







.1 说明
当fst的写入过程和term的写入过程结合在一起,流程有较大差异,需要重新分析
.2 写入数据
.2-1 调用栈
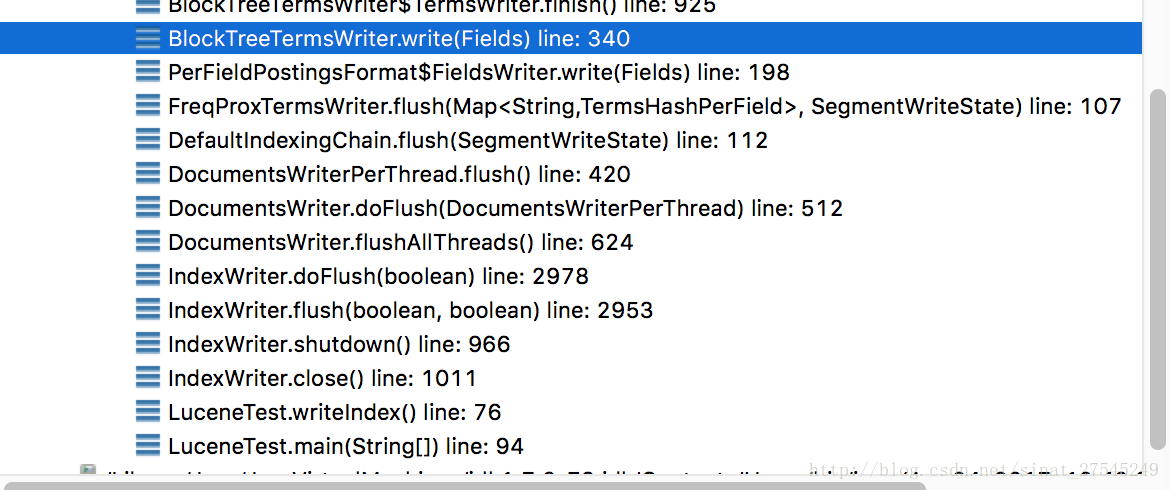
.2-2 源码分析
.2-2-1 write方法
public void write(Fields fields) throws IOException {
String lastField = null;
for(String field : fields) {//遍历每个字段
assert lastField == null || lastField.compareTo(field) < 0;
lastField = field;
Terms terms = fields.terms(field);
if (terms == null) {
continue;
}
TermsEnum termsEnum = terms.iterator(null);//生成该字段的term迭代器
TermsWriter termsWriter = new TermsWriter(fieldInfos.fieldInfo(field));
while (true) {
BytesRef term = termsEnum.next();
if (term == null) {
break;
}
termsWriter.write(term, termsEnum);//写term相关的数据,可能会写索引,也可能不写,根据一定的条件进行判断
}
termsWriter.finish();
}
}.2-2-2 BlockTreeTermWriter的write方法
public void write(BytesRef text, TermsEnum termsEnum) throws IOException {
/*
if (DEBUG) {
int[] tmp = new int[lastTerm.length];
System.arraycopy(prefixStarts, 0, tmp, 0, tmp.length);
System.out.println("BTTW: write term=" + brToString(text) + " prefixStarts=" + Arrays.toString(tmp) + " pending.size()=" + pending.size());
}
*/
BlockTermState state = postingsWriter.writeTerm(text, termsEnum, docsSeen);
if (state != null) {
assert state.docFreq != 0;
assert fieldInfo.getIndexOptions() == IndexOptions.DOCS || state.totalTermFreq >= state.docFreq: "postingsWriter=" + postingsWriter;
sumDocFreq += state.docFreq;
sumTotalTermFreq += state.totalTermFreq;
pushTerm(text);//最重要的方法,对term进行block切分,写入tim文件,并可能写入索引文件tip
PendingTerm term = new PendingTerm(text, state);
pending.add(term);//对之前的term处理完之后,再把该term添加到pending栈中
numTerms++;
if (firstPendingTerm == null) {
firstPendingTerm = term;
}
lastPendingTerm = term;
}
}.2-2-3 BlockTreeTermWriter的pushterm方法
int limit = Math.min(lastTerm.length(), text.length);
// Find common prefix between last term and current term:
//找到当前term和上一个term公共前缀的长度
int pos = 0;
while (pos < limit && lastTerm.byteAt(pos) == text.bytes[text.offset+pos]) {
pos++;
}
// if (DEBUG) System.out.println(" shared=" + pos + " lastTerm.length=" + lastTerm.length);
// Close the "abandoned" suffix now:
//从公共前缀长度往前开始判断,例如第一次判断公共前缀abc,如果没有可写入到block的,则开始判断ab前缀的term数量是否满足写block,如果还没有,就找a为前缀的
for(int i=lastTerm.length()-1;i>=pos;i--) {
// How many items on top of the stack share the current suffix
// we are closing:
//假设pending的大小是5,前缀长度为3的term个数是4,(5-4)<2(minItemsInBlock),不满足;
//下来找前缀长度是2的term,假如个数是2,(6-2)>2,满足条件,开始写block。也就是说,共同前缀越短,
//越有可能被写block。例如abc,abdf,abdg,abdh四个term,abd前缀不会被写,而ab前缀会被写
int prefixTopSize = pending.size() - prefixStarts[i];
if (prefixTopSize >= minItemsInBlock) {
// if (DEBUG) System.out.println("pushTerm i=" + i + " prefixTopSize=" + prefixTopSize + " minItemsInBlock=" + minItemsInBlock);
writeBlocks(i+1, prefixTopSize);//写入blocks,因为可能会有多个term累积,所以可能生成多个block
prefixStarts[i] -= prefixTopSize-1;
}
}
if (prefixStarts.length < text.length) {
prefixStarts = ArrayUtil.grow(prefixStarts, text.length);
}
// Init new tail:
for(int i=pos;i<text.length;i++) {
prefixStarts[i] = pending.size();
}
lastTerm.copyBytes(text);
.2-2-3 BlockTreeTermWriter的writerblocks方法(还没添加注释)
void writeBlocks(int prefixLength, int count) throws IOException {
assert count > 0;
/*
if (DEBUG) {
BytesRef br = new BytesRef(lastTerm.bytes);
br.offset = lastTerm.offset;
br.length = prefixLength;
System.out.println("writeBlocks: " + br.utf8ToString() + " count=" + count);
