameValuePair表中的10000条记录(索引值)。
b) SharePoint查询(CAML)只用第一个索引column,其他的索引column不会提高访问数据库的速度。
解决方法:仔细的考察你的索引列。他们真正有用的地方是在lookup其他列的时候。不要过度的使用索引。
#5:SharePoint不是一个为了处理高容量事务(high volume transactional processing)而设计的数据库。
我发现很多公司都会犯一个错误:认为SharePoint是地球上最灵活的数据库,他们可以随心所欲的定义和修改list,一点儿也不考虑数据库的感受。因此将SharePoint的内容数据库当作一个普通的关系数据库使用。
问题:如果你认真的阅读了以上4个问题,那么你应该认识到SharePoint不是一个真正的关系数据库,更不应该高容量的事务处理。所有的数据都保存在一个数据库表中,数据库的索引保存在另外的表中,使用的时候两个表还会来个join。因此并行访问list是一个问题,因为所有的数据都来自同一个表。
解决方法:在开始SharePoint项目之前,认真的考虑一下你的数据存储 - 这些数据会被频繁的访问吗?多少用户可能会同时修改数据?如果你有很多经常被修改的item,你应该考虑使用你自己的关系数据库。SharePoint的一个伟大之处也在于,如果你不想使用内容数据库,你可以使用外部的数据库。
了解更多:Monitoring individual List usage and performance,还有一个:How list column indices really work under the hood
总结一下:以上这些我接触SharePoint两年来的一些经验总结。我已经在很多的会议上,跟不同的公司分享过这些可以提高SharePoint性能的经验。希望能够帮到你们。














 1808
1808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









