In this tutorial I will describe the required steps for setting up a pseudo-distributed, single-nodeHadoop cluster backed by the Hadoop Distributed File System, running on Ubuntu Linux.
Hadoop is a framework written in Java for running applications on large clusters of commodity hardware and incorporates features similar to those of the Google File System (GFS) and of the MapReduce computing paradigm. Hadoop’s HDFS is a highly fault-tolerant distributed file system and, like Hadoop in general, designed to be deployed on low-cost hardware. It provides high throughput access to application data and is suitable for applications that have large data sets.
The main goal of this tutorial is to get a simple Hadoop installation up and running so that you can play around with the software and learn more about it.
This tutorial has been tested with the following software versions:
- Ubuntu Linux 10.04 LTS (deprecated: 8.10 LTS, 8.04, 7.10, 7.04)
- Hadoop 1.0.3, released May 2012

Figure 1: Cluster of machines running Hadoop at Yahoo! (Source: Yahoo!)
Prerequisites
Sun Java 6
Hadoop requires a working Java 1.5+ (aka Java 5) installation. However, using Java 1.6 (aka Java 6) is recommended for running Hadoop. For the sake of this tutorial, I will therefore describe the installation of Java 1.6.
Important Note: The apt instructions below are taken from
this SuperUser.com thread. I got notified that the previous instructions that I provided no longer work. Please be aware that adding a third-party repository to your Ubuntu configuration is considered a security risk. If you do not want to proceed with the apt instructions below, feel free to install Sun JDK 6 via alternative means (e.g. by
downloading the binary package from Oracle) and then continue with the next section in the tutorial.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| # Add the Ferramosca Roberto's repository to your apt repositories
# See https://launchpad.net/~ferramroberto/
#
$ sudo apt-get install python-software-properties
$ sudo add-apt-repository ppa:ferramroberto/java
# Update the source list
$ sudo apt-get update
# Install Sun Java 6 JDK
$ sudo apt-get install sun-java6-jdk
# Select Sun's Java as the default on your machine.
# See 'sudo update-alternatives --config java' for more information.
#
$ sudo update-java-alternatives -s java-6-sun
|
The full JDK which will be placed in /usr/lib/jvm/java-6-sun (well, this directory is actually a symlink on Ubuntu).
After installation, make a quick check whether Sun’s JDK is correctly set up:
1
2
3
4
| user@ubuntu:~# java -version
java version "1.6.0_20"
Java(TM) SE Runtime Environment (build 1.6.0_20-b02)
Java HotSpot(TM) Client VM (build 16.3-b01, mixed mode, sharing)
|
Adding a dedicated Hadoop system user
We will use a dedicated Hadoop user account for running Hadoop. While that’s not required it is recommended because it helps to separate the Hadoop installation from other software applications and user accounts running on the same machine (think: security, permissions, backups, etc).
1
2
| $ sudo addgroup hadoop
$ sudo adduser --ingroup hadoop hduser
|
This will add the user hduser and the group hadoop to your local machine.
Configuring SSH
Hadoop requires SSH access to manage its nodes, i.e. remote machines plus your local machine if you want to use Hadoop on it (which is what we want to do in this short tutorial). For our single-node setup of Hadoop, we therefore need to configure SSH access to localhost for the hduseruser we created in the previous section.
I assume that you have SSH up and running on your machine and configured it to allow SSH public key authentication. If not, there are several online guides available.
First, we have to generate an SSH key for the hduser user.
1
2
3
4
5
6
7
8
9
10
11
12
| user@ubuntu:~$ su - hduser
hduser@ubuntu:~$ ssh-keygen -t rsa -P ""
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hduser/.ssh/id_rsa):
Created directory '/home/hduser/.ssh'.
Your identification has been saved in /home/hduser/.ssh/id_rsa.
Your public key has been saved in /home/hduser/.ssh/id_rsa.pub.
The key fingerprint is:
9b:82:ea:58:b4:e0:35:d7:ff:19:66:a6:ef:ae:0e:d2 hduser@ubuntu
The key's randomart image is:
[...snipp...]
hduser@ubuntu:~$
|
The second line will create an RSA key pair with an empty password. Generally, using an empty password is not recommended, but in this case it is needed to unlock the key without your interaction (you don’t want to enter the passphrase every time Hadoop interacts with its nodes).
Second, you have to enable SSH access to your local machine with this newly created key.
1
| hduser@ubuntu:~$ cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
|
The final step is to test the SSH setup by connecting to your local machine with the hduser user. The step is also needed to save your local machine’s host key fingerprint to the hduser user’s known_hosts file. If you have any special SSH configuration for your local machine like a non-standard SSH port, you can define host-specific SSH options in $HOME/.ssh/config (see man ssh_config for more information).
1
2
3
4
5
6
7
8
9
