










CS231n简介
详见 CS231n课程笔记1:Introduction。
注:斜体字用于注明作者自己的思考,正确性未经过验证,欢迎指教。
课程笔记
1. 数据预处理
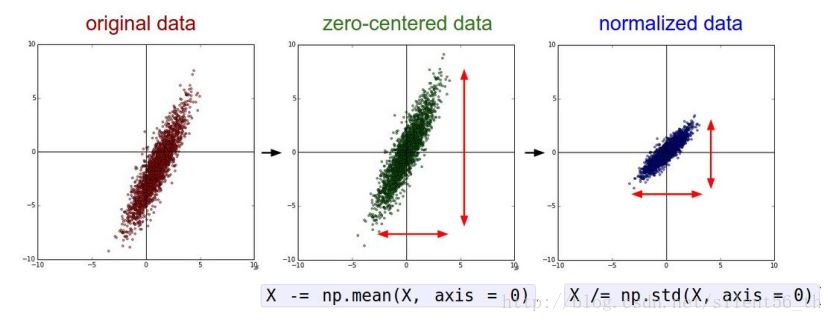
1.1. 归一化
如下图所示,归一化即使得重心位于原点,方差为1。对于归一化的优点请参考CS231n课程笔记5.1:神经网络历史&激活函数比较。
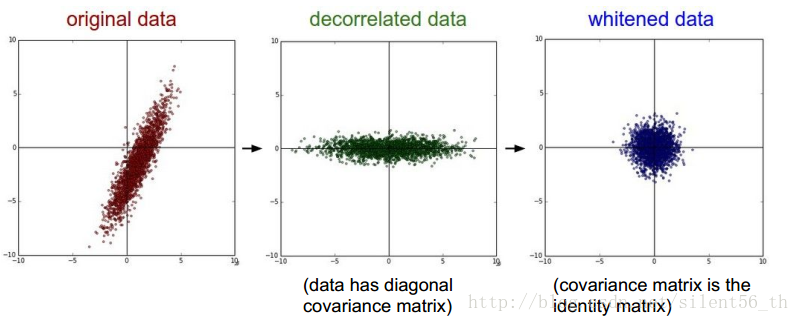
1.2. PCA & 白化
如下图所示,PCA是作用于原数据上的一个线性变换,使得协方差矩阵对角化,如果不进行降维的话是不损失信息的。白化进一步使得协方差矩阵为单位阵。
1.3. 图像领域中的预处理
由于图像领域的特殊性(例如各维之间不是没有关系的变量,而是具有特定的拓扑结构,所以PCA&白化等涉及旋转变化的部分,会损失这部分内容,不适用),通常只对图像做zero-centered。而这部分有两种方式:对于每个像素的每个通道求均值,即HxWxC(例如32x32x3)个均值;还有一种是对于每个通道求均值,即C(例如3)个均值。
2. 权值矩阵初始化
2.1. 都初始化为0
没有gradient传播,因为隐层节点之后的所有数值均为0。非常不可取,永远不要用。
2.2. 小随机数值
例如:服从均值为0,标准差为1e-2的高斯分布。
对于小型网络适用,但不适合大型深度神经网络。
例如,在十层神经网络的情况下,每层都有500个神经元,适用tanh激活函数,使用上诉小随机数初始化参数得到的各层神经元的分布如下图:
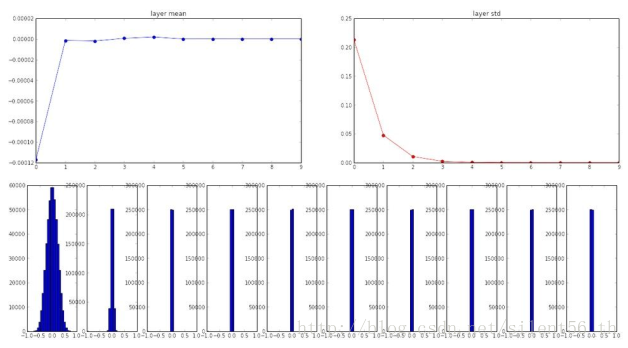
到第三层之后的所有神经元的方差都几乎为0,即所有值都可以看做0,同样的gradient不会传播,权值矩阵几乎不会变。
