









每每以为攀得众山小,可、每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~

———————————————————————————
《数据挖掘之道》摘录话语:虽然我比较执着于Rwordseg,并不代表各位看管执着于我的执着,推荐结巴分词包,小巧玲珑,没有那么多幺蛾子,而且R版本和python版本都有,除了词性标注等分词包必备功能以外,jiebaR还加入了一些基础的文本分析算法,比如提取关键字(TFIDF)、分析文本相似性等等,真是老少咸宜。
同时官网也有一个在线jiebaR分词的网址,超级棒:https://qinwf.shinyapps.io/jiebaR-shiny/
jiebaR是“结巴”中文分词(Python)的R语言版本,支持最大概率法(Maximum Probability),隐式马尔科夫模型(Hidden Markov Model),索引模型(QuerySegment),混合模型(MixSegment)共四种分词模式,同时有词性标注,关键词提取,文本Simhash相似度比较等功能。项目使用了Rcpp和CppJieba进行开发。目前托管在GitHub上。
来自:http://cos.name/tag/jiebar/

——————————————————————————————————
来看一下这篇论文一些中文分词工具的性能比较《开源中文分词器的比较研究_黄翼彪,2013》
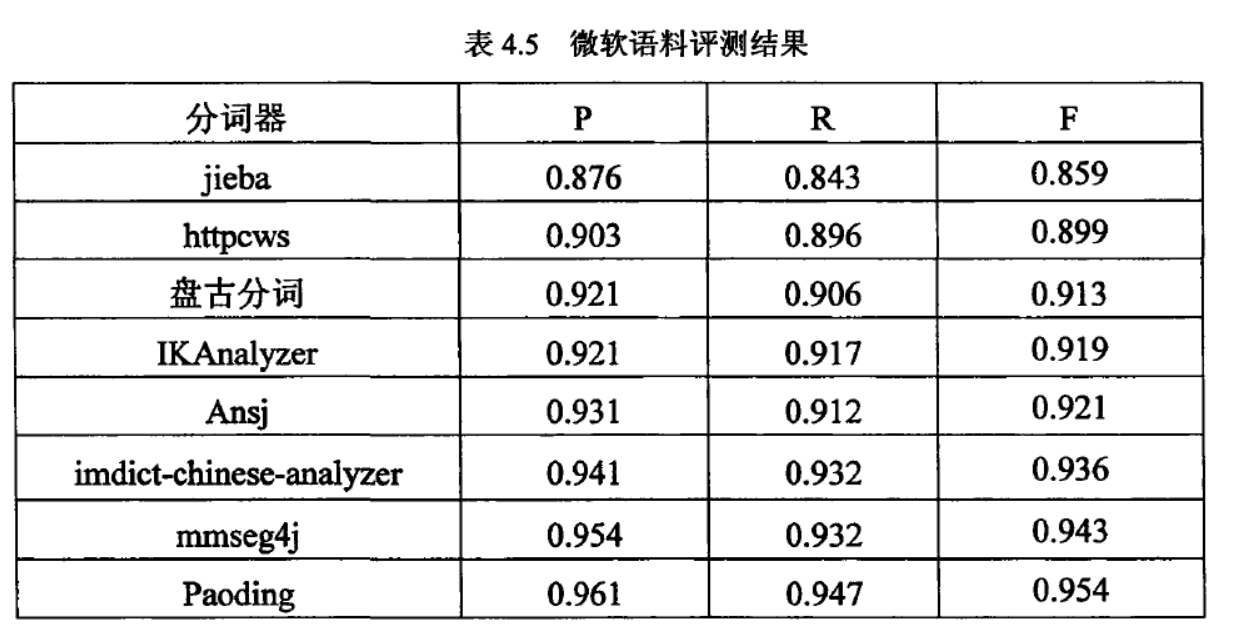
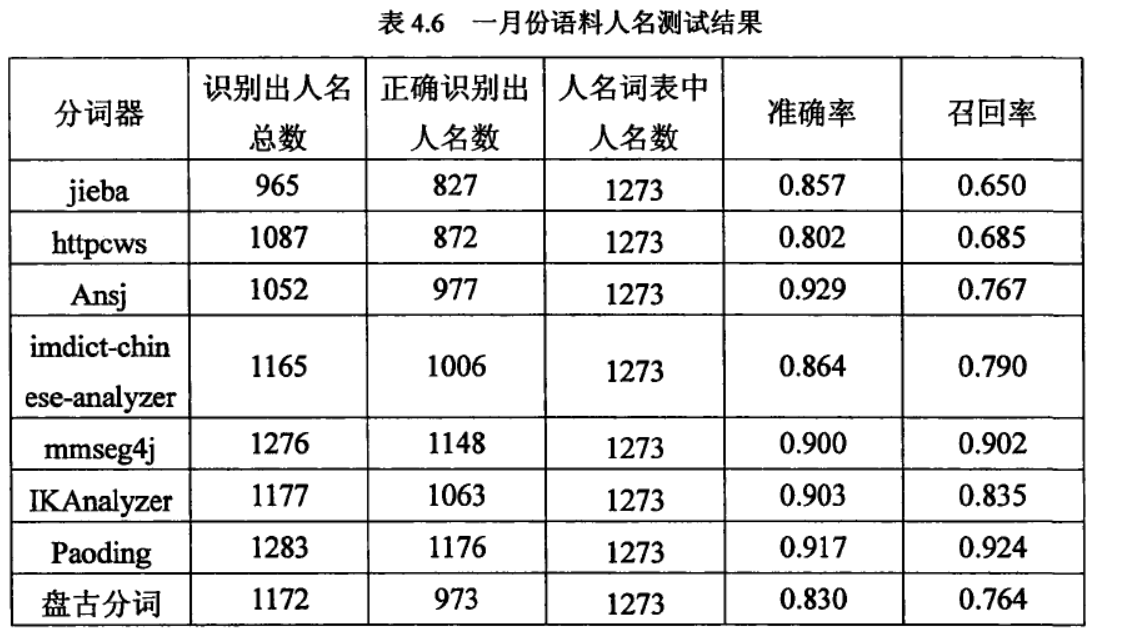
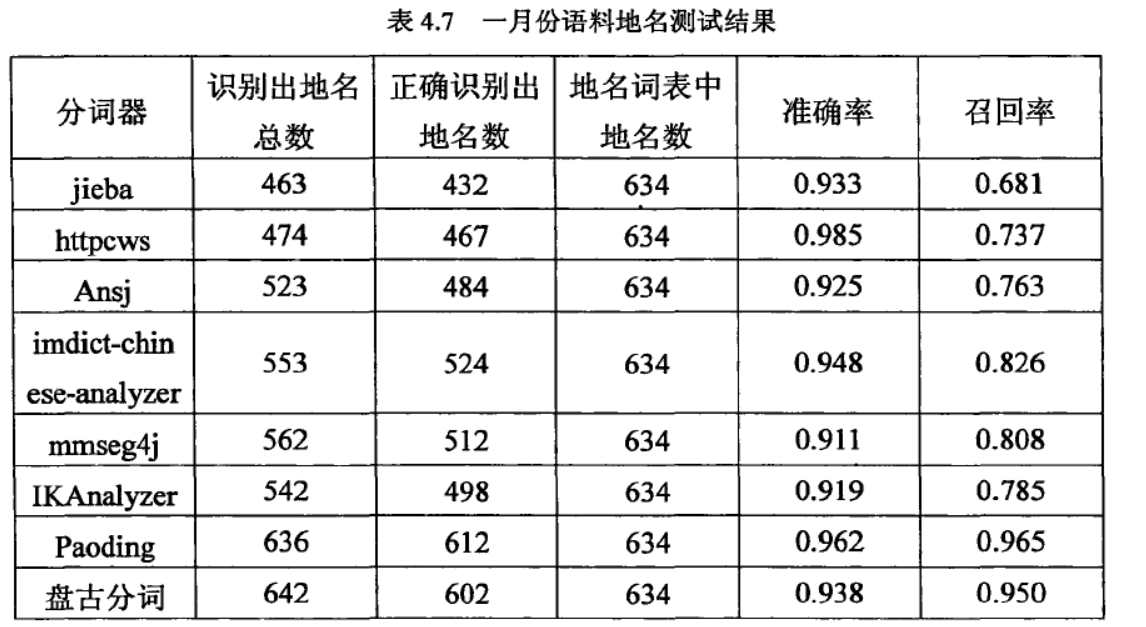
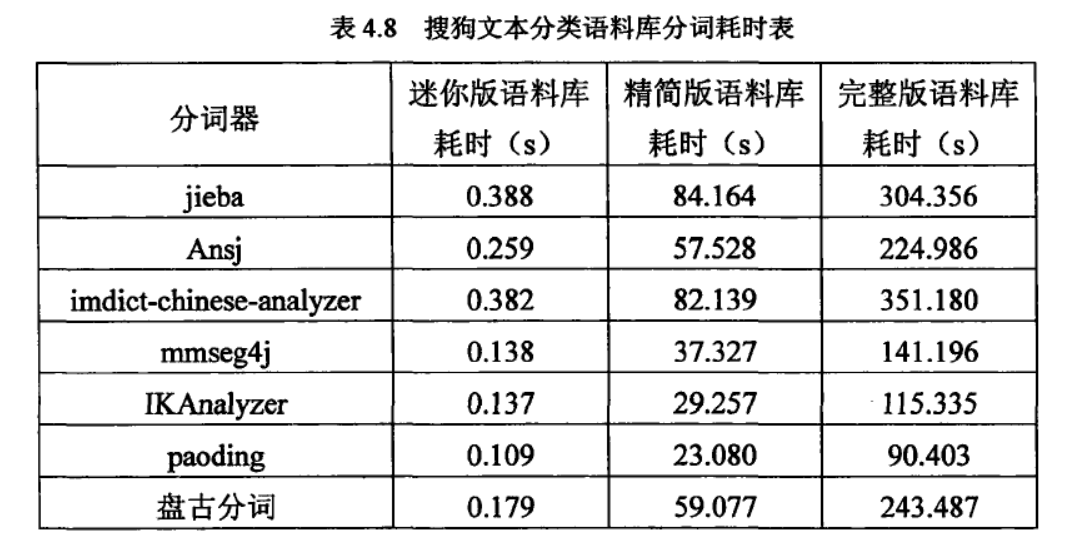
8款中文分词器的综合性能排名:
Paoding(准确率、分词速度、新词识别等,最棒)
mmseg4j(切分速度、准确率较高)
IKAnalyzer
Imdict-chinese-analyzer
Ansj
盘古分词
Httpcws
jieba
——————————————————————————————————
Rwordseg与jiebaR分词之间的区别
中文分词比较有名的包非`Rwordseg`和`jieba`莫属,他们采用的算法大同小异,这里不再赘述,我主要讲一讲他们的另外一个小的不同:
