










作者:whj95
前言及总览
前言
排序舞:以下视频是由Sapientia University创作的,比较生动形象地表现了排序的步骤,供大家预习及理解
①冒泡排序视频
②选择排序视频
③插入排序视频
④希尔排序视频
⑤归并排序视频
⑥快速排序视频
可视化排序:
魔性的15种排序方法
来源于B站,可以等看完下文了解了这些排序之后看,也可以参考视频中的绿字弹幕解说看,初步对这些排序大概有个概念。
具体关心左上角排序名称、主图的排序速度、以及上方居中的数据量
数据可视化
强无敌的可视化过程
总览
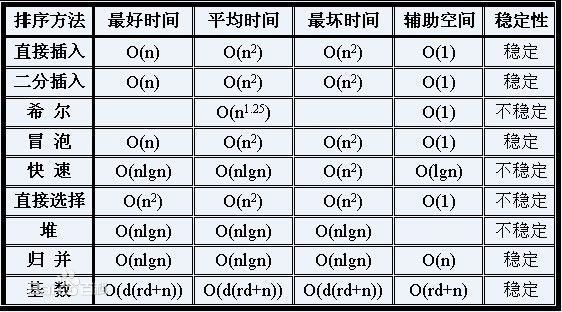
基本排序方法:①选择排序;②冒泡排序;③插入排序
进阶排序方法:希尔排序;
高级排序方法:①归并排序;②堆排序;③快速排序
线性排序方法:①计数排序;②基数排序;③桶排序
交换排序
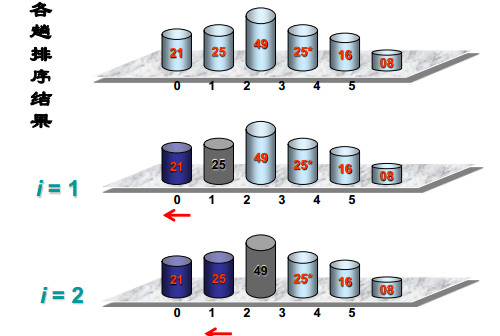
选择排序
定义
找到当前元素中最小的那个放在前面
可视化过程

代码实现
一层增初值,最小值与下标默认当前,末尾交换当前与最小;二层移光标比大小,记下标
void select_sort(int a[],int n)
{
for(int i = 0; i < n; i++)
{
int min = a[i];
int index = i;
for(int j = i + 1; j < n; j++)
{
if(a[j] < min)
{
min = a[j];
index = j;
}
}
if (index != i)
swap(a[i], a[index]);
}
}优点:
没有优点让你考虑用它,就是它最大的优点
缺点:
①不稳定。
②平均时间为O(n
2
)。因此为了改进寻找最小元引出了用最小堆的堆排序。
冒泡排序 (Bubble sort)
定义
顾名思义,相邻两者两两PK,将下方的数不断“上浮”。
可视化过程
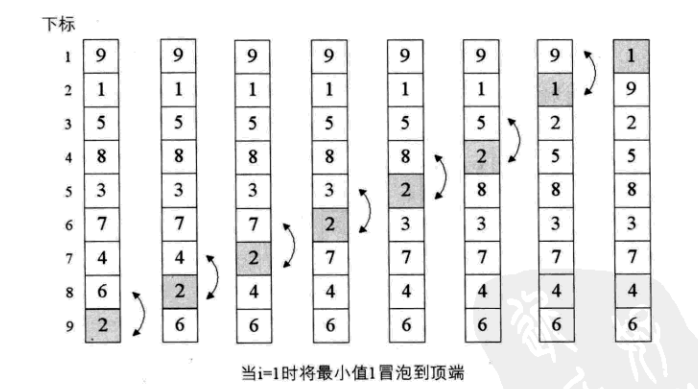
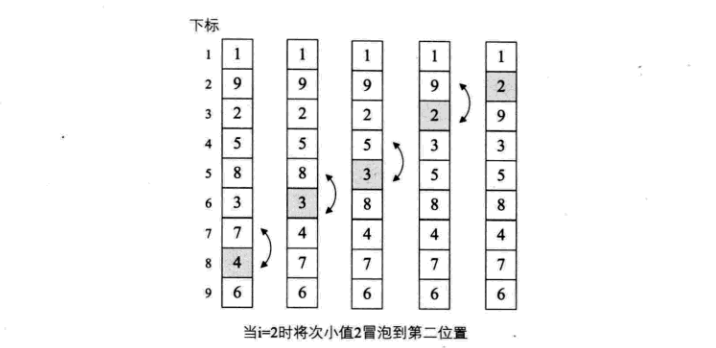
代码实现
void bubble_sort(int a[],int n)
{
for(int i = n - 1; i >= 0; j--)//每次循环最下面的一定已经排好
{
bool flag = 0;//优化冒泡排序,若从头到尾没有进行过交换则已经排好,所以退出循环
for(int j = 0; j < i; i++)
if(a[j] > a[j+1])
{
swap(a[j],a[j+1])
flag = 1;
}
if(flag == 0)
break;
}
}优点:
稳定。一次确定位置。可实现部分排序
缺点:
交换相邻元素的算法不高效,会与逆序对有关,复杂度为O(n + i),其中i为逆序对个数,而i的平均个数为n(n-1)/4,所以平均时间为O(n
2
)
插入排序
定义
类似玩扑克牌,把最后一张牌往大小合适的位置插入
可视化过程
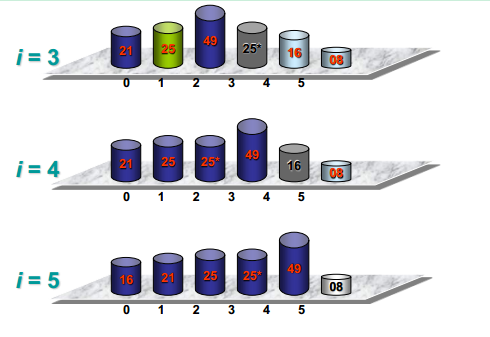

代码实现
一层增初值;二层找到比当前元素小的,腾地插空
void insert_sort(int a[],int n)
{
for(int i = 1; i < n; i++)//默认已有一个数
{
tmp = a[i];