| hduser@ubuntu:~$ ssh localhost
The authenticity of host 'localhost (::1)' can't be established.
RSA key fingerprint is d7:87:25:47:ae:02:00:eb:1d:75:4f:bb:44:f9:36:26.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'localhost' (RSA) to the list of known hosts.
Linux ubuntu 2.6.32-22-generic #33-Ubuntu SMP Wed Apr 28 13:27:30 UTC 2010 i686 GNU/Linux
Ubuntu 10.04 LTS
[...snipp...]
hduser@ubuntu:~$
|
If the SSH connect should fail, these general tips might help:
- Enable debugging with
ssh -vvv localhost and investigate the error in detail. - Check the SSH server configuration in
/etc/ssh/sshd_config, in particular the options PubkeyAuthentication (which should be set to yes) and AllowUsers (if this option is active, add the hduser user to it). If you made any changes to the SSH server configuration file, you can force a configuration reload with sudo /etc/init.d/ssh reload.
Disabling IPv6
One problem with IPv6 on Ubuntu is that using 0.0.0.0 for the various networking-related Hadoop configuration options will result in Hadoop binding to the IPv6 addresses of my Ubuntu box. In my case, I realized that there’s no practical point in enabling IPv6 on a box when you are not connected to any IPv6 network. Hence, I simply disabled IPv6 on my Ubuntu machine. Your mileage may vary.
To disable IPv6 on Ubuntu 10.04 LTS, open /etc/sysctl.conf in the editor of your choice and add the following lines to the end of the file:
/etc/sysctl.conf
1
2
3
4
| # disable ipv6
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
net.ipv6.conf.lo.disable_ipv6 = 1
|
You have to reboot your machine in order to make the changes take effect.
You can check whether IPv6 is enabled on your machine with the following command:
1
| $ cat /proc/sys/net/ipv6/conf/all/disable_ipv6
|
A return value of 0 means IPv6 is enabled, a value of 1 means disabled (that’s what we want).
Alternative
You can also disable IPv6 only for Hadoop as documented in HADOOP-3437. You can do so by adding the following line to conf/hadoop-env.sh:
conf/hadoop-env.sh
1
| export HADOOP_OPTS=-Djava.net.preferIPv4Stack=true
|
Hadoop
Installation
Download Hadoop from the Apache Download Mirrors and extract the contents of the Hadoop package to a location of your choice. I picked /usr/local/hadoop. Make sure to change the owner of all the files to the hduser user and hadoop group, for example:
1
2
3
4
| $ cd /usr/local
$ sudo tar xzf hadoop-1.0.3.tar.gz
$ sudo mv hadoop-1.0.3 hadoop
$ sudo chown -R hduser:hadoop hadoop
|
(Just to give you the idea, YMMV – personally, I create a symlink from hadoop-1.0.3 to hadoop.)
Update $HOME/.bashrc
Add the following lines to the end of the $HOME/.bashrc file of user hduser. If you use a shell other than bash, you should of course update its appropriate configuration files instead of .bashrc.
$HOME/.bashrc
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| # Set Hadoop-related environment variables
export HADOOP_HOME=/usr/local/hadoop
# Set JAVA_HOME (we will also configure JAVA_HOME directly for Hadoop later on)
export JAVA_HOME=/usr/lib/jvm/java-6-sun
# Some convenient aliases and functions for running Hadoop-related commands
unalias fs &> /dev/null
alias fs="hadoop fs"
unalias hls &> /dev/null
alias hls="fs -ls"
# If you have LZO compression enabled in your Hadoop cluster and
# compress job outputs with LZOP (not covered in this tutorial):
# Conveniently inspect an LZOP compressed file from the command
# line; run via:
#
# $ lzohead /hdfs/path/to/lzop/compressed/file.lzo
#
# Requires installed 'lzop' command.
#
lzohead () {
hadoop fs -cat $1 | lzop -dc | head -1000 | less
}
# Add Hadoop bin/ directory to PATH
export PATH=$PATH:$HADOOP_HOME/bin
|
You can repeat this exercise also for other users who want to use Hadoop.
Excursus: Hadoop Distributed File System (HDFS)
Before we continue let us briefly learn a bit more about Hadoop’s distributed file system.
The Hadoop Distributed File System (HDFS) is a distributed file system designed to run on commodity hardware. It has many similarities with existing distributed file systems. However, the differences from other distributed file systems are significant. HDFS is highly fault-tolerant and is designed to be deployed on low-cost hardware. HDFS provides high throughput access to application data and is suitable for applications that have large data sets. HDFS relaxes a few POSIX requirements to enable streaming access to file system data. HDFS was originally built as infrastructure for the Apache Nutch web search engine project. HDFS is part of the Apache Hadoop project, which is part of the Apache Lucene project.
The Hadoop Distributed File System: Architecture and Design
hadoop.apache.org/hdfs/docs/…
The following picture gives an overview of the most important HDFS components.
")
Configuration
Our goal in this tutorial is a single-node setup of Hadoop. More information of what we do in this section is available on the Hadoop Wiki.
hadoop-env.sh
The only required environment variable we have to configure for Hadoop in this tutorial is JAVA_HOME. Open conf/hadoop-env.sh in the editor of your choice (if you used the installation path in this tutorial, the full path is /usr/local/hadoop/conf/hadoop-env.sh) and set the JAVA_HOME environment variable to the Sun JDK/JRE 6 directory.
