









视频链接:李宏毅机器学习(2016)_演讲•公开课_科技_bilibili_哔哩哔哩
课程资源:Hung-yi Lee
课程相关PPT已经打包命名好了:链接:https://pan.baidu.com/s/1c3Jyh6S 密码:77u5
我的第十三讲笔记:李宏毅机器学习2016 第十三讲 无监督学习之非线性降维:流型学习(Mainfold Learning)
Unsupervised Learning:Deep Auto-encoder
本章主要讲述了深度自编码器的原理及其应用。
1. 自编码器(Auto-encoder)
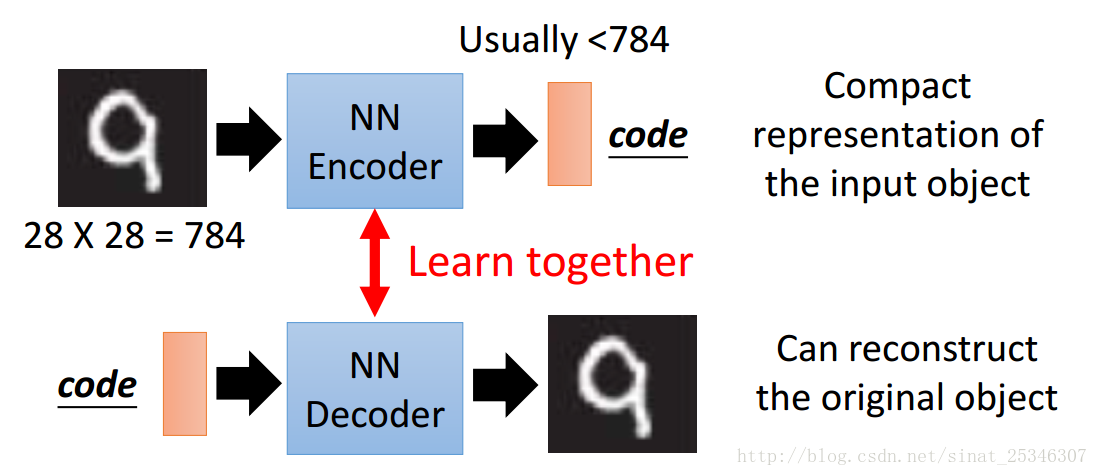
自编码器是一种无监督学习方法,可用于数据降维及特征抽取。自编码器由编码器(Encoder)和解码器(Decoder)两部分组成。编码器通常对输入对象进行压缩表示,解码器对经压缩表示后的code进行解码重构。
2.深度自编码器(Deep Auto-encoder)
自编码器可以是深度结构。
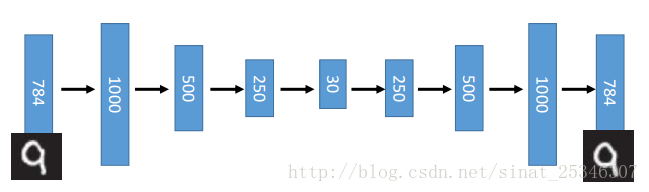
如上图所示,784维的输入经过多层编码器,得到30维的code,接着再将其进行解码,可以看出效果是较理想的。
3.深度自编码器的应用
①文本检索(Text Retrieval)
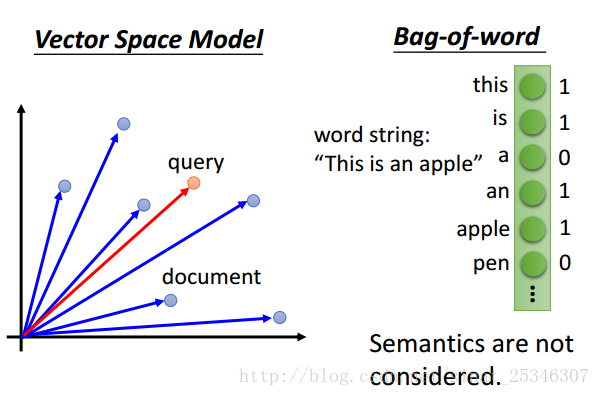