for(int j = i; j > 0 && a[j] > tmp; j--)
a[i] = a[i-1];
a[i] = tmp;
}
}优点:
① 稳定;
②比较次数和移动次数与初始排列有关;最好情况下只需O(n)时间
缺点:
不够快,不过算是基本排序中最好的算法了
希尔排序
定义
步长不断变化的直接插入排序
可视化过程
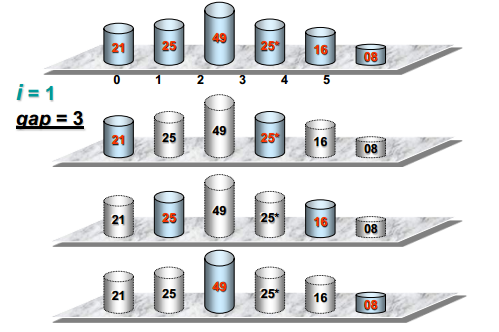
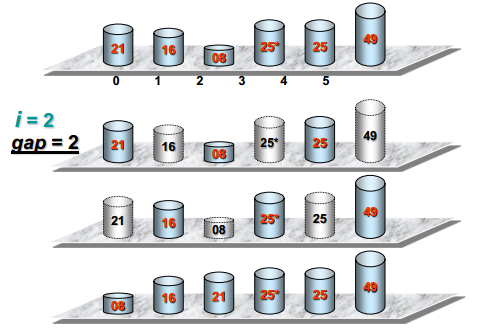
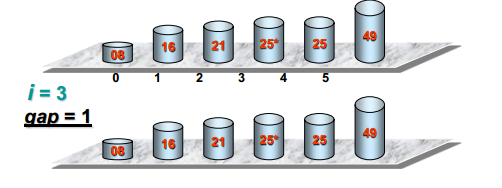
代码实现
一层定步长,二层增初值,三层腾地插
void hill_sort(int a[],int n)
{
for(int step = n/2; step > 0; step/=2)
for(int i = step; i < n; i++)//下面都是插入排序
{
int tmp = a[i];
for(int j = i; j >= step && a[j-step] > tmp; j-=step)
a[i] = a[i-step];
a[i] = tmp;
}
}优点:克服了相邻元素比较的拘束,打破了排序必O(n
2
)的断言
缺点:
不稳定。由于二分不互质,会导致有几种步长比较没用。以此改进的有奇数增量序列,Hibbard增量序列,Sedgewick增量序列等希尔排序。
归并排序 (Merge sort)
定义
分治经典例子。可以理解为国家队想挑选队员出征国际赛场,首先会从各省队中挑选,省队又从各市队挑选
可视化过程
如何对38,27,43,3,9,82,10进行归并排序
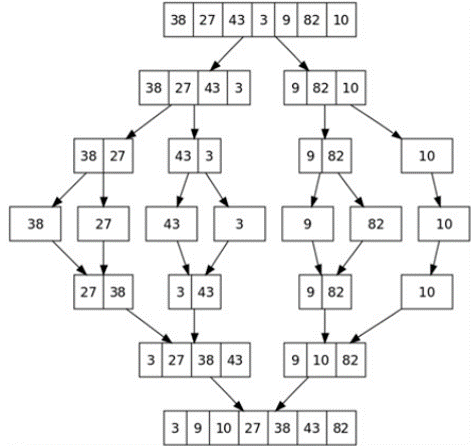
代码实现
void Merge_sort(int low, int high)
{
int mid = (low + high) / 2;
if (low == high)
return;
Merge_sort(low, mid);//前半部分
Merge_sort(mid + 1, high);//后半部分
int tal1 = low, tal2 = mid + 1, tal = low;
while ((tal1 <= mid) && (tal2 <= high))//前半部分和后半部分都未遍历完
{
if (a[tal1] < a[tal2])
b[tal++] = a[tal1++];
else
b[tal++] = a[tal2++];
}
while (tal1 <= mid)//只剩前半部分,直接放入目标数组
b[tal++] = a[tal1++];
while (tal2 <= high)//只剩后半部分,直接放入目标数组
b[tal++] = a[tal2++];
}复杂度分析:
T(N) = 2T(N/2)+cN = 2[2T(N/2^2) + cN/2] + cN = … = 2^kO(1) + ckN
∵N/2^k = 1
∴k = logN
即T(N) = O(NlogN)堆排序 (Heap sort)
定义
利用二叉树结构,结合了插入排序(原地排序)和归并排序(O(nlgn))各自的优点
可视化过程
我是图
流程
①维护堆maxheapify
②建堆bulid_maxheap
③堆排序heap_sort
代码实现
/*维护堆maxheapify*/