Change
find .|xargs grep -ri "IBM" -l
conf/hadoop-env.sh
1
2
| # The java implementation to use. Required.
# export JAVA_HOME=/usr/lib/j2sdk1.5-sun
|
to
conf/hadoop-env.sh
1
2
| # The java implementation to use. Required.
export JAVA_HOME=/usr/lib/jvm/java-6-sun
|
Note: If you are on a Mac with OS X 10.7 you can use the following line to set up JAVA_HOME in conf/hadoop-env.sh.
conf/hadoop-env.sh (on Mac systems)
1
2
| # for our Mac users
export JAVA_HOME=`/usr/libexec/java_home`
|
conf/*-site.xml
In this section, we will configure the directory where Hadoop will store its data files, the network ports it listens to, etc. Our setup will use Hadoop’s Distributed File System, HDFS, even though our little “cluster” only contains our single local machine.
You can leave the settings below “as is” with the exception of the hadoop.tmp.dir parameter – this parameter you must change to a directory of your choice. We will use the directory /app/hadoop/tmp in this tutorial. Hadoop’s default configurations use hadoop.tmp.dir as the base temporary directory both for the local file system and HDFS, so don’t be surprised if you see Hadoop creating the specified directory automatically on HDFS at some later point.
Now we create the directory and set the required ownerships and permissions:
1
2
3
4
| $ sudo mkdir -p /app/hadoop/tmp
$ sudo chown hduser:hadoop /app/hadoop/tmp
# ...and if you want to tighten up security, chmod from 755 to 750...
$ sudo chmod 750 /app/hadoop/tmp
|
If you forget to set the required ownerships and permissions, you will see a java.io.IOExceptionwhen you try to format the name node in the next section).
Add the following snippets between the <configuration> ... </configuration> tags in the respective configuration XML file.
In file conf/core-site.xml:
conf/core-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| <property>
<name>hadoop.tmp.dir</name>
<value>/app/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:54310</value>
<description>The name of the default file system. A URI whose
scheme and authority determine the FileSystem implementation. The
uri's scheme determines the config property (fs.SCHEME.impl) naming
the FileSystem implementation class. The uri's authority is used to
determine the host, port, etc. for a filesystem.</description>
</property>
|
In file conf/mapred-site.xml:
conf/mapred-site.xml
1
2
3
4
5
6
7
8
| <property>
<name>mapred.job.tracker</name>
<value>localhost:54311</value>
<description>The host and port that the MapReduce job tracker runs
at. If "local", then jobs are run in-process as a single map
and reduce task.
</description>
</property>
|
In file conf/hdfs-site.xml:
conf/hdfs-site.xml
1
2
3
4
5
6
7
8
| <property>
<name>dfs.replication</name>
<value>1</value>
<description>Default block replication.
The actual number of replications can be specified when the file is created.
The default is used if replication is not specified in create time.
</description>
</property>
|
See Getting Started with Hadoop and the documentation in Hadoop’s API Overview if you have any questions about Hadoop’s configuration options.
The first step to starting up your Hadoop installation is formatting the Hadoop filesystem which is implemented on top of the local filesystem of your “cluster” (which includes only your local machine if you followed this tutorial). You need to do this the first time you set up a Hadoop cluster.
Do not format a running Hadoop filesystem as you will lose all the data currently in the cluster (in HDFS)!
To format the filesystem (which simply initializes the directory specified by the dfs.name.dirvariable), run the command
1
| hduser@ubuntu:~$ /usr/local/hadoop/bin/hadoop namenode -format
|
The output will look like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| hduser@ubuntu:/usr/local/hadoop$ bin/hadoop namenode -format
10/05/08 16:59:56 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = ubuntu/127.0.1.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 0.20.2
STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-0.20 -r 911707; compiled by 'chrisdo' on Fri Feb 19 08:07:34 UTC 2010
************************************************************/
10/05/08 16:59:56 INFO namenode.FSNamesystem: fsOwner=hduser,hadoop
10/05/08 16:59:56 INFO namenode.FSNamesystem: supergroup=supergroup
10/05/08 16:59:56 INFO namenode.FSNamesystem: isPermissionEnabled=true
10/05/08 16:59:56 INFO common.Storage: Image file of size 96 saved in 0 seconds.
10/05/08 16:59:57 INFO common.Storage: Storage directory .../hadoop-hduser/dfs/name has been successfully formatted.
10/05/08 16:59:57 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at ubuntu/127.0.1.1
************************************************************/
hduser@ubuntu:/usr/local/hadoop$
|
Starting your single-node cluster
Run the command:
1
| hduser@ubuntu:~$ /usr/local/hadoop/bin/start-all.sh
|
This will startup a Namenode, Datanode, Jobtracker and a Tasktracker on your machine.