一般的文本检索方法有向量空间模型(Vector Space Model),上图中蓝色的点代表的是文档(经过降维后),接着计算要查询的文档与其他的距离,选择较为接近,相似程度高的,但这个模型的好坏关键取决于向量化的好坏;单词包(Bag-of-word),通过建立一个词向量,若文档中存在某些词记1否则记0,然后再计算相似性,但此模型不能很好的表达语义层面。
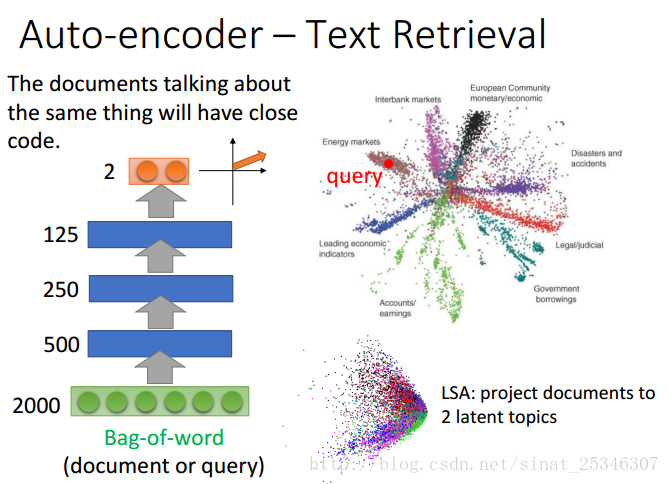
自编码器可以很好的实现文本搜索。具有相同主题的文档会有相近的code。
②图像搜索(Image Search)
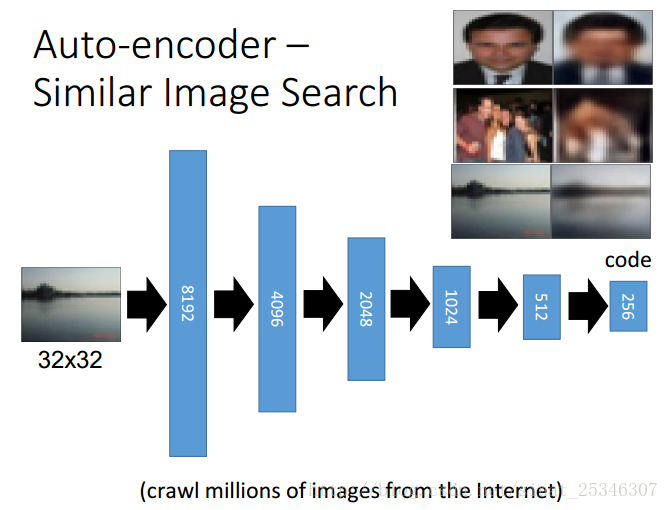
通过在code上计算相似度,有着很好的效果。
③预训练深度神经网络(Pre-training DNN)
在深度学习中,自编码器可用于在训练阶段开始前,确定权重矩阵W的初始值。
神经网络中的权重矩阵W可看作是对输入的数据进行特征转换,即先将数据编码为另一种形式,然后在此基础上进行一系列学习。如果编码后的数据能够较为容易地通过解码恢复成原始数据,我们则认为W较好的保留了数据信息。
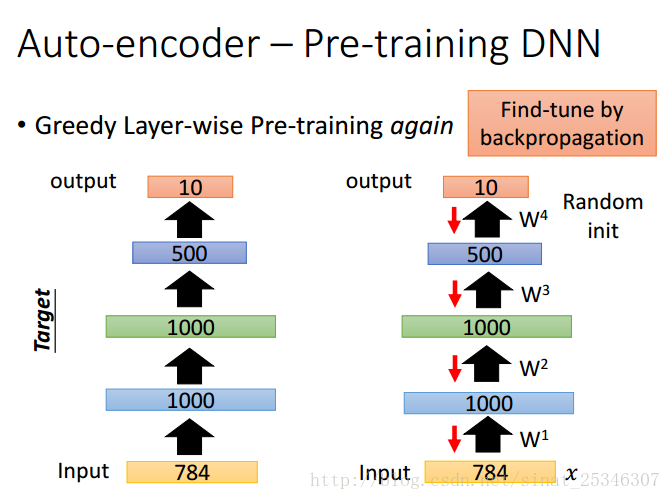
这是一种贪婪地逐层预训练。在预训练后得到权重初始值后,接着用Backpropagation反向传播算法对网络进行微调(fine-tune)。
