







在开发完Spark作业之后,就该为作业配置合适的资源了。Spark的资源参数,基本都可以在spark-submit命令中作为参数设置。很多Spark初学者,通常不知道该设置哪些必要的参数,以及如何设置这些参数,最后就只能胡乱设置,甚至压根儿不设置。资源参数设置的不合理,可能会导致没有充分利用集群资源,作业运行会极其缓慢;或者设置的资源过大,队列没有足够的资源来提供,进而导致各种异常。总之,无论是哪种情况,都会导致Spark作业的运行效率低下,甚至根本无法运行。因此我们必须对Spark作业的资源使用原理有一个清晰的认识,并知道在Spark作业运行过程中,有哪些资源参数是可以设置的,以及如何设置合适的参数值。
1、Spark作业基本运行原理
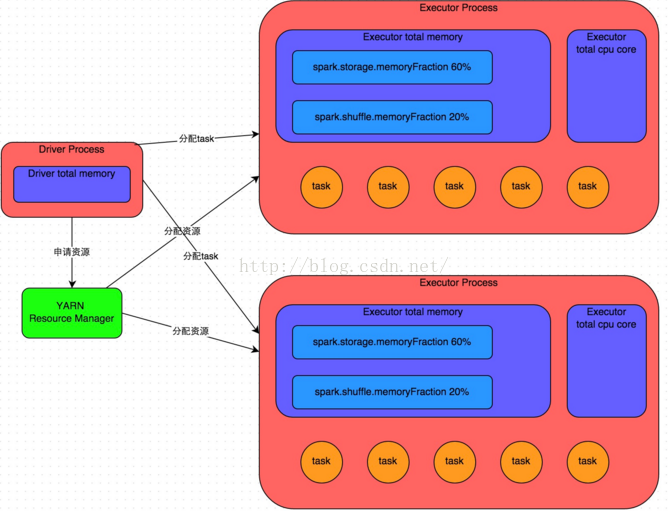
详细原理见上图。我们使用spark-submit提交一个Spark作业之后,这个作业就会启动一个对应的Driver进程。根据你使用的部署模式(deploy-mode)不同,Driver进程可能在本地启动,也可能在集群中某个工作节点上启动。Driver进程本身会根据我们设置的参数,占有一定数量的内存和CPU core。而Driver进程要做的第一件事情,就是向集群管理器(可以是Spark Standalone集群,也可以是其他的资源管理集群,美团•大众点评使用的是YARN作为资源管理集群)申请运行Spark作业需要使用的资源,这里的资源指的就是Executor进程。YARN集群管理器会根据我们为Spark作业设置的资源参数,在各个工作节点上,启动一定数量的Executor进程,每个Executor进程都占有一定数量的内存和CPU core。
在申请到了作业执行所需的资源之后,Driver进程就会开始调度和执行我们编写的作业代码了。Driver进程会将我们编写的Spark作业代码分拆为多个stage,每个stage执行一部分代码片段,并为每个stage创建一批task,然后将这些task分配到各个Executor进程中执行。task是最小的计算单元,负责执行一模一样的计算逻辑(也就是我们自己编写的某个代码片段),只是每个task处理的数据不同而已。一个stage的所有task都执行完毕之后,会在各个节点本地的磁盘文件中写入计算中间结果,然后Driver就会调度运行下一个stage。下一个stage的task的输入数据就是上一个stage输出的中间结果。如此循环往复,直到将我们自己编写的代码逻辑全部执行完,并且计算完所有的数据,得到我们想要的结果为止。
Spark是根据shuffle类算子来进行stage的划分。如果我们的代码中执行了某个shuffle类算子(比如reduceByKey、join等),那么就会在该算子处,划分出一个stage界限来。可以大致理解为,shuffle算子执行之前的代码会被划分为一个stage,shuffle算子执行以及之后的代码会被划分为下一个stage。因此一个stage刚开始执行的时候,它的每个task可能都会从上一个stage的task所在的节点,去通过网络传输拉取需要自己处理的所有key,然后对拉取到的所有相同的key使用我们自己编写的算子函数执行聚合操作(比如reduceByKey()算子接收的函数)。这个过程就是shuffle。
当我们在代码中执行了cache/persist等持久化操作时,根据我们选择的持久化级别的不同,每个task计算出来的数据也会保存到Executor进程的内存或者所在节点的磁盘文件中。
因此Executor的内存主要分为三块:第一块是让task执行我们自己编写的代码时使用,默认是占Executor总内存的20%;第二块是让task通过shuffle过程拉取了上一个stage的task的输出后,进行聚合等操作时使用,默认也是占Executor总内存的20%;第三块是让RDD持久化时使用,默认占Executor总内存的60%。
task的执行速度是跟每个Executor进程的CPU core数量有直接关系的。一个CPU core同一时间只能执行一个线程。而每个Executor进程上分配到的多个task,都是以每个task一条线程的方式,多线程并发运行的。如果CPU core数量比较充足,而且分配到的task数量比较合理,那么通常来说,可以比较快速和高效地执行完这些task线程。
以上就是Spark作业的基本运行原理的说明,大家可以结合上图来理解。理解作业基本原理,是我们进行资源参数调优的基本前提。
2、资源参数调优
了解完了Spark作业运行的基本原理之后,对资源相关的参数就容易理解了。所谓的Spark资源参数调优,其实主要就是对Spark运行过程中各个使用资源的地方,通过调节各种参数,来优化资源使用的效率,从而提升Spark作业的执行性能。以下参数就是Spark中主要的资源参数,每个参数都对应着作业运行原理中的某个部分,我们同时也给出了一个调优的参考值。