The output will look like this:
1
2
3
4
5
6
7
| hduser@ubuntu:/usr/local/hadoop$ bin/start-all.sh
starting namenode, logging to /usr/local/hadoop/bin/../logs/hadoop-hduser-namenode-ubuntu.out
localhost: starting datanode, logging to /usr/local/hadoop/bin/../logs/hadoop-hduser-datanode-ubuntu.out
localhost: starting secondarynamenode, logging to /usr/local/hadoop/bin/../logs/hadoop-hduser-secondarynamenode-ubuntu.out
starting jobtracker, logging to /usr/local/hadoop/bin/../logs/hadoop-hduser-jobtracker-ubuntu.out
localhost: starting tasktracker, logging to /usr/local/hadoop/bin/../logs/hadoop-hduser-tasktracker-ubuntu.out
hduser@ubuntu:/usr/local/hadoop$
|
A nifty tool for checking whether the expected Hadoop processes are running is jps (part of Sun’s Java since v1.5.0). See also How to debug MapReduce programs.
1
2
3
4
5
6
7
| hduser@ubuntu:/usr/local/hadoop$ jps
2287 TaskTracker
2149 JobTracker
1938 DataNode
2085 SecondaryNameNode
2349 Jps
1788 NameNode
|
You can also check with netstat if Hadoop is listening on the configured ports.
1
2
3
4
5
6
7
8
9
10
11
12
| hduser@ubuntu:~$ sudo netstat -plten | grep java
tcp 0 0 0.0.0.0:50070 0.0.0.0:* LISTEN 1001 9236 2471/java
tcp 0 0 0.0.0.0:50010 0.0.0.0:* LISTEN 1001 9998 2628/java
tcp 0 0 0.0.0.0:48159 0.0.0.0:* LISTEN 1001 8496 2628/java
tcp 0 0 0.0.0.0:53121 0.0.0.0:* LISTEN 1001 9228 2857/java
tcp 0 0 127.0.0.1:54310 0.0.0.0:* LISTEN 1001 8143 2471/java
tcp 0 0 127.0.0.1:54311 0.0.0.0:* LISTEN 1001 9230 2857/java
tcp 0 0 0.0.0.0:59305 0.0.0.0:* LISTEN 1001 8141 2471/java
tcp 0 0 0.0.0.0:50060 0.0.0.0:* LISTEN 1001 9857 3005/java
tcp 0 0 0.0.0.0:49900 0.0.0.0:* LISTEN 1001 9037 2785/java
tcp 0 0 0.0.0.0:50030 0.0.0.0:* LISTEN 1001 9773 2857/java
hduser@ubuntu:~$
|
If there are any errors, examine the log files in the /logs/ directory.
Stopping your single-node cluster
Run the command
1
| hduser@ubuntu:~$ /usr/local/hadoop/bin/stop-all.sh
|
to stop all the daemons running on your machine.
Example output:
1
2
3
4
5
6
7
| hduser@ubuntu:/usr/local/hadoop$ bin/stop-all.sh
stopping jobtracker
localhost: stopping tasktracker
stopping namenode
localhost: stopping datanode
localhost: stopping secondarynamenode
hduser@ubuntu:/usr/local/hadoop$
|
Running a MapReduce job
We will now run your first Hadoop MapReduce job. We will use the WordCount example job which reads text files and counts how often words occur. The input is text files and the output is text files, each line of which contains a word and the count of how often it occurred, separated by a tab. More information of what happens behind the scenes is available at the Hadoop Wiki.
We will use three ebooks from Project Gutenberg for this example:
Download each ebook as text files in Plain Text UTF-8 encoding and store the files in a local temporary directory of choice, for example /tmp/gutenberg.
1
2
3
4
5
6
| hduser@ubuntu:~$ ls -l /tmp/gutenberg/
total 3604
-rw-r--r-- 1 hduser hadoop 674566 Feb 3 10:17 pg20417.txt
-rw-r--r-- 1 hduser hadoop 1573112 Feb 3 10:18 pg4300.txt
-rw-r--r-- 1 hduser hadoop 1423801 Feb 3 10:18 pg5000.txt
hduser@ubuntu:~$
|
Restart the Hadoop cluster
Restart your Hadoop cluster if it’s not running already.
1
| hduser@ubuntu:~$ /usr/local/hadoop/bin/start-all.sh
|
Copy local example data to HDFS
Before we run the actual MapReduce job, we first have to copy the files from our local file system to Hadoop’s HDFS.
1
2
3
4
5
6
7
8
9
10
| hduser@ubuntu:/usr/local/hadoop$ bin/hadoop dfs -copyFromLocal /tmp/gutenberg /user/hduser/gutenberg
hduser@ubuntu:/usr/local/hadoop$ bin/hadoop dfs -ls /user/hduser
Found 1 items
drwxr-xr-x - hduser supergroup 0 2010-05-08 17:40 /user/hduser/gutenberg
hduser@ubuntu:/usr/local/hadoop$ bin/hadoop dfs -ls /user/hduser/gutenberg
Found 3 items
-rw-r--r-- 3 hduser supergroup 674566 2011-03-10 11:38 /user/hduser/gutenberg/pg20417.txt
-rw-r--r-- 3 hduser supergroup 1573112 2011-03-10 11:38 /user/hduser/gutenberg/pg4300.txt
-rw-r--r-- 3 hduser supergroup 1423801 2011-03-10 11:38 /user/hduser/gutenberg/pg5000.txt
hduser@ubuntu:/usr/local/hadoop$
|
Run the MapReduce job
Now, we actually run the WordCount example job.
1
| hduser@ubuntu:/usr/local/hadoop$ bin/hadoop jar hadoop*examples*.jar wordcount /user/hduser/gutenberg /user/hduser/gutenberg-output
|
This command will read all the files in the HDFS directory /user/hduser/gutenberg, process it, and store the result in the HDFS directory /user/hduser/gutenberg-output.
Note: Some people run the command above and get the following error message:
Exception in thread "main" java.io.IOException: Error opening job jar: hadoop*examples*.jar
at org.apache.hadoop.util.RunJar.main (RunJar.java: 90)
Caused by: java.util.zip.ZipException: error in opening zip file
In this case, re-run the command with the full name of the Hadoop Examples JAR file, for example:
hduser@ubuntu:/usr/local/hadoop$ bin/hadoop jar hadoop-examples-1.0.3.jar wordcount /user/hduser/gutenberg /user/hduser/gutenberg-output
Example output of the previous command in the console:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| hduser@ubuntu:/usr/local/hadoop$ bin/hadoop jar hadoop*examples*.jar wordcount /user/hduser/gutenberg /user/hduser/gutenberg-output