`Rwordseg`在分词之前会去掉文本中所有的符号,这样就会造成原本分开的句子前后相连,本来是分开的两个字也许连在一起就是一个词了,
而`jieba`分词包不会去掉任何符号,而且返回的结果里面也会有符号。
所以在小文本准确性上可能`Rwordseg`就会有“可以忽视”的误差,但是文本挖掘都是大规模的文本处理,由此造成的差异又能掀起多大的涟漪,与其分词后要整理去除各种符号,倒不如提前把符号去掉了,所以我们才选择了`Rwordseg`。
——————————————————————————————————
一、jiebaR的安装
案例
http://www.bkjia.com/ASPjc/958939.html
安装出现的问题
1、网上教程大多用github装
library(devtools)
install_github("qinwf/jiebaR")但是我总是出现以下问题:
Error: Command failed (1)
In addition: Warning message:
In utils::download.file("https://cran.rstudio.com/bin/windows/Rtools/Rtools33.exe", :
InternetOpenUrl failed: '操作超时'Warning in install.packages :
InternetOpenUrl failed: '操作超时'Downloading GitHub repo qinwf/jiebaR@master
trying URL 'https://cran.rstudio.com/bin/windows/Rtools/Rtools33.exe'
Error in utils::download.file("https://cran.rstudio.com/bin/windows/Rtools/Rtools33.exe", :
cannot open URL 'https://cran.rstudio.com/bin/windows/Rtools/Rtools33.exe'
Installing jiebaR
Skipping 2 packages not available: jiebaRD, Rcpp