}
*/
// Root block better write all remaining pending entries:
assert prefixLength > 0 || count == pending.size();
int lastSuffixLeadLabel = -1;
// True if we saw at least one term in this block (we record if a block
// only points to sub-blocks in the terms index so we can avoid seeking
// to it when we are looking for a term):
boolean hasTerms = false;
boolean hasSubBlocks = false;
int start = pending.size()-count;//pending里的并不是所有都写,所以要计算起始地址和结束地址
int end = pending.size();
int nextBlockStart = start;
int nextFloorLeadLabel = -1;
for (int i=start; i<end; i++) {
PendingEntry ent = pending.get(i);
int suffixLeadLabel;
if (ent.isTerm) {
PendingTerm term = (PendingTerm) ent;
if (term.termBytes.length == prefixLength) {
// Suffix is 0, i.e. prefix 'foo' and term is
// 'foo' so the term has empty string suffix
// in this block
assert lastSuffixLeadLabel == -1;
suffixLeadLabel = -1;
} else {
suffixLeadLabel = term.termBytes[prefixLength] & 0xff;
}
} else {
PendingBlock block = (PendingBlock) ent;
assert block.prefix.length > prefixLength;
suffixLeadLabel = block.prefix.bytes[block.prefix.offset + prefixLength] & 0xff;//更新后缀
}
// if (DEBUG) System.out.println(" i=" + i + " ent=" + ent + " suffixLeadLabel=" + suffixLeadLabel);
if (suffixLeadLabel != lastSuffixLeadLabel) {
int itemsInBlock = i - nextBlockStart;
//写block要满足两个条件,1.要写入block的term数,是否大于minItemsInBlock;
//2.本次剩余要写入的term总数是否大于maxItemsInBlock
if (itemsInBlock >= minItemsInBlock && end-nextBlockStart > maxItemsInBlock) {
// The count is too large for one block, so we must break it into "floor" blocks, where we record
// the leading label of the suffix of the first term in each floor block, so at search time we can
// jump to the right floor block. We just use a naive greedy segmenter here: make a new floor
// block as soon as we have at least minItemsInBlock. This is not always best: it often produces
// a too-small block as the final block:
boolean isFloor = itemsInBlock < count;//这个isfloor的判断还不懂
newBlocks.add(writeBlock(prefixLength, isFloor, nextFloorLeadLabel, nextBlockStart, i, hasTerms, hasSubBlocks));//写入一批term,并生成一个block
hasTerms = false;
hasSubBlocks = false;
nextFloorLeadLabel = suffixLeadLabel;
nextBlockStart = i;
}
lastSuffixLeadLabel = suffixLeadLabel;
}
if (ent.isTerm) {
hasTerms = true;
} else {
hasSubBlocks = true;
}
}
// Write last block, if any:
//写最后一期term组成的block,这个block可能不存在,因为可能在上边的循环中,所有的term都被写成了block
if (nextBlockStart < end) {
int itemsInBlock = end - nextBlockStart;
boolean isFloor = itemsInBlock < count;
newBlocks.add(writeBlock(prefixLength, isFloor, nextFloorLeadLabel, nextBlockStart, end, hasTerms, hasSubBlocks));
}
assert newBlocks.isEmpty() == false;
PendingBlock firstBlock = newBlocks.get(0);
assert firstBlock.isFloor || newBlocks.size() == 1;
//fst索引的生成,是以第一个block领衔的,写入后,只有第一个block的index会被更新
firstBlock.compileIndex(newBlocks, scratchBytes, scratchIntsRef);
// Remove slice from the top of the pending stack, that we just wrote:
//从栈pending中删除已经写成block的term或者block,请把新生成的block添加到栈顶
pending.subList(pending.size()-count, pending.size()).clear();
// Append new block
pending.add(firstBlock);
newBlocks.clear();
}.2-2-5 BlockTreeTermWriter的writeblock方法
/** Writes the specified slice (start is inclusive, end is exclusive)