10/05/08 17:43:00 INFO input.FileInputFormat: Total input paths to process : 3
10/05/08 17:43:01 INFO mapred.JobClient: Running job: job_201005081732_0001
10/05/08 17:43:02 INFO mapred.JobClient: map 0% reduce 0%
10/05/08 17:43:14 INFO mapred.JobClient: map 66% reduce 0%
10/05/08 17:43:17 INFO mapred.JobClient: map 100% reduce 0%
10/05/08 17:43:26 INFO mapred.JobClient: map 100% reduce 100%
10/05/08 17:43:28 INFO mapred.JobClient: Job complete: job_201005081732_0001
10/05/08 17:43:28 INFO mapred.JobClient: Counters: 17
10/05/08 17:43:28 INFO mapred.JobClient: Job Counters
10/05/08 17:43:28 INFO mapred.JobClient: Launched reduce tasks=1
10/05/08 17:43:28 INFO mapred.JobClient: Launched map tasks=3
10/05/08 17:43:28 INFO mapred.JobClient: Data-local map tasks=3
10/05/08 17:43:28 INFO mapred.JobClient: FileSystemCounters
10/05/08 17:43:28 INFO mapred.JobClient: FILE_BYTES_READ=2214026
10/05/08 17:43:28 INFO mapred.JobClient: HDFS_BYTES_READ=3639512
10/05/08 17:43:28 INFO mapred.JobClient: FILE_BYTES_WRITTEN=3687918
10/05/08 17:43:28 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=880330
10/05/08 17:43:28 INFO mapred.JobClient: Map-Reduce Framework
10/05/08 17:43:28 INFO mapred.JobClient: Reduce input groups=82290
10/05/08 17:43:28 INFO mapred.JobClient: Combine output records=102286
10/05/08 17:43:28 INFO mapred.JobClient: Map input records=77934
10/05/08 17:43:28 INFO mapred.JobClient: Reduce shuffle bytes=1473796
10/05/08 17:43:28 INFO mapred.JobClient: Reduce output records=82290
10/05/08 17:43:28 INFO mapred.JobClient: Spilled Records=255874
10/05/08 17:43:28 INFO mapred.JobClient: Map output bytes=6076267
10/05/08 17:43:28 INFO mapred.JobClient: Combine input records=629187
10/05/08 17:43:28 INFO mapred.JobClient: Map output records=629187
10/05/08 17:43:28 INFO mapred.JobClient: Reduce input records=102286
|
Check if the result is successfully stored in HDFS directory /user/hduser/gutenberg-output:
1
2
3
4
5
6
7
8
9
| hduser@ubuntu:/usr/local/hadoop$ bin/hadoop dfs -ls /user/hduser
Found 2 items
drwxr-xr-x - hduser supergroup 0 2010-05-08 17:40 /user/hduser/gutenberg
drwxr-xr-x - hduser supergroup 0 2010-05-08 17:43 /user/hduser/gutenberg-output
hduser@ubuntu:/usr/local/hadoop$ bin/hadoop dfs -ls /user/hduser/gutenberg-output
Found 2 items
drwxr-xr-x - hduser supergroup 0 2010-05-08 17:43 /user/hduser/gutenberg-output/_logs
-rw-r--r-- 1 hduser supergroup 880802 2010-05-08 17:43 /user/hduser/gutenberg-output/part-r-00000
hduser@ubuntu:/usr/local/hadoop$
|
If you want to modify some Hadoop settings on the fly like increasing the number of Reduce tasks, you can use the "-D" option:
1
| hduser@ubuntu:/usr/local/hadoop$ bin/hadoop jar hadoop*examples*.jar wordcount -D mapred.reduce.tasks=16 /user/hduser/gutenberg /user/hduser/gutenberg-output
|
An important note about
mapred.map.tasks:
Hadoop does not honor mapred.map.tasks beyond considering it a hint. But it accepts the user specified
mapred.reduce.tasks and doesn’t manipulate that. You cannot force
mapred.map.tasks but you can specify
mapred.reduce.tasks.
Retrieve the job result from HDFS
To inspect the file, you can copy it from HDFS to the local file system. Alternatively, you can use the command
1
| hduser@ubuntu:/usr/local/hadoop$ bin/hadoop dfs -cat /user/hduser/gutenberg-output/part-r-00000
|
to read the file directly from HDFS without copying it to the local file system. In this tutorial, we will copy the results to the local file system though.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| hduser@ubuntu:/usr/local/hadoop$ mkdir /tmp/gutenberg-output
hduser@ubuntu:/usr/local/hadoop$ bin/hadoop dfs -getmerge /user/hduser/gutenberg-output /tmp/gutenberg-output
hduser@ubuntu:/usr/local/hadoop$ head /tmp/gutenberg-output/gutenberg-output
"(Lo)cra" 1
"1490 1
"1498," 1
"35" 1
"40," 1
"A 2
"AS-IS". 1
"A_ 1
"Absoluti 1
"Alack! 1
hduser@ubuntu:/usr/local/hadoop$
|
Note that in this specific output the quote signs (“) enclosing the words in the head output above have not been inserted by Hadoop. They are the result of the word tokenizer used in the WordCount example, and in this case they matched the beginning of a quote in the ebook texts. Just inspect the part-00000 file further to see it for yourself.
The command fs -getmerge will simply concatenate any files it finds in the directory you specify. This means that the merged file might (and most likely will) not be sorted.
Hadoop Web Interfaces
Hadoop comes with several web interfaces which are by default (see conf/hadoop-default.xml) available at these locations:
These web interfaces provide concise information about what’s happening in your Hadoop cluster. You might want to give them a try.
NameNode Web Interface (HDFS layer)
The name node web UI shows you a cluster summary including information about total/remaining capacity, live and dead nodes. Additionally, it allows you to browse the HDFS namespace and view the contents of its files in the web browser. It also gives access to the local machine’s Hadoop log files.
By default, it’s available at http://localhost:50070/.