num-executors
参数说明:该参数用于设置Spark作业总共要用多少个Executor进程来执行。Driver在向YARN集群管理器申请资源时,YARN集群管理器会尽可能按照你的设置来在集群的各个工作节点上,启动相应数量的Executor进程。这个参数非常之重要,如果不设置的话,默认只会给你启动少量的Executor进程,此时你的Spark作业的运行速度是非常慢的。
参数调优建议:每个Spark作业的运行一般设置50~100个左右的Executor进程比较合适,设置太少或太多的Executor进程都不好。设置的太少,无法充分利用集群资源;设置的太多的话,大部分队列可能无法给予充分的资源。
executor-memory
参数说明:该参数用于设置每个Executor进程的内存。Executor内存的大小,很多时候直接决定了Spark作业的性能,而且跟常见的JVM OOM异常,也有直接的关联。
参数调优建议:每个Executor进程的内存设置4G~8G较为合适。但是这只是一个参考值,具体的设置还是得根据不同部门的资源队列来定。可以看看自己团队的资源队列的最大内存限制是多少,num-executors乘以executor-memory,就代表了你的Spark作业申请到的总内存量(也就是所有Executor进程的内存总和),这个量是不能超过队列的最大内存量的。此外,如果你是跟团队里其他人共享这个资源队列,那么申请的总内存量最好不要超过资源队列最大总内存的1/3~1/2,避免你自己的Spark作业占用了队列所有的资源,导致别的同学的作业无法运行。
executor-cores
参数说明:该参数用于设置每个Executor进程的CPU core数量。这个参数决定了每个Executor进程并行执行task线程的能力。因为每个CPU core同一时间只能执行一个task线程,因此每个Executor进程的CPU core数量越多,越能够快速地执行完分配给自己的所有task线程。
参数调优建议:Executor的CPU core数量设置为2~4个较为合适。同样得根据不同部门的资源队列来定,可以看看自己的资源队列的最大CPU core限制是多少,再依据设置的Executor数量,来决定每个Executor进程可以分配到几个CPU core。同样建议,如果是跟他人共享这个队列,那么num-executors * executor-cores不要超过队列总CPU core的1/3~1/2左右比较合适,也是避免影响其他同学的作业运行。
driver-memory
参数说明:该参数用于设置Driver进程的内存。
参数调优建议:Driver的内存通常来说不设置,或者设置1G左右应该就够了。唯一需要注意的一点是,如果需要使用collect算子将RDD的数据全部拉取到Driver上进行处理,那么必须确保Driver的内存足够大,否则会出现OOM内存溢出的问题。
spark.default.parallelism
参数说明:该参数用于设置每个stage的默认task数量。这个参数极为重要,如果不设置可能会直接影响你的Spark作业性能。
参数调优建议:Spark作业的默认task数量为500~1000个较为合适。很多同学常犯的一个错误就是不去设置这个参数,那么此时就会导致Spark自己根据底层HDFS的block数量来设置task的数量,默认是一个HDFS block对应一个task。通常来说,Spark默认设置的数量是偏少的(比如就几十个task),如果task数量偏少的话,就会导致你前面设置好的Executor的参数都前功尽弃。试想一下,无论你的Executor进程有多少个,内存和CPU有多大,但是task只有1个或者10个,那么90%的Executor进程可能根本就没有task执行,也就是白白浪费了资源!因此Spark官网建议的设置原则是,设置该参数为num-executors * executor-cores的2~3倍较为合适,比如Executor的总CPU core数量为300个,那么设置1000个task是可以的,此时可以充分地利用Spark集群的资源。
spark.storage.memoryFraction
参数说明:该参数用于设置RDD持久化数据在Executor内存中能占的比例,默认是0.6。也就是说,默认Executor 60%的内存,可以用来保存持久化的RDD数据。根据你选择的不同的持久化策略,如果内存不够时,可能数据就不会持久化,或者数据会写入磁盘。
