







爬取妹子图(python):爬虫(bs+rq)+ gevent多线程
简介
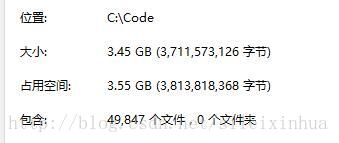
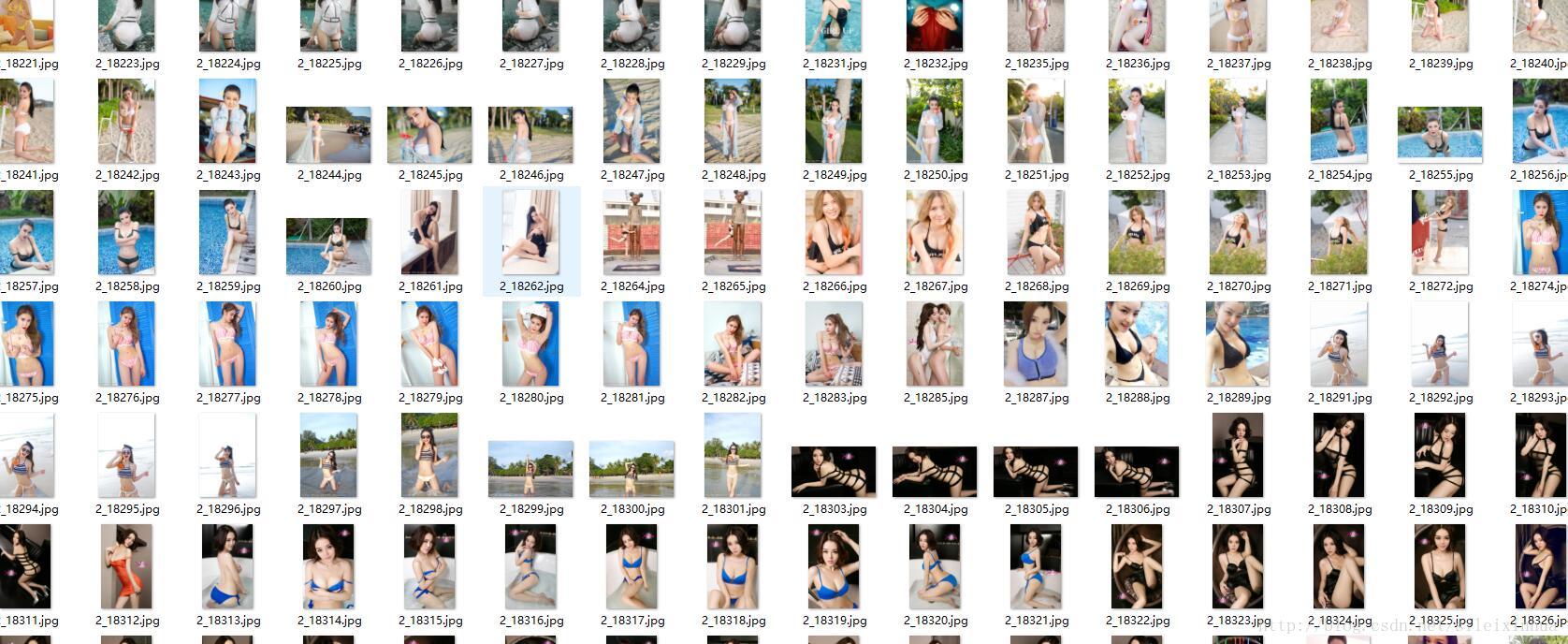
我观察爬取妹子图算是爬虫专业户必做的事情之一,所以我也做了一个,结果是有3.45GB,49847张图。
打算依靠这个图库做个妹子颜值打分系统,或者别的什么图像处理的小项目。
Beautiful Soup + Requests 的学习算是告一段落了,下面开始尝试scrapy和Sasila。
https://github.com/DarkSand/Sasila
推荐一下Sasila。
scrapy的确对于新手很不友好。
代码已经全部上传至github:https://github.com/sileixinhua/beautiful_photo_scrapy