JobTracker Web Interface (MapReduce layer)
The JobTracker web UI provides information about general job statistics of the Hadoop cluster, running/completed/failed jobs and a job history log file. It also gives access to the ‘‘local machine’s’’ Hadoop log files (the machine on which the web UI is running on).
By default, it’s available at http://localhost:50030/.

TaskTracker Web Interface (MapReduce layer)
The task tracker web UI shows you running and non-running tasks. It also gives access to the ‘‘local machine’s’’ Hadoop log files.
By default, it’s available at http://localhost:50060/.

What’s next?
If you’re feeling comfortable, you can continue your Hadoop experience with my follow-up tutorial Running Hadoop On Ubuntu Linux (Multi-Node Cluster) where I describe how to build a Hadoop ‘‘multi-node’’ cluster with two Ubuntu boxes (this will increase your current cluster size by 100%, heh).
In addition, I wrote a tutorial on how to code a simple MapReduce job in the Python programming language which can serve as the basis for writing your own MapReduce programs.
From yours truly:
From other people:
Change Log
Only important changes to this article are listed here:
- 2011-07-17: Renamed the Hadoop user from
hadoop to hduser based on readers’ feedback. This should make the distinction between the local Hadoop user (now hduser), the local Hadoop group (hadoop), and the Hadoop CLI tool (hadoop) more clear.
Mahout integrates a lot of common machine learning algorithms which faciliates those who want to do some research in data mining. It is based on Java and a lot of need to be done before you can make it work. At least you will need JDK, Eclispse, Hadoop and Mahout. But I strongly recommend all those below to be done to make it better.
I JDK
II mysql
III Tomcat
IV Eclipse and MyEclipse
V Maven
VI Hadoop and Mahout
VII Test
VIII k-means Algorithm Test
I JDK