参数调优建议:如果Spark作业中,有较多的RDD持久化操作,该参数的值可以适当提高一些,保证持久化的数据能够容纳在内存中。避免内存不够缓存所有的数据,导致数据只能写入磁盘中,降低了性能。但是如果Spark作业中的shuffle类操作比较多,而持久化操作比较少,那么这个参数的值适当降低一些比较合适。此外,如果发现作业由于频繁的gc导致运行缓慢(通过spark web ui可以观察到作业的gc耗时),意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。
spark.shuffle.memoryFraction
参数说明:该参数用于设置shuffle过程中一个task拉取到上个stage的task的输出后,进行聚合操作时能够使用的Executor内存的比例,默认是0.2。也就是说,Executor默认只有20%的内存用来进行该操作。shuffle操作在进行聚合时,如果发现使用的内存超出了这个20%的限制,那么多余的数据就会溢写到磁盘文件中去,此时就会极大地降低性能。
参数调优建议:如果Spark作业中的RDD持久化操作较少,shuffle操作较多时,建议降低持久化操作的内存占比,提高shuffle操作的内存占比比例,避免shuffle过程中数据过多时内存不够用,必须溢写到磁盘上,降低了性能。此外,如果发现作业由于频繁的gc导致运行缓慢,意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。
资源参数的调优,没有一个固定的值,需要同学们根据自己的实际情况(包括Spark作业中的shuffle操作数量、RDD持久化操作数量以及spark web ui中显示的作业gc情况),同时参考本篇文章中给出的原理以及调优建议,合理地设置上述参数。
3、资源参数参考示例
以下是一份spark-submit命令的示例,大家可以参考一下,并根据自己的实际情况进行调节:
- ./bin/spark-submit \
- --master yarn-cluster \
- --num-executors 100 \
- --executor-memory 6G \
- --executor-cores 4 \
- --driver-memory 1G \
- --conf spark.default.parallelism=1000 \
- --conf spark.storage.memoryFraction=0.5 \
- --conf spark.shuffle.memoryFraction=0.3 \
Spark调优是需要根据业务需要调整的,并不是说某个设置是一成不变的,就比如机器学习一样,是在不断的调试中找出当前业务下更优的调优配置。下面零碎的总结了一些我的调优笔记。
spark 存储的时候存在严重的分配不均的现象,有几台机器在过渡使用, 有几台机器却很少被使用,有几台机器缓存了几十个上百个RDD blocks 有的机器一个RDD blocks 都没有,这样存储有RDD blocks 的可以进行运算,运算的tasks 最多为该机器core数。
spark.storage.memoryFraction 分配给用于缓存RDD的内存的比例
比如如果spark.executor.memory 30g spark.storage.memoryFraction 0.5 则用于缓存的内存为14G 多, 默认留一些做其他用。
每一个RDD blocks 的大小不一定是64兆 可能小于64兆,另外如果driver不是子节点,driver 程序运行的节点上的用于缓存的内存 ,就不会被使用。
事实上一个两三G 的数据 需要用的缓存也至少需要两三G,如果中间过程中还有产生RDD 且也需要缓存到内存,则需要分配更多的内存用于缓存。在缓存足够多的情况的
更多的内存不足错误提示(OOM) 来源于计算的时候产生的一些中间对象即计算所需要的内存。
所以分配用于缓存的内存 应该是这么算的, 比如我有10G的文件,4台机器,则每台机器至少2.5g缓存,如果每台机器分配给excutor 的内存为10g ,则memoryFraction 则至少为0.25 最好配大一些,但不能太大, 太大会导致计算内存不够。而且如果中间过程还有产生新的RDD,则需要根据实际情况调大memoryFraction。
RDD 缓存分布不均匀 是影响spark 的很大的性能之一,为什么这么说?
因为有的机器分配给用于RDD 缓存的内存都用完了 ,这样相对而言在这个机器上计算的开销也会大,有的机器缓存占用的内存很少,就算用这个机器来计算,还需要启动Node_local 模式,这样会影响计算的时间。
为什么一个2G 的数据,默认块大小为64M. default.parallelism 设置成100,可它总是不按这个数据来分,比如经常分成了108个blocks,影响partions个数的参数还有哪些?还有我明明有四个节点,但经常有节点被分配的RDD 和计算都很少很少,这种资源浪费的情况应该怎么调解?