* from pending stack as a new block. If isFloor is true, there
* were too many (more than maxItemsInBlock) entries sharing the
* same prefix, and so we broke it into multiple floor blocks where
* we record the starting label of the suffix of each floor block. */
private PendingBlock writeBlock(int prefixLength, boolean isFloor, int floorLeadLabel, int start, int end, boolean hasTerms, boolean hasSubBlocks) throws IOException {
assert end > start;
long startFP = termsOut.getFilePointer();
boolean hasFloorLeadLabel = isFloor && floorLeadLabel != -1;
final BytesRef prefix = new BytesRef(prefixLength + (hasFloorLeadLabel ? 1 : 0));
System.arraycopy(lastTerm.get().bytes, 0, prefix.bytes, 0, prefixLength);
prefix.length = prefixLength;
// Write block header:
int numEntries = end - start;
int code = numEntries << 1;
if (end == pending.size()) {
// Last block:
code |= 1;
}
termsOut.writeVInt(code);
/*
if (DEBUG) {
System.out.println(" writeBlock " + (isFloor ? "(floor) " : "") + "seg=" + segment + " pending.size()=" + pending.size() + " prefixLength=" + prefixLength + " indexPrefix=" + brToString(prefix) + " entCount=" + (end-start+1) + " startFP=" + startFP + (isFloor ? (" floorLeadLabel=" + Integer.toHexString(floorLeadLabel)) : ""));
}
*/
// 1st pass: pack term suffix bytes into byte[] blob
// TODO: cutover to bulk int codec... simple64?
// We optimize the leaf block case (block has only terms), writing a more
// compact format in this case:
boolean isLeafBlock = hasSubBlocks == false;
final List<FST<BytesRef>> subIndices;
boolean absolute = true;
if (isLeafBlock) {
// Only terms:
subIndices = null;
for (int i=start;i<end;i++) {
PendingEntry ent = pending.get(i);
assert ent.isTerm: "i=" + i;
PendingTerm term = (PendingTerm) ent;
assert StringHelper.startsWith(term.termBytes, prefix): "term.term=" + term.termBytes + " prefix=" + prefix;
BlockTermState state = term.state;
final int suffix = term.termBytes.length - prefixLength;
/*
if (DEBUG) {
BytesRef suffixBytes = new BytesRef(suffix);
System.arraycopy(term.termBytes, prefixLength, suffixBytes.bytes, 0, suffix);
suffixBytes.length = suffix;
System.out.println(" write term suffix=" + brToString(suffixBytes));
}
*/
// For leaf block we write suffix straight
suffixWriter.writeVInt(suffix);
suffixWriter.writeBytes(term.termBytes, prefixLength, suffix);
assert floorLeadLabel == -1 || (term.termBytes[prefixLength] & 0xff) >= floorLeadLabel;
// Write term stats, to separate byte[] blob:
statsWriter.writeVInt(state.docFreq);
if (fieldInfo.getIndexOptions() != IndexOptions.DOCS) {
assert state.totalTermFreq >= state.docFreq: state.totalTermFreq + " vs " + state.docFreq;
statsWriter.writeVLong(state.totalTermFreq - state.docFreq);
}
// Write term meta data
postingsWriter.encodeTerm(longs, bytesWriter, fieldInfo, state, absolute);
for (int pos = 0; pos < longsSize; pos++) {
assert longs[pos] >= 0;
metaWriter.writeVLong(longs[pos]);
}
bytesWriter.writeTo(metaWriter);
bytesWriter.reset();
absolute = false;
}
} else {
// Mixed terms and sub-blocks:
subIndices = new ArrayList<>();
for (int i=start;i<end;i++) {
PendingEntry ent = pending.get(i);
if (ent.isTerm) {
PendingTerm term = (PendingTerm) ent;
assert StringHelper.startsWith(term.termBytes, prefix): "term.term=" + term.termBytes + " prefix=" + prefix;
BlockTermState state = term.state;