另一个极端是大随机数,例如如果用标准差为1的高斯分布初始化参数,同样的网络设置得到各层神经元的分布如下图:
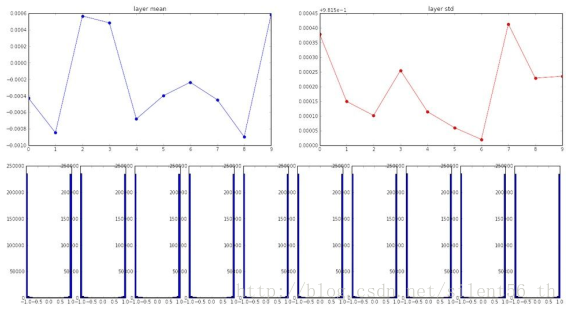
可以看出,所有的输出都是分散,被tanh约束之后基本都是1与-1,即staturated,所以gradient依旧不会传播。
所以大或者小都不合理,需要一个恰当的标准差来初始化参数,即引入下面两种初始化方式。
2.3. Xavier initialization
使用均值为0,标准差为sqrt(扇入)的高斯函数初始化所有参数[Glorot et al., 2010]。注意此方法的数学推导是基于线性激活函数的假设,这部分是可以在tanh的原点附近的区域被满足。适用此种初始化方法,在上诉同样的网络中得到的各层神经元的分布如下图:
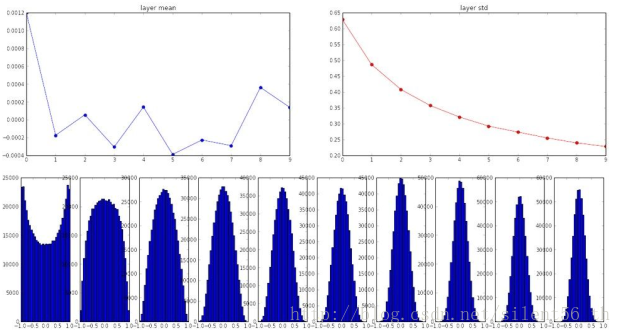
2.4. 改进的Xavier
如上诉,Xavier需要线性函数的假设,这在使用ReLU为激活函数的时候不被满足。将上诉结构中的激活函数改用ReLU而后,使用Xavier的初始化得到的各层神经元的分布如下图:
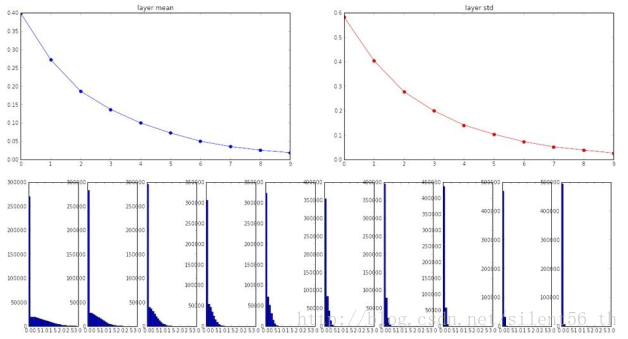
高层神经元基本为0,所以gradient几乎不传播。
为了修补这个缺点,[He et al., 2015]给出了改进的Xavier方法:用均值为0,标准差为sqrt(扇入/2)的高斯分布用于初始化参数。使用这种方法得到的分布如下图:
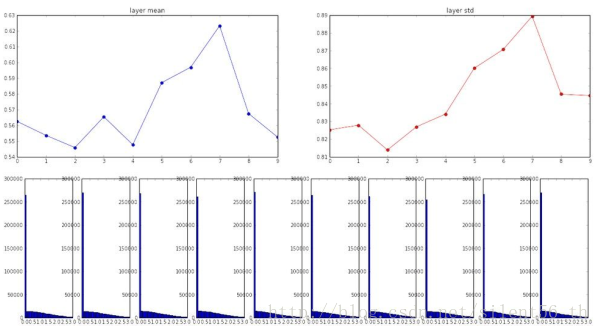
如何初始化参数仍然没有定论
下方是一些关于初始化参数的论文:















 7014
7014











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









