







float数据类型在内存中的存储形式介绍:
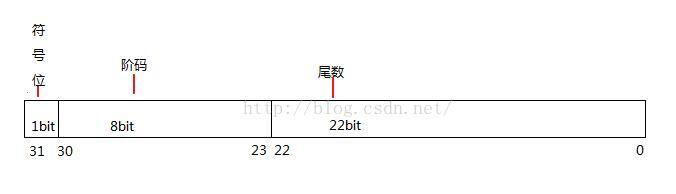
float在内存中的存储遵循IEEE 754标准。在C/C++中,float类型占4个字节即32位 , 这32位分成了3部分:
符号位:转化成二进制后,第31位。 0代表正数,1代表负数
阶码:30-23位,转化成规格化的二进制之后与127之和
尾数:22-0位
例如:13.625在内存中的存储
首先将13.625转化成二进制
整数部分除2取余,直到商为0停止 。最后读数时,从最后一个余数读起,一直到最前面的一个余数
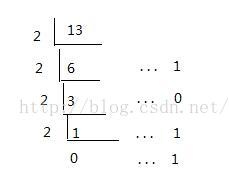
所以整数部分13的二进制位 1101;
小数部分乘2取整,然后从前往后读。
0.625*2 = 1.25 取整 1
0.25*2 = 0.5 取整 0
0.5*2 = 1 取整 1
所以小数部分的二进制 101
然后将 1101.101的小数点向左移至小数点前只有一个1,即左移3位 。(这里为二进制的特定表示方法,将整数部分划为1)
阶码就是3+127 = 130 即:1000 0010
符号位:0
尾数 :因为小数点前必为一,所以记录小数点后面的数即可 101101
0100 0001 0101 1010 0000 0000 0000 0000
转换成16进制后为 41 5A 00 00
float/double类型数据在内存中中存储格式
float/double类型数据在计算机是如何存储的呢?
它们是ieee standard 754的存储方式。 譬如float数,第一位是符号位,然后是8位指数位,然后是23位尾数;double双精度格式为8字节64位,由三个字段组成:52位小数f,11位偏置指数e,以及1位符号s,这些字段连续存储在两个32位字中。
存储结构
| 类型 | 符号位 | 指数位 | 尾数位 |
|---|---|---|---|
| float | 0 | 0xff | 0x7fffff |
| double | 0 | 0x7ff | 0xfffffffffffff |
注意
上面的存储结构,由于字节太多,所以后面使用的十六进制表示,7代表3位,f代表4位
浮点类型
从存储结构和算法上来讲,double和float是一样的,不一样的地方仅仅是float是32位的,double是64位的,所以double能存储更高的精度以及更大的数值。float表示的正数范围是3.40282346638528859811704183484516925440e+38~1.401298464324817070923729583289916131280e-45,double的正数范围是1.797693134862315708145274237317043567981e+308~4.940656458412465441765687928682213723651e-324
【注:个人认为,从阶码上移位来算,整数部分的确可以表示这么大的数据范围,但是从却受到后面尾数的限制,float的有效位数只有6-7位,double的有效位数为15-16位(至于具体为什么是6-7位、15-16位看下面的总结部分),所以感觉上面表示这么大的数据范围实际上意义不大。】
-
可以看出来double的表示的范围比float大,而且由于尾数增加,实际上,精确度也比float高,但这样的优势带来的就是更低的计算效率,虽然个人觉得不论是float还是double计算效率都被整形完爆,所以能够用整型操作,就尽量不要用浮点型。
-
另外一个主要注意的则是,我们可以看到这里该数的表示范围并不像整形那样,直接可以表示0,而是是一个很大到一个很接近0的数值,所以很多情况下浮点数判断是否为0,不是直接跟0比较是不是相等,而是约定一个很小的数,如果小于这个数,就等于0.
实际在内存中的存储顺序
任何数据在内存中都是以二进制(0或1)顺序存储的,每一个1或0被称为1位,而在x86CPU上一个字节是8位。比如一个16位(2字节)的short int型变量的值是1000,那么它的二进制表达就是:00000011 11101000。由于Intel CPU的架构是小尾端表示,它是按字节倒序存储的,那么就因该是这样:11101000 00000011,这就是定点数1000在内存中的结构。 (如果这里不明白为什么这样,可以搜索大尾端小尾端概念)
目前C/C++编译器标准都遵照IEEE制定的浮点数表示法来进行float,double运算。这种结构是一种科学计数法,用符号、指数和尾数来表示,底数定为2——即把一个浮点数表示为尾数乘以2的指数次方再添上符号。下面是具体的规格:
| 类型 | 符号位 | 阶码 | 尾数 | 长度 |
|---|---|---|---|---|
| float | 1 | 8 | 23 | 32 |
| double | 1 | 11 | 52 | 64 |
实战:十进制转十六进制
下面以double38414.4为例:
- 把整数部和小数部分开处理:整数部直接化十六进制:960E。
- 小数的处理: 0.4=0.5*0+0.25*1+0.125*1+0.0625*0+……
你会发现第二步根本是坑爹嘛,根本算不完,那么该怎么办呢?加上前面整数的精度960E,你只需要算够53位就行了(最高位的1不写入内存)。手工算到53位是:38414.4(10)=1001011000001110.011001100110011001100110011001100110011(2)
科学记数法:1.001……乘以2的15次方。
(注意指数是15,这里的指数是2的次方,不是10的次方)
然后看阶码,一共11位,可以表示范围是-1024 ~ 1023。因为指数可以为负,为了便于计算,规定都先加上1023,在这里,
15+1023=1038。二进制表示为:100 00001110
符号位:正—— 0 !
合在一起(尾数二进制最高位的1不要):
01000000 11100010 11000001 11001101 01010101 01010101 01010101 01010101
假定机器为小尾端,字节倒序存储的十六进制数就是:
55 55 55 55 CD C1 E2 40
协议参考网址
IEEE Standard 754 for Binary Floating-Point Arithmetic
http://www.wikilib.com/wiki?title=IEEE_754&variant=zh-sg
--------------------------------------------------------------------------------------
总结:1 范围
float和double的范围是由指数的位数来决定的。
float的指数位有8位,而double的指数位有11位,分布如下:
float:
| 1bit(符号位) | 8bits(指数位) | 23bits(尾数位) |
double:
| 1bit(符号位) | 11bits(指数位) | 52bits(尾数位) |
于是,float的指数范围为-127~+128,而double的指数范围为-1023~+1024,并且指数位是按补码的形式来划分的。其中负指数决定了浮点数所能表达的绝对值最小的非零数;而正指数决定了浮点数所能表达的绝对值最大的数,也即决定了浮点数的取值范围。
float的范围为-2^128 ~ +2^128,也即-3.40E+38 ~ +3.40E+38;double的范围为-2^1024 ~ +2^1024,也即-1.79E+308 ~ +1.79E+308。
2 精度
float和double的精度是由尾数的位数来决定的。浮点数在内存中是按科学计数法来存储的,其整数部分始终是一个隐含着的“1”,由于它是不变的,故不能对精度造成影响。
float:2^23 = 8388608,一共七位,这意味着最多能有7位有效数字,但绝对能保证的为6位,也即float的精度为6~7位有效数字;
【也可以这么算,0.000001的精度为10^(-6), 2^20 = 1048576; 1/1048576的精度高于10^(-6), 但是23位不够表示10^(-7),所以为有效位数为6-7位;】
double:2^52 = 4503599627370496,一共16位,同理,double的精度为15~16位。
所以,float数据类型受到有限的有效位数限制,不能表示精度高的浮点型数据;














 1663
1663











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