/*从上往下追溯是否满足堆结构,不满足进行交换,对交换过的子树重复递归过程。递归在无交换节点时终止*/
void maxheapify(int a[], int parent, int n)
{
int l,r,largest;//l,r分别表示左右子节点下标,largest存储最大值下标
l = parent * 2,r = parent * 2 + 1;
if(l <= n && a[l] > a[parent])//有左孩子&&大于根节点
largest = l;
else
largest = parent;
if (r <= n && a[r] > a[parent])
largest = r;
if(largest != parent)//如果发生了交换,需递归调整交换后的子树
{
swap(a[largest],a[parent]);
maxheapify(a,largest);
}
}
void swap(int a,int b)
{
int tmp = a;
a = b;
b = tmp;
}
/*建堆bulid_maxheap*/
/*自底向上,循环调用maxheapify调整数组为堆*/
void bulid_maxheap(int a[])
{
for(int i = floor(n/2); i >= 1; --i)
maxheapify(a, i, sizeof(a)/sizeof(int));
}
/*堆排序heap_sort*/
/*交换最末叶节点和根节点值确定最大值,每次交换紧跟最大堆化,注意要排除已排序的最末叶节点*/
void heap_sort(int a[],int n)
{
bulid_maxheap(int a[]);
for(int i = n; i >= 2; --i)
{
swap(a[1],a[i]);
maxheapify(a, 1, i - 1);
}
}复杂度分析:
①维护堆maxheapify
T(N) ≤ T(2N/3)+c ≤ [T(N*(2/3)^2) + c)] + c ≤ … ≤kO(1) + kc
∵N*(2/3)^k = 1
∴k = logN
→T(N) = O(logN)
②建堆bulid_maxheap
由于调用了n次维护过程,所以时间复杂度为O(N*logN),其实更为精确的解为O(N)
③堆排序heap_sort
建堆+n次维护,所以时间复杂度为O(N)+ O(N*logN)=O(NlogN)
快速排序 (Quicksort)
定义
①取序列中的元素作为枢轴(pivot),将整个对象序列划分为左右两个子序列。然后递归执行。
②左侧子序列中所有对象小于或等于枢轴,右侧子序列中所有对象大于枢轴
③每一趟枢轴位置即为最终位置
可视化过程
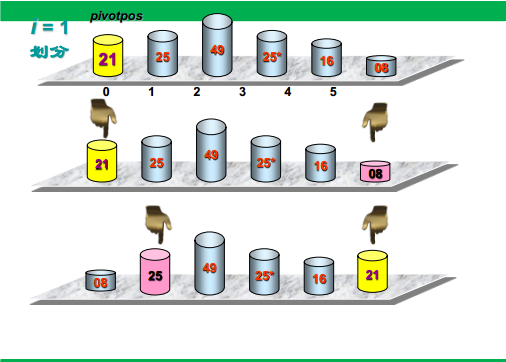
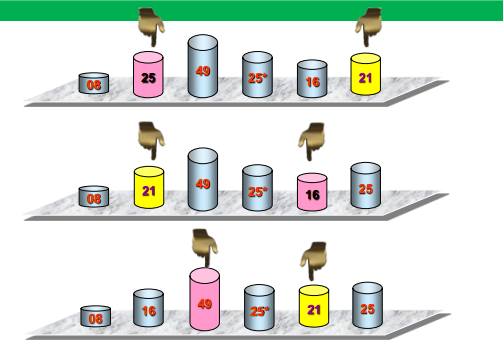
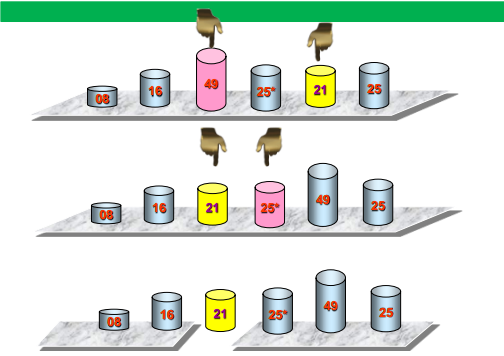
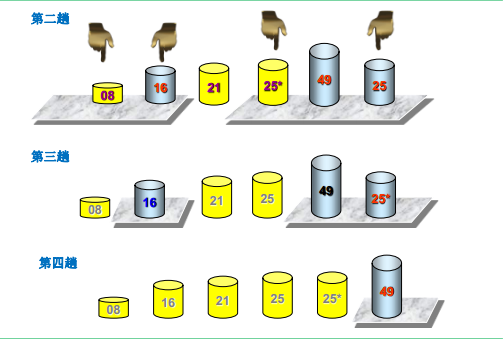
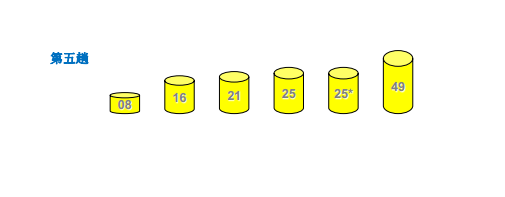
代码实现
/*下面代码是以第一个元素为枢轴。*/
/*而实际“三者取中”比较好,不容易退化*/
void qsort(int a[],int left,int right)
{
int last;
