









apple.Turicreate已经是第四篇了。本模块主要阐述该平台相似模块的一些功能。
也是目前求相似解决方案很赞的一个。
官方地址:https://apple.github.io/turicreate/docs/api/turicreate.toolkits.nearest_neighbors.html
地址二:https://apple.github.io/turicreate/docs/userguide/nearest_neighbors/nearest_neighbors.html
输入的主要方式为SFrame,主打两个模块:
- (1)query,查询
- (2)similarity_graph,近邻
一个小案例:
import turicreate
references = turicreate.SFrame({'x1': [0.98, 0.62, 0.11],
'x2': [0.69, 0.58, 0.36]})
# 建模-最近邻
model = turicreate.nearest_neighbors.create(references)
# 建模-近邻图谱
sim_graph = model.similarity_graph(k=1)该案例涵盖了两大主要模块,查询与近邻图谱。
.
一、主函数介绍
turicreate.nearest_neighbors.create(dataset, label=None, features=None, distance=None, method='auto', verbose=True, **kwargs)1.1 常规参数解释:
- dataset,只能是SFrame
- features,支持格式很多,Numeric、Array、Dictionary、List、String
- distance距离选择, ‘euclidean’, ‘squared_euclidean’, ‘manhattan’,
‘levenshtein’(文字距离), ‘jaccard’, ‘weighted_jaccard’, cosine’,也可以自己定义距离 - 相似方法method, {‘auto’, ‘ball_tree’, ‘brute_force’, ‘lsh’}
- verbose
.
1.2 其他特定的参数:
leaf_size,针对ball tree method,树叶节点数量
num_tables,针对LSH,构造哈希表的数量,默认是20,建议在10-30
num_projections_per_table,针对LSH,每个散列表的投影/散列函数的数量
.
1.3 主要辅助参数:
model.query
NearestNeighborsModel.save
NearestNeighborsModel.similarity_graph
NearestNeighborsModel.summary.
1.4 近邻的方法method
大体有以下几种:LSH、auto、brute_force、ball_tree
.
二、两大模块:查询模块 query
2.1 主函数
NearestNeighborsModel.query(dataset, label=None, k=5, radius=None, verbose=True)dataset:数据集
label:
k:返回前K个数据
radius:半径,半径小于radius才能返回
verbose:
.
2.2 常规举例
sf = turicreate.SFrame({'label': range(3),
'feature1': [0.98, 0.62, 0.11],
'feature2': [0.69, 0.58, 0.36]})
model = turicreate.nearest_neighbors.create(sf, 'label')
queries = turicreate.SFrame({'label': ['a','b','c'],
'feature1': [0.05, 0.61, 0.99],
'feature2': [0.06, 0.97, 0.86]})
model.query(queries, 'label', k=2)sf是数据集,其中看到了label可以代表三个个案例的名称;
create(sf, ‘label’),以label为三个案例的名称进行初始化;
queries为查询的数据集。
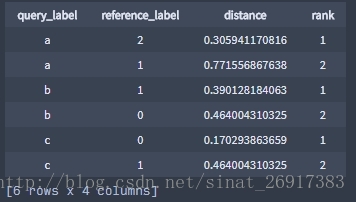
.
三、两大模块:相似图谱模块
这个模块在第二篇提到过:《极简主义︱利用apple机器学习平台Turicreate实现图像相似性检索(二)》
similarity_graph(k=5, radius=None, include_self_edges=False, output_type='SGraph', verbose=True)
k:最大返回样本数
radius:float,半径范围,如果超过radius个间隔,就不显示
include_self_edges:是否包含自己,True的话,返回的结果包含自己(自己的相似性为1)
output_type:‘SGraph’, ‘SFrame’两种
verbose:打印进度更新和模型细节。常规例子:
sf = turicreate.SFrame({'label': range(3),
'feature1': [0.98, 0.62, 0.11],
'feature2': [0.69, 0.58, 0.36]})
model = turicreate.nearest_neighbors.create(sf, 'label')
sim_graph = model.similarity_graph(k=3)
sim_graph.edges.