《续》
1. spark性能配置
我目前的环境是5台机器,每台机器8个核。如果有以下两种配置方案:
(a)
SPARK_WORKER_INSTANCES = 8
SPARK_WORKER_CORES = 1
(b)
SPARK_WORKER_INSTANCES = 1
SPARK_WORKER_CORES = 8
如何处理?
答: a方案每个节点会启动8个worker运行8个JVM,每个worker将会启动一个excutors, b方案将会启动一个worker运行一个JVM。如果数据很小,选择b方案,因为可以节省启动JVM的开销,如果数据很大,启动JVM的时间可以忽略,则选a方案。
如果5台机器的内存都是48g,a,b方案在添加如下配置:
(a)SPARK_WORKER_MEMORY = 6g //给每个worker 分配6G 内存
(b)SPARK_WORKER_MEMORY = 48g
配置的时候注意:
SPARK_WORKER_CORES * SPARK_WORKER_INSTANCES= 每台机器总cores
2.Hadoop配置详解:
1.core-site.xml
常用的设置:
fs.default.name hdfs://mastername:9000
这是一个描述集群中NameNode结点的URI(包括协议、主机名称、端口号),集群里面的每一台机器都需要知道NameNode的地址。DataNode结点会先在NameNode上注册,这样它们的数据才可以被使用。独立的客户端程序通过这个URI跟DataNode交互,以取得文件的块列表。默认的文件系统的名称,默认的是设置单机配置,如果是伪分布式则设置hdfs://localhost:9000,如果是完全分布式则设置成hdfs://mastername:9000
hadoop.tmp.dir /tmp/hadoop-${user.name}
hadoop.tmp.dir是hadoop文件系统依赖的基础设置,很多路径都依赖它,如果hdfs-site.xml中不配置namenode和datanode的存放位置,默认就放在这个路径中,所以最好设置,而且设置到持久目录中。使用默认的路径会根据不同的用户名生成不同的临时目录。
优化参数:
hadoop.logfile.size 10000000 日志文件最大为10M
hadoop.logfile.count 10 日志文件数量为10个
hadoop跑了很多任务后,可以通过设置hadoop.logfile.size和hadoop.logfile.count来设定最大的日志大小和数量来自动清楚日志。
io.file.buffer.size 4096 流文件的缓冲区为4K
这是读写sequence file的buffer size,可以减少I/O次数,在大型的Hadoop cluster,建议使用更大的值。
hdfs-site.xml
常用设置:
dfs.replication 它决定着 系统里面的文件块的数据备份个数。对于一个实际的应用,它应该被设为3(这个数字并没有上限,但更多的备份可能并没有作用,而且会占用更多的空间)。少于三个的备份,可能会影响到数据的可靠性(系统故障时,也许会造成数据丢失)
dfs.data.dir 这是DataNode结点被指定要存储数据的本地文件系统路径。DataNode结点上的这个路径没有必要完全相同,因为每台机器的环境很可能是不一样的。但如果每台机器上的这个路径都是统一配置的话,会使工作变得简单一些。默认的情况下,它的hadoop.tmp.dir, 这个路径只能用于测试的目的,因为,它很可能会丢失掉一些数据。所以,这个值最好还是被覆盖。
dfs.name.dir 这是NameNode结点存储hadoop文件系统信息的本地系统路径。这个值只对NameNode有效,DataNode并不需要使用到它。上面对于/temp类型的警告,同样也适用于这里。在实际应用中,它最好被覆盖掉。
dfs.permissions true 文件操作时的权限检查标识,控制读写权限,false不控制读写权限。
dfs.block.size 67108864 缺省的文件块大小为64M
hadoop fsck /文件目录 –files –locations –blocks 查看文件存储信息
用法:hadoop fsck [GENERIC_OPTIONS]<path> [-move | -delete | -openforwrite] [-files [-blocks [-locations |-racks]]]
<path> 检查的起始目录。
-move 移动受损文件到/lost+found
-delete 删除受损文件。
-openforwrite 打印出写打开的文件。
-files 打印出正被检查的文件。
-blocks 打印出块信息报告。
-locations 打印出每个块的位置信息。
-racks 打印出data-node的网络拓扑结构。
dfs.namenode.logging.level info 输出日志类型
优化设置:
dfs.df.interval 60000 磁盘空间统计间隔为6秒
dfs.client.block.write.retries 3 块写入出错时的重试次数
dfs.heartbeat.interval 3 数据节点的心跳检测间隔时间
dfs.balance.bandwidthPerSec 1048576 启动负载均衡的数据节点可利用带宽最大值为1M
dfs.datanode.failed.volumes.tolerated 0
决定停止数据节点提供服务充许卷的出错次数。0次则任何卷出错都要停止数据节点。