if(left >= right)
return;
swap(left,(left + right) / 2);
last = left;
for(int i = left + 1; i <= right; ++i)
if(a[i] < a[left])
swap(++last,i);
swap(left,last);
qsort(a,left,last - 1);
qsort(a,last + 1,right);
}
void swap(int i,int j)
{
int tmp = a[i];
a[i] = a[j];
a[j] = tmp;
}优点:
①快。对于无序且数量大的序列非常快,O(nlogn)的速度无愧于“快速”二字。当枢轴选得好,其划分均匀,递归树的高度平衡
②每一趟总能至少确定一个元素的最终位置。
缺点:
①不稳定。
②需要额外空间S(log
2
n),最坏时需要O(n)
③序列为正序或逆序时其退化为斜树,时间复杂度变O(n
2
),因此当比较数量小时改用直接插入排序,或是堆排序。而使用堆排序改进的方法称为内省排序。
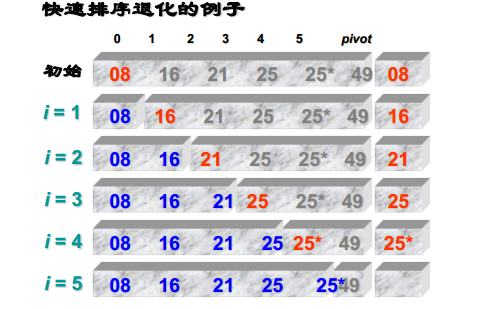
线性时间排序
计数排序 (Counting sort)
定义
空间代时间,把乱序的离散数字映射到一张有序的连续表上
代码实现
void counting_sort(int a[], int b[], int n) //所需空间为 2*n+k
{
int c[n];
memset(c,0,sizeof(c)/sizeof(int));
//统计数组中,每个元素出现的次数
for(int i = 0; i < n; ++i)
c[a[i]] = ++c[a[i]];
//统计数组计数,每项存前N项和
for(int i = 1; i <= n; ++i)
c[i] += c[i-1];
//将计数排序结果转化为数组元素的真实排序结果
for(int i = n - 1 ; i >= 0; --i)
{
b[c[a[i]]] = a[i];
--c[a[i]];
}
} 优点:
当输入的元素是 n 个 0 到 k 之间的整数时,它的运行时间是 O(n + k)。计数排序不是比较排序,排序的速度快于任何比较排序算法。
缺点:
①由于计数数组的长度取决于待排序数组中数据的范围,这意味着计数排序需要大量内存。
②无法排序人名
上述两个缺点,引出了基数排序的方法。
基数排序(radix sort)
定义
简单来讲就是将数字拆分为个位十位百位,每个位依次排序。
可视化过程
千言万语不如一张图
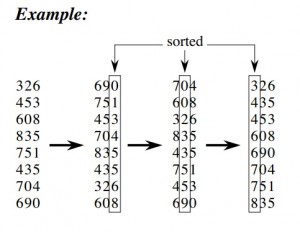
基数排序分为MSD(Most Significant Dight)和LSD(Least Significant Dight),上述的方法即为LSD。不同于正常的比较思维,通常LSD排序更为常用,因为LSD不需要分堆对每堆单独排序,所以往往比MSD简单且开销小。
void radix_sort(int arr[],int begin,int end,int d)
{
const int radix = 10;
int count[radix], i, j;
int *bucket = (int*)malloc((end-begin+1)*sizeof(int)); //所有桶的空间开辟
//按照分配标准依次进行排序过程