sudo gedit /etc/profile
#set java environment
JAVA_HOME=/home/lethic/Documents/Softwares/jdk1.7.0_21
export JRE_HOME=/home/lethic/Documents/Softwares/jdk1.7.0_21/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
Reboot

Test:vim hello.java
public class hello{
public static void main(String args[]){
System.out.println("Hello World!");
}
}
Javac hello.java
Java hello

II mysql
sudo apt-get install mysql-server my-client
And test:
sudo netstat -tap | grep mysql

A graphical tool is recommended. Search for mysql-admin in Synaptic and install it:


III Tomcat
http://mirror.bjtu.edu.cn/apache/tomcat/tomcat-7/v7.0.40/bin/
apache-tomcat-7.0.40.tar.gz


Add this:
JAVA_HOME=/home/lethic/Documents/Softwares/jdk1.7.0_21
JAVA_OPTS="-server -Xms512m -Xmx1024m -XX:PermSize=600M -XX:MaxPermSize=600m -Dcom.sun.management.jmxremote"
Infront of:
cygwin=false
os400=false
darwin=false
case "`uname`" in
CYGWIN*) cygwin=true;;
OS400*) os400=true;;
Darwin*) darwin=true;;

Add:
JAVA_HOME=/home/lethic/Documents/Softwares/jdk1.7.0_21
export JRE_HOME=/home/lethic/Documents/Softwares/jdk1.7.0_21/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
To the end

then
Type: localhost:8080 in your browser
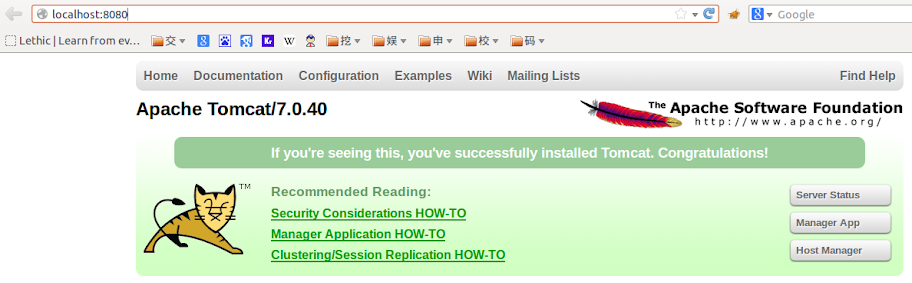
IV Eclipse and MyEclipse
http://www.eclipse.org/downloads/
I chose the fist one

Myeclipse:
Modify default jdk:
sudo update-alternatives --install "/usr/bin/java" "java" "/home/lethic/Documents/Softwares/jdk1.7.0_21/bin/java" 300
sudo update-alternatives --install "/usr/bin/javac" "javac" "/home/lethic/Documents/Softwares/jdk1.7.0_21/bin/javac" 300
sudo update-alternatives --install "/usr/bin/javaws" "javaws" "/home/lethic/Documents/Softwares/jdk1.7.0_21/bin/javaws" 300
sudo update-alternatives --config java
sudo update-alternatives --config javac
sudo update-alternatives --config javaws
Download:
http://www.myeclipseide.com/module-htmlpages-display-pid-4.html



Build a shortcut for MyEclipse
lethic@lethic:~/Documents/Softwares$ sudo chown -R root:root MyEclispse
lethic@lethic:~/Documents/Softwares$ sudo chmod -R +r MyEclispse
lethic@lethic:~/Documents/Softwares$ cd 'MyEclispse/MyEclipse 10/'
lethic@lethic:~/Documents/Softwares/MyEclispse/MyEclipse 10$ sudo chown -R root:root myeclipse
lethic@lethic:~/Documents/Softwares/MyEclispse/MyEclipse 10$ sudo chmod -R +r myeclipse
sudo gedit /usr/bin/MyEclipse
#!/bin/sh
export MYECLIPSE_HOME="/home/lethic/Documents/Softwares/MyEclispse/MyEclipse 10/myeclipse"
$MYECLIPSE_HOME/myeclipse $*
sudo chmod 755 /usr/bin/MyEclipse
sudo chmod -R 777 /home/lethic/Documents/Softwares/MyEclispse
sudo gedit /usr/share/applications/MyEclipse.desktop
[Desktop Entry]
Encoding=UTF-8
Name=MyEclipse 10
Comment=IDE for JavaEE
Exec=/home/lethic/Documents/Softwares/MyEclispse/MyEclipse\ 10/myeclipse
Icon=/home/lethic/Documents/Softwares/MyEclispse /MyEclipse\ 10/icon.xpm
Terminal=false
Type=Application
Categories=GNOME;Application;Development;
StartupNotify=true
Then initialize it:
'/usr/MyEclipse/MyEclipse 10/myeclipse' -clean
V Maven
Apache Maven 3.0.5
http://maven.apache.org/docs/3.0.5/release-notes.html
tar -xvzf apache-maven-3.0.5-bin.tar.gz
#create a link for it to make it easy to upgrade
ln -s apache-maven-3.0.5 apache-maven
#reboot and test