final int suffix = term.termBytes.length - prefixLength;
/*
if (DEBUG) {
BytesRef suffixBytes = new BytesRef(suffix);
System.arraycopy(term.termBytes, prefixLength, suffixBytes.bytes, 0, suffix);
suffixBytes.length = suffix;
System.out.println(" write term suffix=" + brToString(suffixBytes));
}
*/
// For non-leaf block we borrow 1 bit to record
// if entry is term or sub-block
suffixWriter.writeVInt(suffix<<1);
suffixWriter.writeBytes(term.termBytes, prefixLength, suffix);
assert floorLeadLabel == -1 || (term.termBytes[prefixLength] & 0xff) >= floorLeadLabel;
// Write term stats, to separate byte[] blob:
statsWriter.writeVInt(state.docFreq);
if (fieldInfo.getIndexOptions() != IndexOptions.DOCS) {
assert state.totalTermFreq >= state.docFreq;
statsWriter.writeVLong(state.totalTermFreq - state.docFreq);
}
// TODO: now that terms dict "sees" these longs,
// we can explore better column-stride encodings
// to encode all long[0]s for this block at
// once, all long[1]s, etc., e.g. using
// Simple64. Alternatively, we could interleave
// stats + meta ... no reason to have them
// separate anymore:
// Write term meta data
postingsWriter.encodeTerm(longs, bytesWriter, fieldInfo, state, absolute);
for (int pos = 0; pos < longsSize; pos++) {
assert longs[pos] >= 0;
metaWriter.writeVLong(longs[pos]);
}
bytesWriter.writeTo(metaWriter);
bytesWriter.reset();
absolute = false;
} else {
PendingBlock block = (PendingBlock) ent;
assert StringHelper.startsWith(block.prefix, prefix);
final int suffix = block.prefix.length - prefixLength;
assert suffix > 0;
// For non-leaf block we borrow 1 bit to record
// if entry is term or sub-block
suffixWriter.writeVInt((suffix<<1)|1);
suffixWriter.writeBytes(block.prefix.bytes, prefixLength, suffix);
assert floorLeadLabel == -1 || (block.prefix.bytes[prefixLength] & 0xff) >= floorLeadLabel;
assert block.fp < startFP;
/*
if (DEBUG) {
BytesRef suffixBytes = new BytesRef(suffix);
System.arraycopy(block.prefix.bytes, prefixLength, suffixBytes.bytes, 0, suffix);
suffixBytes.length = suffix;
System.out.println(" write sub-block suffix=" + brToString(suffixBytes) + " subFP=" + block.fp + " subCode=" + (startFP-block.fp) + " floor=" + block.isFloor);
}
*/
suffixWriter.writeVLong(startFP - block.fp);
subIndices.add(block.index);
}
}
assert subIndices.size() != 0;
}
// TODO: we could block-write the term suffix pointers;
// this would take more space but would enable binary
// search on lookup
// Write suffixes byte[] blob to terms dict output:
termsOut.writeVInt((int) (suffixWriter.getFilePointer() << 1) | (isLeafBlock ? 1:0));
suffixWriter.writeTo(termsOut);
suffixWriter.reset();
// Write term stats byte[] blob
termsOut.writeVInt((int) statsWriter.getFilePointer());
statsWriter.writeTo(termsOut);
statsWriter.reset();
// Write term meta data byte[] blob
termsOut.writeVInt((int) metaWriter.getFilePointer());
metaWriter.writeTo(termsOut);
metaWriter.reset();
// if (DEBUG) {
// System.out.println(" fpEnd=" + out.getFilePointer());
// }
if (hasFloorLeadLabel) {
// We already allocated to length+1 above:
prefix.bytes[prefix.length++] = (byte) floorLeadLabel;
}
return new PendingBlock(prefix, startFP, hasTerms, isFloor, floorLeadLabel, subIndices);
}













 6716
6716











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









