







笔记源于一次微课堂,由数据人网主办,英伟达高级工程师ParallerR原创。大牛的博客链接:http://www.parallelr.com/training/
由于本人白痴,不能全部听懂,所以只能把自己听到的写个小笔记。
一、GPU的基本概念
GPU计算比CPU计算要快很多,计算机用GPU会大大加大速度
问题:现在不是有量子计算,GPU与其有什么区别?那么量子计算是否比GPU更能是明日之星呢?
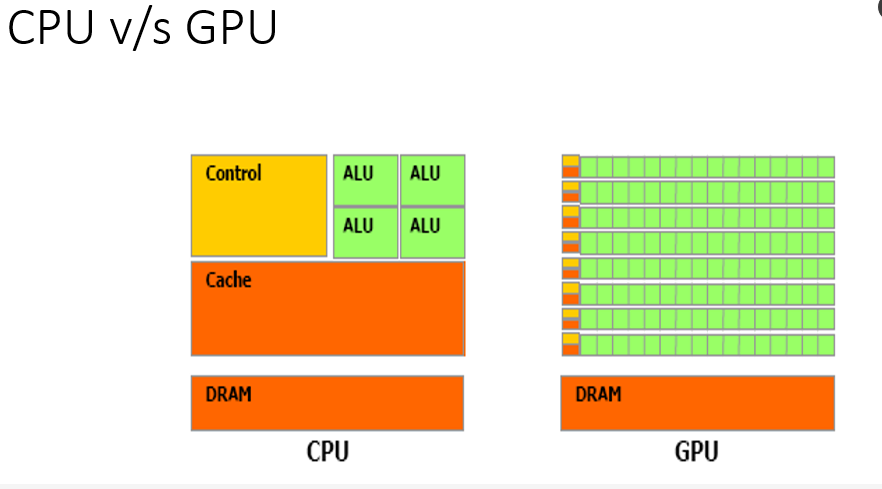
CPU 中ALU只有四个,虽然大,但是control与cache占比较大;而GPU又很多,虽然小,但是control,cache占比小,所以更有优势,有长尾效应。用非常大量的小单元来加快运行速度。
GPU模式
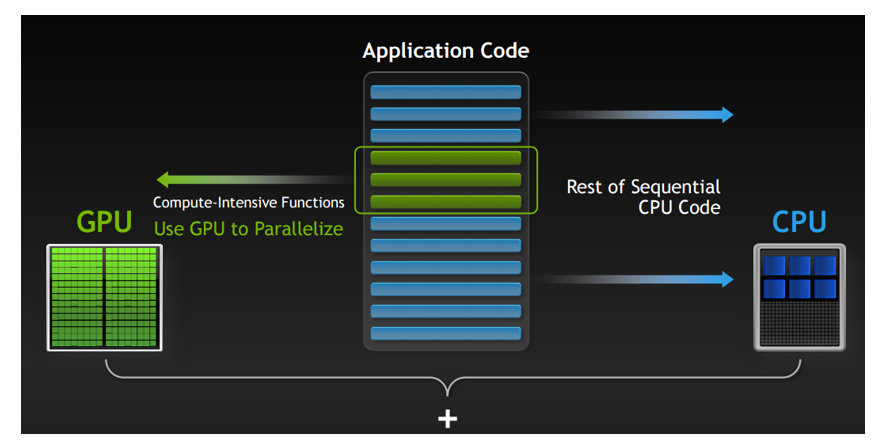
CPU做逻辑运算时,比较好,但是当遇见特别密集型、单一的计算网格时,就会使用GPU进行计算。所以GPU与CPU是相互配合进行计算。
GPGPU使用方法(GPU本来是处理图像的,现在GPU升级,可以处理一些计算)
1、已有的GPU库,我们直接调用API,最容易最简单,因为我们不需要知道GPU的使用内容,缺点:但是需要开发者,很清晰了解算法本身,知道哪些可以用GPU进行计算,哪些不用,不然会很乱。
2、编译器,通过一些方法把我们的算法自动GPU化,然后跑到程序里面去;