for(int k = 1; k <= d; ++k)
{
//置空
for(i = 0; i < radix; i++)
count[i] = 0;
//统计各个桶中所盛数据个数
for(i = begin; i <= end; i++)
count[getdigit(arr[i], k)]++;
//count[i]表示第i个桶的右边界索引
for(i = 1; i < radix; i++)
count[i] = count[i] + count[i-1];
//把数据依次装入桶(注意装入时候的分配技巧)
for(i = end;i >= begin; --i) //这里要从右向左扫描,保证排序稳定性
{
j = getdigit(arr[i], k); //求出关键码的第k位的数字, 例如:576的第3位是5
bucket[count[j]-1] = arr[i]; //放入对应的桶中,count[j]-1是第j个桶的右边界索引
--count[j]; //对应桶的装入数据索引减一
}
//注意:此时count[i]为第i个桶左边界
//从各个桶中收集数据
for(i = begin,j = 0; i <= end; ++i, ++j)
arr[i] = bucket[j];
}
} 基数排序对每一位的排序都要使用计数排序。假设带排数字有n个,每个数字均为d位数,每一数位有k个取值,则其时间复杂度为O(d*(n+k))
桶排序 (Bucket sort)
定义
桶排序也是计数排序的变种,它将计数排序中相邻的m个”小桶”整合到一个”大桶”中,对每个大桶内部进行排序,最后合并大桶(一般用链表实现)。
伪代码
void bucket_sort(int a[], int n)
{
int b[n];
memset(b,0,sizeof(b)/sizeof(int));
for(int i = 0; i < n; ++i)
insert a[i] into b[floor(na[i])];
for(int i = 0; i < n; ++i)
sort b[i];
concatenate b[0],b[1],...,b[n-1] together
}优点:
①桶排序的平均时间复杂度为O(N+C),其中C为桶内快排的时间复杂度。如果相对于同样的N,桶数量M越大,其效率越高,最好的时间复杂度达到O(N)。
②桶排序是稳定的
缺点:
桶排序的空间复杂度为S(N+M),当输入数据非常庞大而桶的数量也非常多时,空间代价相当之高。
C++中的sort
#include<algorithm>
/*第一个参数是首地址,第二个是末尾地址,第三个是比较函数*/
std::sort(a, a+n, compare_function);
/*compare_function1自定义按平方从小到大返回*/
bool compare_function1(int i, int j)
{
return (i*i<j*j);
}
/*compare_function2自定义按类的关键字i从小到大排序*/
class obj
{
public:
int i;
char ch
};
bool compare_function2(obj a, obj b)
{
return a.i < b.i;
}














 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