四、近邻create中距离的介绍
4.1 apple.Turicreate中的距离
apple.Turicreate中有很多距离可以直接用:
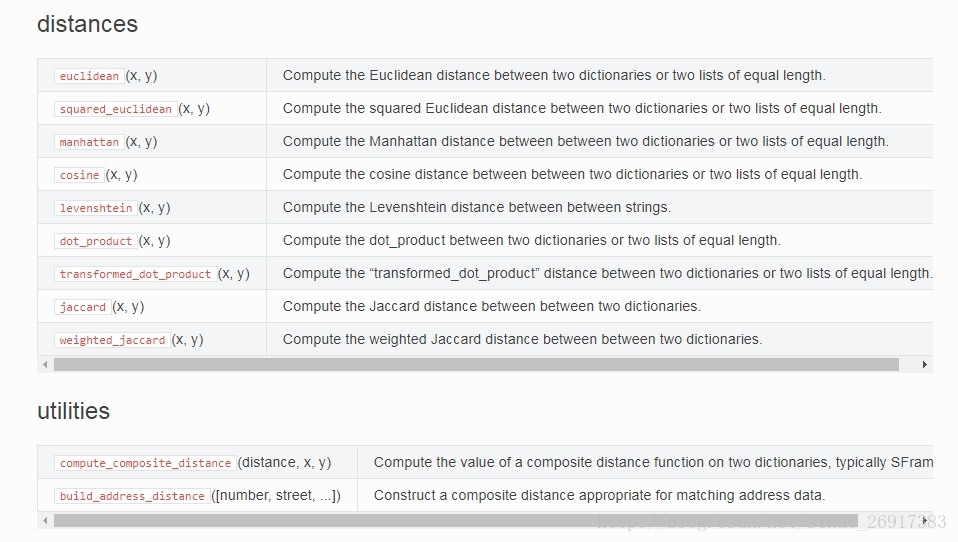
# euclidean
tc.distances.euclidean([1, 2, 3], [4, 5, 6])
tc.distances.euclidean({'a': 2, 'c': 4}, {'b': 3, 'c': 12})
# squared_euclidean
tc.distances.squared_euclidean([1, 2, 3], [4, 5, 6])
tc.distances.squared_euclidean({'a': 2, 'c': 4},
{'b': 3, 'c': 12})
# manhattan
tc.distances.manhattan([1, 2, 3], [4, 5, 6])
tc.distances.manhattan({'a': 2, 'c': 4}, {'b': 3, 'c': 12})
# cosine
tc.distances.cosine([1, 2, 3], [4, 5, 6])
tc.distances.cosine({'a': 2, 'c': 4}, {'b': 3, 'c': 12})
# levenshtein 字符距离
tc.distances.levenshtein("fossa", "fossil")
# dot_product
tc.distances.dot_product([1, 2, 3], [4, 5, 6])
tc.distances.dot_product({'a': 2, 'c': 4}, {'b': 3, 'c': 12})
# transformed_dot_product
tc.distances.transformed_dot_product([1, 2, 3], [4, 5, 6])
tc.distances.transformed_dot_product({'a': 2, 'c': 4}, {'b': 3, 'c': 12})
# jaccard
tc.distances.jaccard({'a': 2, 'c': 4}, {'b': 3, 'c': 12})
# weighted_jaccard
tc.distances.weighted_jaccard({'a': 2, 'c': 4},
{'b': 3, 'c': 12})
# 复合距离
>>> sf = turicreate.SFrame({'X1': [0.98, 0.62, 0.11],
... 'X2': [0.69, 0.58, 0.36],
... 'species': ['cat', 'dog', 'fossa']})
...
>>> dist_spec = [[('X1', 'X2'), 'euclidean', 2],
... [('species',), 'levenshtein', 0.4]]
...
>>> d = turicreate.distances.compute_composite_distance(dist_spec, sf[0], sf[1])
>>> print d
1.95286120899
# turicreate.toolkits.distances.build_address_distance
>>> homes = turicreate.SFrame({'sqft': [1230, 875, 1745],
... 'street': ['phinney', 'fairview', 'cottage'],
... 'city': ['seattle', 'olympia', 'boston'],
... 'state': ['WA', 'WA', 'MA']})
...
>>> my_dist = turicreate.distances.build_address_distance(street='street',
... city='city',
... state='state')
>>> my_dist
[[['street'], 'jaccard', 5],
[['state'], 'jaccard', 5],
[['city'], 'levenshtein', 1]].