3、算法完全用GPU重写,成本最高,但是这个算法能够很效率。CUDA
二、GPU计算应用到R语言之中
R速度慢,是解释性语言,一条命令,先编译成指令,然后传输到CPU进行计算;
编译性语言可以直接访问CPU等,
内存不够,先读入R内存,然后再进行计算,对于R的存储有要求。
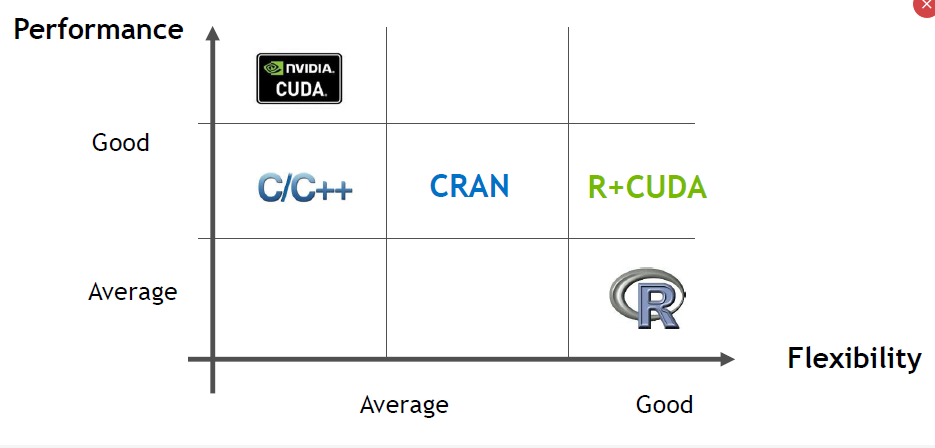
R与GPU结合
一般有GPU package,一般有三种方法:library、cuda
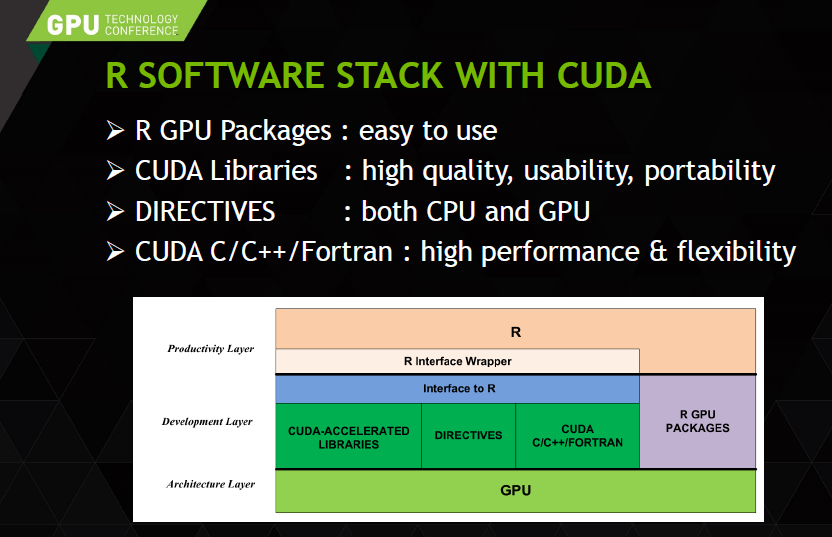
Cuda的库,可用性很强,
两个例子:
BLAS、FFT包

1、blas包
矩阵计算,需要R先预编译,下面的网址有编译的手法。只能在linux下运行。

http://www.parallelr.com/r-hpac-benchmark-analysis/
2、FFT
https://devblogs.nvidia.com/parallelforall/accelerate-r-applications-cuda/
调用已有GPU的库,中高级使用者;遇到性能问题的可以选
要写interface function















 4477
4477











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