已经把图都下下来的同学,请给我github加个星,就当是给我辛苦费了,谢谢。
开发环境
Beautiful Soup 4.4.0 文档: http://beautifulsoup.readthedocs.io/zh_CN/latest/#id28
Requests : http://cn.python-requests.org/zh_CN/latest/
Python3
gevent : http://xlambda.com/gevent-tutorial/
Windows10
sublime (打算马上转战visual code)
爬虫目标网站
图1 :图片页面显示
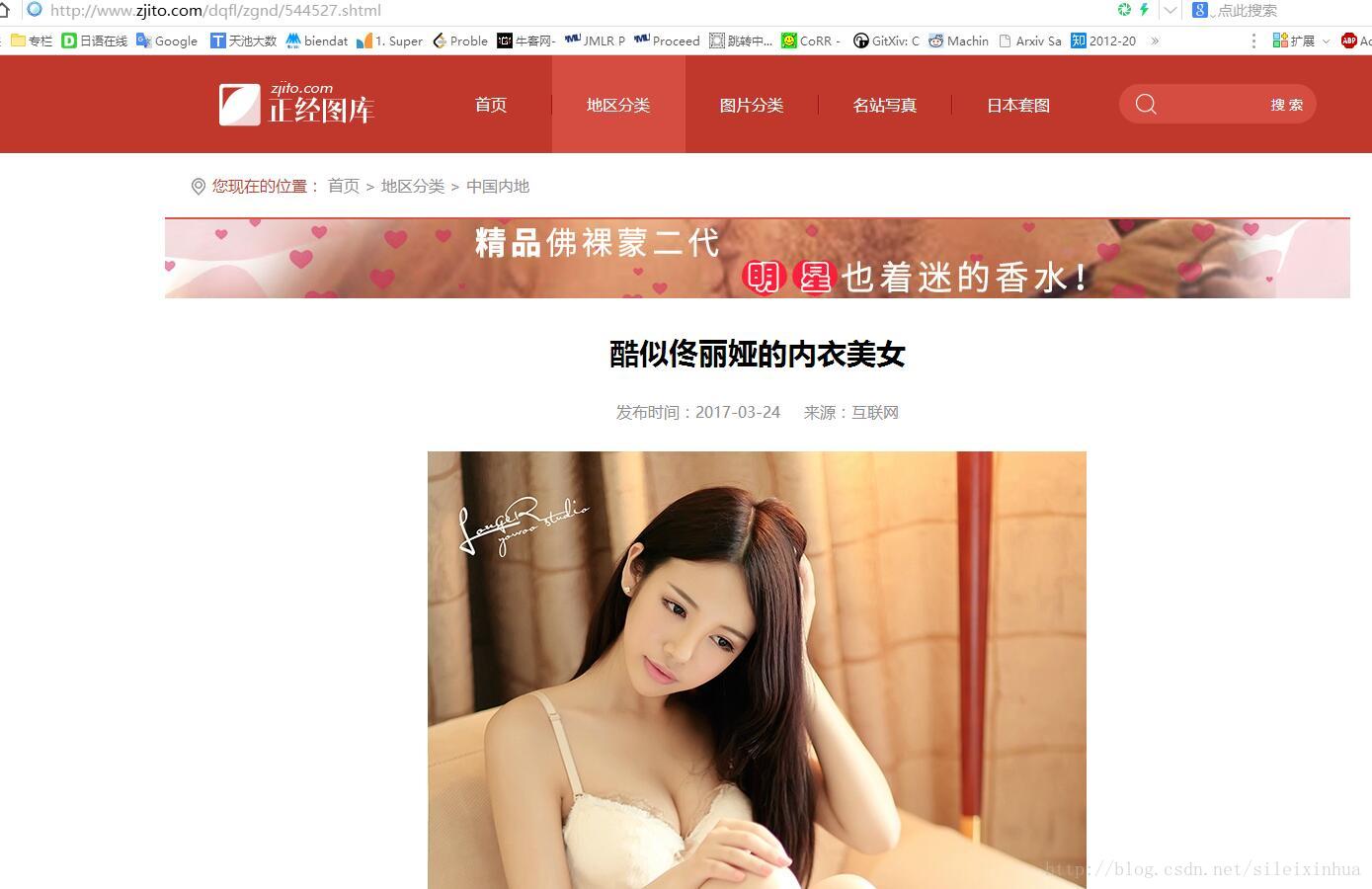
图2 :图片页面重点HTML标签显示