4.2 create中更换距离的方式
# manhattan距离
model = tc.nearest_neighbors.create(sf, features=['bedroom', 'bath', 'size'],
distance='manhattan')
model.summary()此时用的create中模块的距离distance中的曼哈顿距离。
# tc自带的tc.distances.manhattan距离
model = tc.nearest_neighbors.create(sf, features=['bedroom', 'bath', 'size'],
distance=tc.distances.manhattan)
knn = model.query(sf[:3], k=3)
knn.print_rows()另外一种是tc单独的距离模块:tc.distances.manhattan
tc单独的距离模块的一些案例:
sf_check = sf[['bedroom', 'bath', 'size']]
print "distance check 1:", tc.distances.manhattan(sf_check[2], sf_check[10])
print "distance check 2:", tc.distances.manhattan(sf_check[2], sf_check[14]).
4.3 复合距离
案例一:
my_dist = [[['bedroom', 'bath'], 'manhattan', 1],
[['size', 'lot'], 'euclidean', 2]]
model = tc.nearest_neighbors.create(sf, distance=my_dist)
model.summary()
# 分开求距离案例二:
>>> my_dist = [[['X1', 'X2'], 'euclidean', 2.],
... [['str_feature'], 'levenshtein', 3.]]
...
>>> model = turicreate.nearest_neighbors.create(sf, distance=my_dist)个性化的判定,某些指标之间选择特定的距离函数。
.
五、近邻create中method的介绍
大体有以下三种:
- auto (default): the method is chosen automatically, based on the type
of data and the distance. If the distance is ‘manhattan’ or
‘euclidean’ and the features are numeric or vectors of numeric
values, then the ‘ball_tree’ method is used. Otherwise, the
‘brute_force’ method is used. - ball_tree: use a tree structure to find the k-closest neighbors to
each query point. The ball tree model is slower to construct than the
brute force model, but queries are faster than linear time. This
method is not applicable for the cosine and dot product distances.
See Liu, et al (2004) for implementation details. - brute_force: compute the distance from a query point to all reference
observations. There is no computation time for model creation with
the brute force method (although the reference data is held in the
model, but each query takes linear time. - lsh: use Locality Sensitive Hashing (LSH) to find approximate nearest
neighbors efficiently. The LSH model supports ‘euclidean’,
‘squared_euclidean’, ‘manhattan’, ‘cosine’, ‘jaccard’, ‘dot_product’
(deprecated), and ‘transformed_dot_product’ distances. Two options
are provided for LSH – num_tables and num_projections_per_table. See
the notes below for details.
笔者对LSH很感兴趣。
model = tc.nearest_neighbors.create(sf)
model = tc.nearest_neighbors.create(sf, features=['bedroom', 'bath', 'size'],method = 'lsh')
model.summary()method 唯一改变的就是这里,当然还可以选择几个特定的参数:
num_tables/num_projections_per_table
.
六、一个实战案例
数据准备并标准化
import turicreate as tc
url = 'https://static.turi.com/datasets/regression/houses.csv'
sf = tc.SFrame.read_csv(url)
sf.head(5)
# 数据标准化
for c in sf.column_names():
sf[c] = (sf[c] - sf[c].mean()) / sf[c].std()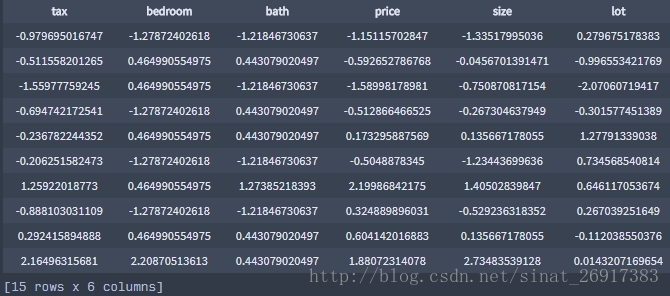
数据准备好之后,进行建模:
#建模
model = tc.nearest_neighbors.create(sf)
model = tc.nearest_neighbors.create(sf, features=['bedroom', 'bath', 'size'])
model.summary()模型建立好之后就可以进行两个主要模块的调用:
- 查询:
knn = model.query(sf[:5], k=5)
knn.head()这边数据操作的时候有个小问题,建模的时候是用
‘bedroom’, ‘bath’, ‘size’这三个指标,
但是查询的时候,即使给了超过三个(’bedroom’, ‘bath’, ‘size’)指标,计算的时候,也只是这三个。
这个比较好,但是指标名称一定要对应起来。
- 近邻图谱:
sim_graph = model.similarity_graph(k=3)
sim_graph.edges














 396
396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