"F:/R/R-3.2.2/R-3.2.2/bin/x64/R" --no-site-file --no-environ --no-save --no-restore CMD INSTALL \
"C:/Users/long/AppData/Local/Temp/RtmpmUlaMY/devtools597c19394370/qinwf-jiebaR-12cb03b" --library="F:/R/R-3.2.2/R-3.2.2/library" \
--install-tests 于是就去了官网看(官网链接:https://github.com/qinwf/jiebaR)
发现了两种方法:
通过CRAN安装:
install.packages("jiebaR")
library("jiebaR")
cc = worker()
cc["这是一个测试"] # or segment("这是一个测试", cc)
# [1] "这是" "一个" "测试"同时还可以通过Github安装开发版,建议使用 gcc >= 4.6 编译,Windows需要安装 Rtools :
library(devtools)
install_github("qinwf/jiebaRD")
install_github("qinwf/jiebaR")
library("jiebaR")其中通过Github安装,需要Rtools,这个文件比较大,
下载链接在:https://cran.r-project.org/bin/windows/Rtools/
这里我是下载不了,出现以下的报错:
- Downloading GitHub repo lchiffon/wordcloud2@master
- from URL https://api.github.com/repos/lchiffon/wordcloud2/zipball/master
- Error in curl::curl_fetch_memory(url, handle = handle) :
- Problem with the SSL CA cert (path? access rights?)
然后借鉴了博客( 安装包(上传数据)失败时的解决方法),
- library(RCurl)
- library(httr)
- set_config( config( ssl_verifypeer = 0L ) )