但是现如今强大的计算能力,使得深度学习并不使用自编码来预训练。在大量无标签的数据情况下,深度自编码器仍然有一定作用。
④Auto-decoder for CNN
在卷积神经网络中,也可以应用自编码器。
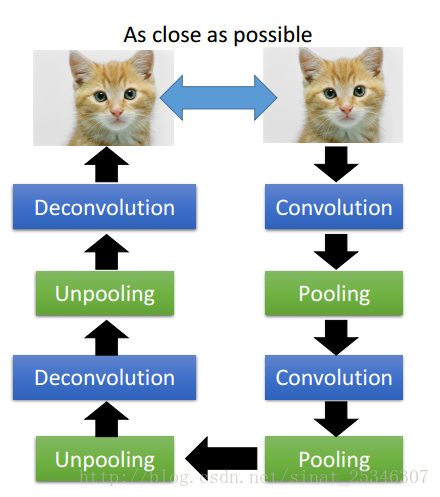
CNN主要是卷积(Convolution)和池化(Pooling)操作。
因此相对应的就要有反卷积(Deconvolution)和反池化(Depooling)操作。
反池化很好理解,只需记住池化过程中的位置(最大值出现的地方),在反池化的过程中,将对应位置置相应的值,其余位置置0即可。
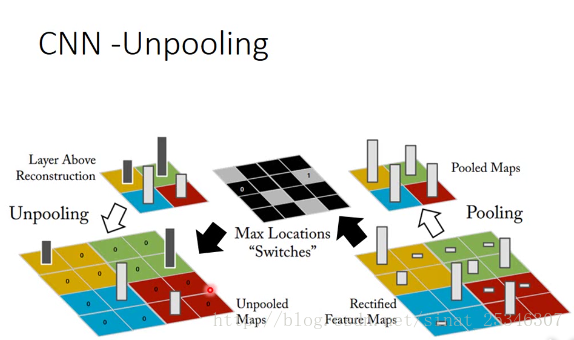
反卷积操作就有点难以理解。实际上,反卷积就是卷积。
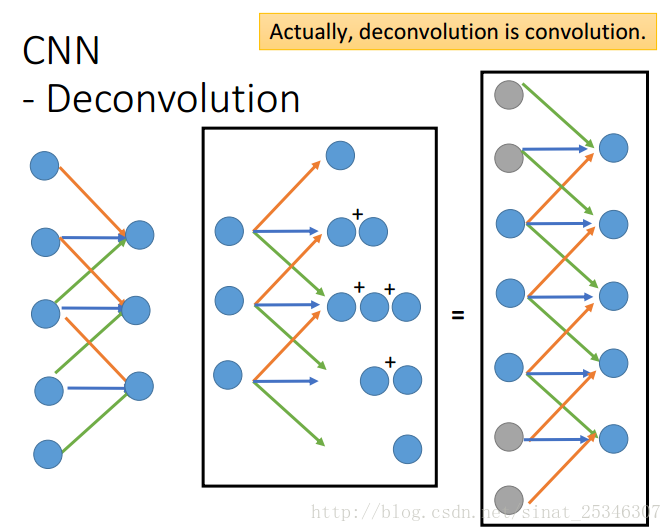
指需对卷积后的结果进行填充(padding)再进行池化操作,所得值就是所谓的反卷积结果。
4.总结
本章主要讲述了自编码的原理,及其在文本检索(Text Retrieval)、图像搜索(Image Search)、预训练深度神经网络(Pre-training DNN)以及在卷积神经网络(CNN)上的应用。














 3238
3238











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