VI Hadoop and Mahout
Hadoop:
http://mirror.bit.edu.cn/apache/hadoop/common/stable/
hadoop-1.1.2.tar.gz
tar zxvf hadoop-1.1.2.tar.gzMahout:
http://mirror.bit.edu.cn/apache/mahout/0.6/
tar zxvf mahout-distribution-0.6.tar.gz
Add this to etc/profile
export HADOOP_HOME=/home/lethic/Documents/Softwares/hadoop-1.1.2
export HADOOP_CONF_DIR=/home/lethic/Documents/Softwares/hadoop-1.1.2/conf
export MAHOUT_HOME=/home/lethic/Documents/Softwares/mahout-distribution-0.6
export PATH=$HADOOP_HOME/bin:$MAHOUT_HOME/bin:$PATH
Then refresh the profile again:
source /etc/profile
VII Test
I modified my /etc/profile again and finally the part I added in is like this:
umask 022
#set java environment
#JAVA_HOME=/home/lethic/Documents/Softwares/jdk1.7.0_21
export JAVA_HOME=/home/lethic/Documents/Softwares/jdk1.7.0_21
export JRE_HOME=/home/lethic/Documents/Softwares/jdk1.7.0_21/jre
#export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
export GTK_IM_MODULE=ibus
export XMODIFIERS="@im=ibus"
export QT_IM_MODULE=ibus
export MAVEN_HOME=/home/lethic/Documents/Softwares/apache-maven-3.0.5
export HADOOP_HOME=/home/lethic/Documents/Softwares/hadoop-1.1.2
export HADOOP_CONF_DIR=/home/lethic/Documents/Softwares/hadoop-1.1.2/conf
export MAHOUT_HOME=/home/lethic/Documents/Softwares/mahout-distribution-0.6
export PATH=$JAVA_HOME/bin:$MAVEN_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin:$MAHOUT_HOME/bin:$PATH
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export HADOOP_HOME_WARN_SUPPRESS=1
NOTICE that all the “/home/lethic/Documents/Softwares/” should be changed to your own path.
TEST:
Java:

javac

Remember to add this to etc/profile or it will show some warning:
export HADOOP_HOME_WARN_SUPPRESS=1
Hadoop:
Mahout:

It says that: MAHOUT_LOCAL is not set; adding HADOOP_CONF_DIR to classpath
I think this not a kind of error because when you refer to mahout, it contains:
if [ "$MAHOUT_LOCAL" != "" ]; then
echo "MAHOUT_LOCAL is set, so we don't add HADOOP_CONF_DIR to classpath."
else
echo "MAHOUT_LOCAL is not set; adding HADOOP_CONF_DIR to classpath."
CLASSPATH=${CLASSPATH}:$HADOOP_CONF_DIR
Fi
Which means whenever MAHOUT_LOCAL is not empty, it will echo “MAHOUT_LOCAL is not set; adding HADOOP_CONF_DIR to classpath.”.
And notice that:
# MAHOUT_LOCAL set to anything other than an empty string to force
# mahout to run locally even if
# HADOOP_CONF_DIR and HADOOP_HOME are set
Which means if you want to run Mahout on Hadoop but not locally, you should set MAHOUT_LOCAL to empty string.
Thus we may get a conclusion that if we want to run Mahout on Hadoop, it will always echo “MAHOUT_LOCAL is not set; adding HADOOP_CONF_DIR to classpath.” which is not a kind of error.
And all above is my opinion and it may be wrong because I’m still fledgling. But at least all the things still goes well and I did not met any problem since then.
VIII k-means Algorithm Test
Test k-means:
Download the data:
http://archive.ics.uci.edu/ml/databases/synthetic_control/synthetic_control.data
And copy it to $MAHOUT_HOME
Get the Hadoop started:
$HADOOP_HOME/bin/start-all.sh
Then import the data to ‘testdata’(NOTICE that the name ‘testdata’ cannot be modified, it is said on the Internet that only the name ‘testdata’ can be detected by this program):
$HADOOP_HOME/bin/hadoop fs -mkdir testdata
$HADOOP_HOME/bin/hadoop fs -put $MAHOUT_HOME/synthetic_control.data $MAHOUT_ HOME/testdata
Kmeans algorithm:
$HADOOP_HOME/bin/hadoop jar $MAHOUT_HOME/mahout-examples-0.6-job.jar org.apache.mahout.clustering.syntheticcontrol.kmeans.Job
It will take a few minutes
To see the results:
$HADOOP_HOME/bin/hadoop fs -lsr output
$HADOOP_HOME/bin/hadoop fs -get output $MAHOUT_HOME/examples
$cd $MAHOUT_HOME/examples/output
$ ls
And if you see:
clusteredPoints clusters-0 clusters-1 clusters-10 clusters-2 clusters-3 clusters-4
clusters-5 clusters-6 clusters-7 clusters-8 clusters-9 data

Your Mahout is properly installed. 























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