————————————————————————————
二、分词效果——worker启动器
jiebaR包可以实现分词(分行分词)、整个文档分词(分文档分词)。library(jiebaR)加载包时,没有启动任何分词引擎,启动引擎很简单,就是一句赋值语句就可以了——mixseg=worker()。详细版本请参考官方:https://jiebar.qinwf.com/section-3.html#section-3.0.1
但是实际上worker中有非常多的调节参数。
mixseg = worker(type = "mix", dict = "dict/jieba.dict.utf8",
hmm = "dict/hmm_model.utf8",
user = "dict/test.dict.utf8",
detect=T, symbol = F,
lines = 1e+05, output = NULL
) 代码解读:
type代表分词模型,有mix(混合模型),mp(最大概率),hmm(隐马尔科夫链),query(索引),tag(词性标注),simhash(距离),keywords(关键词)
hmm代表隐马尔科夫链所用的语料库,一般不用更改
user代表自定义的参考此包,后续会说到如何把网络中的此包变成jiebaR认可的;
detect决定了引擎是否自动判断输入文件的编码,加载后通过cutter$detect = F也可以设置
symbol代表是否保留标点符号
lines当输入为文档文件时,一次性最大读取行数
output代表分词内容是否变成文件写出
1、分行输出
mixseg$bylines = TRUE
mixseg[c("这是第一行文本。","这是第二行文本。")]2、文档分行输出
mixseg$bylines = TRUE
head(mixseg["./index.rmd"]) 自动判断输入文件编码模式,默认文件输出在同目录下。
3、词性标注
词性标注使用混合模型模型分词,标注采用和 ictclas 兼容的标记法
words = "我爱北京天安门"
tagger = worker("tag") #词性标注启发器
tagger <= words4、关键词提取
keys = worker("keywords", topn = 4,idf=IDFPATH) #关键词keywords topn代表着关键词个数
#??是TFIDF还是IDF值?