图3 :图片页面url地址

爬虫策略
对网站HTML标签代码进行分析。
在图片页面下每一张图分很多页,但是在第一页中就有这一女孩图的所有页面地址。
先
soup.find_all(class_="div-num")获取所有div-num类下的信息,再
.get('data-src')所有图片的地址,很简单的步策略,但是我分析了半天,尝试了集中方法,还从首页开始暴力检索链接判断图像,分析了半天才发现可以简化这么简单。
代码
# 时间:2017年7月13日17:39:57
# silei
# http://www.zjito.com/
# 爬取妹子图片 bs4 + re + gevent 多线程爬虫
# 存储文件地址为 '../photo'
import requests
from bs4 import BeautifulSoup
import urllib
import gevent
from gevent import Greenlet
import socket
import random
def cbk(a,b,c):
'''''回调函数
@a:已经下载的数据块
@b:数据块的大小
@c:远程文件的大小
'''
per=100.0*a*b/c
if per>100:
per=100
print('%.2f%%' % per)
def photo_download(photo_thread, index_number, photo_number, number):
while number < 3564 :
try:
i = 0
number = number + 1
url = 'http://www.zjito.com/dqfl/'+dict[i]+'/'+str(index_number)+'.shtml?idx=1'
# 爬虫目标网站地址
headers = {'user-agent': 'my-app/0.0.1'}
r = requests.get(url, headers=headers)
# 获得目标页面返回信息
print(r.status_code)
print(url)
while r.status_code == 404:
# 判断响应状态码
i = i + 1
url = 'http://www.zjito.com/dqfl/'+dict[i]+'/'+str(index_number)+'.shtml?idx=1'
print(url)
else :
soup = BeautifulSoup(r.text, 'html.parser')
# 返回的信息放入soup中
# 获取页面全部标签信息
# print(soup.prettify())
# 测试显示的是否是页面的标签
for link in soup.find_all(class_="div-num"):
print(link.get('data-src'))
# 输出图片地址
socket.setdefaulttimeout(3.0)
# 设置超时
photo_number = photo_number + 1
urllib.request.urlretrieve(link.get('data-src'), file+'/'+str(photo_thread)+'_'+str(photo_number)+'.jpg', cbk)
# 下载图片并显示下载进度
gevent.sleep(random.randint(0,2)*0.001)
except Exception as e:
index_number = index_number + 1
index_number = index_number + 1
if __name__ == '__main__':
dict = ['zgnd', 'tw', 'xg', 'rb', 'hg', 'mlxy', 'tg', 'om', 'hx',]
# 照片分类
photo_thread = [1, 2]
# 线程计数器
photo_number = -1
# 下载图片计数器,最大50
# index_number = 530273
# 页面计数器,最小530273,最大544527
file = '../photo/'
# 图片的保存地址
thread1 = Greenlet.spawn(photo_download, photo_thread[0], 530273, photo_number, 0)
# 从命名中创建,并运行新的Greenlet的包装器
# 函数photo_download,带有传递的参数
thread2 = gevent.spawn(photo_download, photo_thread[1], 533836, photo_number, 0)
# 两个thread运行,一个从530273页面开始爬取,另一个从537400页面开始爬取
# 537400 - 530273 = 7127
# 7127 / 2 = 3564
# 3564 + 530273 = 533836
threads = [thread1, thread2]
# 阻止所有线程完成
gevent.joinall(threads)结果
结果是有3.45GB,49847张图。
感想
没有什么感想了,看书,跑步,写代码ing。。。
——————————————————————————————————-
有学习机器学习相关同学可以加群,交流,学习,不定期更新最新的机器学习pdf书籍等资源。
QQ群号: 657119450















 852
852











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