dfs.datanode.data.dir.perm 755 数据节点的存贮块的目录访问权限设置
更多信息请参读:
http://hadoop.apache.org/docs/r2.2.0/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
mapred-site.xml
mapreduce.framework.name yarn
mapred.job.tracker mastername:9001 作业跟踪管理器是否和MR任务在一个进程中。默认值是local,单节点。Job 运行的host和端口号。
mapred.local.dir ${hadoop.tmp.dir}/mapred/local MR的中介数据文件存放目录
mapred.system.dir ${hadoop.tmp.dir}/mapred/system MR的控制文件存放目录
mapred.temp.dir ${hadoop.tmp.dir}/mapred/temp MR临时共享文件存放区
常见名词解释:
Driver:使用Driver这一概念的分布式框架很多,比如Hive等,spark中的Driver即运行Application的main() 函数并且创建SparkContext,创建sparkContext的目的是为了准备spark应用程序的运行环境,在spark中由SparkContext负责和clusterManager通信,进行资源的申请、任务的分配和监控等。当Excutor部分运行完毕后,Driver同时负责将SparkContext关闭,通常用SparkContext代表Driver。
Excutor:某个Appliction运行在Worker节点上的一个进程,该进程负责运行某些Task,并且负责将数据存在内存或者磁盘上。每个Application都有各自独立的一批Excutor。在Spark on yarn 模式下,进程名称为CoarseGrainedExcutorBackend。一个CoarseGrainedExcutorBackend进程有且仅有一个Excutor对象,它负责将Task包装成taskRunner,并从线程池中抽取出一个空闲线程运行Task,每个CoarseGrainedExcutorBackend能并行运行的Task的数量就取决于分配给他的cpu的个数了。
Cluster Manager:指的是在集群上获取资源的外部服务,目前有:
Standalone:Spark原生的资源管理,有Master负责资源的分配,可以在亚马逊的EC2上运行。
Apache Mesos:与Hadoop Mapreduce兼容性良好的一种资源调度框架;
Hadoop Yarn:主要是指的Yarn的ResourceManger;
cpu vcores 每个executor所使用的core的数量 这个参数决定了每个Executor进程并行执行task线程的能力。因为每个CPU core同一时间只能执行一个task线程,
因此每个Executor进程的CPU core数量越多,越能够快速地执行完分配给自己的所有task线程。
---Executor的CPU core数量设置为2~4个较为合适。同样得根据不同部门的资源队列来定,可以看看自己的资源队列的最大CPU core限制是多少,
再依据设置的Executor数量,来决定每个Executor进程可以分配到几个CPU core。同样建议,如果是跟他人共享这个队列,那么num-executors * executor-cores不要
超过队列总CPU core的1/3~1/2左右比较合适,也是避免影响其他同学的作业运行。
executor-memory 每一个executor使用的内存(MB).Executor内存的大小,很多时候直接决定了Spark作业的性能,而且跟常见的JVM OOM异常,也有直接的关联。
每个Executor进程的内存设置4G~8G较为合适。但是这只是一个参考值,具体的设置还是得根据不同部门的资源队列来定。可以看看自己团队的
资源队列的最大内存限制是多少,num-executors乘以executor-memory,就代表了你的Spark作业申请到的总内存量(也就是所有Executor进程的内存总和),
这个量是不能超过队列的最大内存量的。此外,如果你是跟团队里其他人共享这个资源队列,那么申请的总内存量最好不要超过资源队列最大总内存的1/3~1/2,
避免你自己的Spark作业占用了队列所有的资源,导致别的同学的作业无法运行。
num-executors 应用需要运行的Executor数量,该参数用于设置Spark作业总共要用多少个Executor进程来执行。Driver在向YARN集群管理器申请资源时,
YARN集群管理器会尽可能按照你的设置来在集群的各个工作节点上,启动相应数量的Executor进程。这个参数非常之重要,如果不设置的话,
默认只会给你启动少量的Executor进程,此时你的Spark作业的运行速度是非常慢的。
每个Spark作业的运行一般设置50~100个左右的Executor进程比较合适,设置太少或太多的Executor进程都不好。设置的太少,
无法充分利用集群资源;设置的太多的话,大部分队列可能无法给予充分的资源。
转自:http://www.cnblogs.com/hd-zg/p/6089207.html














 623
623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