keys <= "我爱北京天安门" #第一行代表IDF(逆文档频率) 第二行为具体关键词
keys <= "一个文件路径.txt"关键词提取建立在使用因马尔科夫链HMM模型的基础上,所以已经有hmm的语料库,在这语料库的基础上计算新来的文档文字的IDF值来对核心词进行筛选。
topn代表筛选出核心词的数量,可以自由调节。
—————————————————————————————————————————
三、自定义词库——cidian包
R语言中如何将网络中其他的词典包加入成为分词词包其实有两个办法。第一个使用cidian包,将网络中已有的词包进行转化后,通过worker中的dict进行调用。第二个办法通过停用词的手法,加入到停用词词包中,然后进行筛选。
1、jiebaR基本词库查看函数
show_dictpath() ### 显示词典路径,旧的函数是:ShowDictPath()
edit_dict() ### 编辑用户词典,旧的函数为:ShowDictPath() 2、词包转化方式——cidian包安装
cidian包在github中,所以需要调用devtools,同时需要下载Rtools才能顺利安装,还是挺麻烦的。
详细下载和使用信息可参考官方网址:https://github.com/qinwf/cidian/
(1)cidian包下载条件一
install.packages("devtools")
install.packages("stringi")
install.packages("pbapply")
install.packages("Rcpp")
install.packages("RcppProgress")
library(devtools)
install_github("qinwf/cidian")(2)cidian包下载条件二——Rtools下载
参考官方网址:https://cran.r-project.org/bin/windows/Rtools/
下载并安装即可。
3、使用
decode_scel(scel = "细胞词库路径",output = "输出文件路径",cpp = TRUE)
decode_scel(scel = "细胞词库路径",output = "输出文件路径",cpp = FALSE,progress =TRUE)4、添加新词
new_user_word(mixseg, "这是一个新词", "n")
mixseg["这是一个新词"]通过new_user_word来添加新词,而且需要加入词性的信息。
5、添加停用词——第二类加入特定词的方法
readLines("stop.txt")
#> [1] "停止词"
mixseg = worker(stop_word = "stop.txt")
new_user_word(mixseg, "停止词", "n")
#> [1] TRUE
mixseg["这是一个停止词"]
# > [1] "这是" "一个"通过mixseg = worker(stop_word = "stop.txt")来实现加入停用词。
——————————————————————————————————---——
四、simhash算法——传统词向量
google对于网页去重使用的是simhash,他们每天需要处理的文档在亿级别,大大超过了我们现在文档的水平。
该章节参考大牛博客(转载自LANCEYAN.COM)(原文链接: 《Similarity estimation techniques from rounding algorithms》),其通过hash算法让文本变为一系列由0-1构成的哈希值,并通过单词重要性加权获得simhash值。
库里的文本都转换为simhash 代码,并转换为long类型存储,空间大大减少。
1、simhash算法的介绍
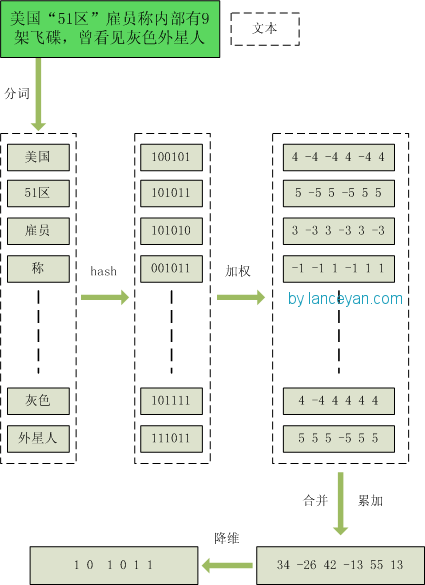
为了便于理解尽量不使用数学公式,分为这几步:
1、分词,把需要判断文本分词形成这个文章的特征单词。最后形成去掉噪音词的单词序列并为每个词加上权重,我们假设权重分为5个级别(1~5)。比如:“ 美国“51区”雇员称内部有9架飞碟,曾看见灰色外星人 ” ==> 分词后为 “ 美国(4) 51区(5) 雇员(3) 称(1) 内部(2) 有(1) 9架(3) 飞碟(5) 曾(1) 看见(3) 灰色(4) 外星人(5)”,括号里是代表单词在整个句子里重要程度,数字越大越重要。
2、hash,通过hash算法把每个词变成hash值,比如“美国”通过hash算法计算为 100101,“51区”通过hash算法计算为 101011。这样我们的字符串就变成了一串串数字,还记得文章开头说过的吗,要把文章变为数字计算才能提高相似度计算性能,现在是降维过程进行时。
3、加权,通过 2步骤的hash生成结果,需要按照单词的权重形成加权数字串,比如“美国”的hash值为“100101”,通过加权计算为“4 -4 -4 4 -4 4”;“51区”的hash值为“101011”,通过加权计算为 “ 5 -5 5 -5 5 5”。
4、合并,把上面各个单词算出来的序列值累加,变成只有一个序列串。比如 “美国”的 “4 -4 -4 4 -4 4”,“51区”的 “ 5 -5 5 -5 5 5”, 把每一位进行累加, “4+5 -4+-5 -4+5 4+-5 -4+5 4+5” ==》 “9 -9 1 -1 1 9”。这里作为示例只算了两个单词的,真实计算需要把所有单词的序列串累加。
5、降维,把4步算出来的 “9 -9 1 -1 1 9” 变成 0 1 串,形成我们最终的simhash签名。 如果每一位大于0 记为 1,小于0 记为 0。最后算出结果为:“1 0 1 0 1 1”。
问题:
1、hash值维数是如何确定的?有5个分词就代表变为5位数的哈希值吗?
2、为什么需要先分词来计算hash值,不能直接整个文档计算哈希值?
答:传统hash函数解决的是生成唯一值,比如 md5、hashmap等。更多的是生成特制密匙,不利于找出相似性,因为传统hash值没有相似。
2、海明距离的计算
两个simhash对应二进制(01串)取值不同的数量称为这两个simhash的海明距离。举例如下: 10101 和 00110 从第一位开始依次有第一位、第四、第五位不同,则海明距离为3。
那么海明距离多少为合理范围呢?
在距离为3时是一个比较折中的点,在距离为10时效果已经很差了,不过我们测试短文本很多看起来相似的距离确实为10。如果使用距离为3,短文本大量重复信息不会被过滤,如果使用距离为10,长文本的错误率也非常高。如何选择,需要根据业务来进行调试。
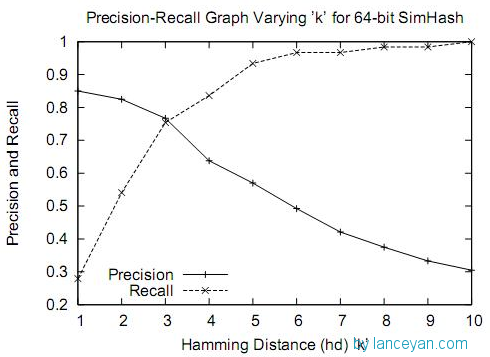
过大量测试,simhash用于比较大文本,比如500字以上效果都还蛮好,距离小于3的基本都是相似,误判率也比较低。
但是如果我们处理的是微博信息,最多也就140个字,使用simhash的效果并不那么理想。
3、R语言中的simhash值与海明距离
> simhasher = worker("simhash",topn=2)
> simhasher <= "江州市长江大桥参加了长江大桥的通车仪式"
$simhash
[1] "12882166450308878002"
$keyword
22.3853 8.69667
"长江大桥" "江州"
> simhasher <= "你妈妈喊你回家吃饭哦,回家罗回家罗"
$simhash
[1] "9184284471008831268"
$keyword
18.5768 6.55531
"回家" "妈妈"
> distance("江州市长江大桥参加了长江大桥的通车仪式" , "你妈妈喊你回家吃饭哦,回家罗回家罗" , simhasher)
$distance
[1] "30"
$lhs
22.3853 8.69667
"长江大桥" "江州"
$rhs
18.5768 6.55531
"回家" "妈妈" 代码解读:simhasher = worker("simhash",topn=2)设置simhash启动器,topn代表计算simhash值的同时排出核心词。
其中simhash值此时为“9184284471008831268”,此时19个字句子生成了一个20个数字列的数字向量。
$keyword代表IDF值与具体的核心词。
distance函数计算海明距离,此时为30,如果两句话的词向量位数不同的话,会后补齐的方式来计数,比如101与01,R语言中海明距离为2;$lhs与$rhs代表左、右不同句子的核心词。
4、与word2vec区别
simhash算法的One-hot Representation采用稀疏矩阵的方式表示词,在解决某些任务时会造成维数灾难;
simhash算法中虽然考虑了根据词重要性来进行加权,但是没有顾及词语与词语前后语序关系。
word2vec可以顾及一句话词语与词语之间前后关联关系,同时可以自我设定默认维数。
可参考:重磅︱文本挖掘深度学习之word2vec的R语言实现
————————————————————————————————————
延伸一:jiebaR的一些新功能
1、停用词过滤函数:filter_segment()
cutter = worker()
result_segment = cutter["我是测试文本,用于测试过滤分词效果。"]
result_segment
[1] "我" "是" "测试" "文本" "用于" "测试" "过滤" "分词" "效果"
filter_words = c("我","你","它","大家")
filter_segment(result_segment,filter_words)
[1] "是" "测试" "文本" "用于" "测试" "过滤" "分词" "效果"filter_segment(词,过滤词)
同时,默认的 STOPPATH 路径将不会被使用,不默认使用停止词库。需要自定义其他路径,停止词才能在分词时使用。停止词库的编码需要为 UTF-8 格式,否则读入的数据可能为乱码。
2、提取关键词函数:vector_keywords
keyworker = worker("keywords")
cutter = worker()
vector_keywords(cutter["这是一个比较长的测试文本。"],keyworker)
8.94485 7.14724 4.77176 4.29163 2.81755
"文本" "测试" "比较" "这是" "一个"
vector_keywords(c("今天","天气","真的","十分","不错","的","感觉"),keyworker)
6.45994 6.18823 5.64148 5.63374 4.99212
"天气" "不错" "感觉" "真的" "今天"vector_keywords(词,关键词引擎worker)
3、N-gram组合频率
get_tuple() 返回分词结果中 n 个连续的字符串组合的频率情况,可以作为自定义词典的参考。
get_tuple(c("sd","sd","sd","rd"),size=3)
# name count
# 4 sdsd 2
# 1 sdrd 1
# 2 sdsdrd 1
# 3 sdsdsd 1
get_tuple(list(
c("sd","sd","sd","rd"),
c("新浪","微博","sd","rd"),
), size = 2)
# name count
# 2 sdrd 2
# 3 sdsd 2
# 1 微博sd 1
# 4 新浪微博 14、计算simhash 值和 海明距离——vector_simhash vector_distance
sim = worker("simhash")
cutter = worker()
vector_simhash(cutter["这是一个比较长的测试文本。"],sim)
$simhash
[1] "9679845206667243434"
$keyword
8.94485 7.14724 4.77176 4.29163 2.81755
"文本" "测试" "比较" "这是" "一个"
vector_simhash(c("今天","天气","真的","十分","不错","的","感觉"),sim)
$simhash
[1] "13133893567857586837"
$keyword
6.45994 6.18823 5.64148 5.63374 4.99212
"天气" "不错" "感觉" "真的" "今天"
vector_distance(c("今天","天气","真的","十分","不错","的","感觉"),c("今天","天气","真的","十分","不错","的","感觉"),sim)
$distance
[1] "0"
$lhs
6.45994 6.18823 5.64148 5.63374 4.99212
"天气" "不错" "感觉" "真的" "今天"
$rhs
6.45994 6.18823 5.64148 5.63374 4.99212
"天气" "不错" "感觉" "真的" "今天"tobin 进行 simhash 数值的二进制转换。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









