







http://blog.csdn.net/gangchengzhong/article/details/54969615
本文使用3台测试服务器,下面是各服务器的角色:
- node1:Worker
- node2:Worker
- node3:Master, Worker
1. 配置hosts文件
本文使用RedHat是在 /etc/hosts,新增3台测试服务器的ip/hostname对应关系(根据服务器实际情况修改下面的值):
$ vi /etc/hosts
- xxx.100 node1
- xxx.101 node2
- xxx.102 node3
xxx.100 node1
xxx.101 node2
xxx.102 node3分别修改所有的服务器
2. 下载和解压Spark
2.1 下载链接:
http://mirrors.hust.edu.cn/apache/spark/spark-2.1.0/spark-2.1.0-bin-hadoop2.7.tgz
* 上面的下载link使用的是其中一个镜像
* 可自行修改上面的link下载相应的版本
* 如果不能访问公网,则需要自行下载然后上传到服务器
2.2 执行以下命令解压
$ tar xvf spark-2.1.0-bin-hadoop2.7.tgz
3. 创建用户和群组
本文使用组spark和用户spark
3.1 使用groupadd和useradd创建需要的群组和用户
$ groupadd spark
$ useradd -g spark spark
使用passwd修改用户的密码:
$ passwd spark
分别修改所有的服务器
3.2 修改目录权限
$ chown -R spark:spark $SPARK_HOME
* 上面$SPARK_HOME是上述解压的目录路径
4. 启动Master节点(在Master节点执行)
4.1 切换用户
$ su - spark
4.2 执行以下命令启动Master
$ sbin/start-master.sh
* 默认是在当前服务器启动Master节点,服务端口是7077,web UI端口是8080
* 如果出现如下信息证明启动成功,或者查看日志文件
- $ sbin/start-master.sh -h
- starting org.apache.spark.deploy.master.Master, logging to /xxx/spark-2.1.0-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.master.Master-1-x.out
$ sbin/start-master.sh -h
starting org.apache.spark.deploy.master.Master, logging to /xxx/spark-2.1.0-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.master.Master-1-x.out4.3 查看Master状态
访问http://masterip:8080/ 可以查看状态,masterip是Master节点的ip
4.4 启动参数
-h HOST, --host HOST master节点主机名或ip
-p PORT, --port PORT 端口,master默认7077,worker随机生成
--webui-port PORT web UI端口,master默认8080,worker默认8081
-c CORES, --cores CORES 允许使用的CPU核数,默认是系统可用数量,只适用于worker节点
-m MEM, --memory MEM 允许使用的内存,格式为例如1000M、2G,默认是系统总内存减1GB,只适用于work节点
-d DIR, --work-dir DIR 临时工作和任务日志输出目录,默认是$SPARK_HOME/work目录,注意需要修改权限,只适用于work节点
--properties-file FILE Spark properties文件路径,默认是$SPARK_HOME/conf/spark-default.conf
5. 启动Worker节点(分别在各Worker节点执行)
5.1 执行以下命令启动Worker
$ su - spark
$ sbin/start-slave.sh spark://HOST:PORT
* spark://HOST:PORT是Master节点的ip和端口
* 如果出现如下信息证明启动成功,或者查看日志文件
- $ sbin/start-slave.sh spark://xxx:7077
- starting org.apache.spark.deploy.worker.Worker, logging to /xxx/spark-2.1.0-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.worker.Worker-1-x.out
$ sbin/start-slave.sh spark://xxx:7077
starting org.apache.spark.deploy.worker.Worker, logging to /xxx/spark-2.1.0-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.worker.Worker-1-x.out5.2 查看Worker状态
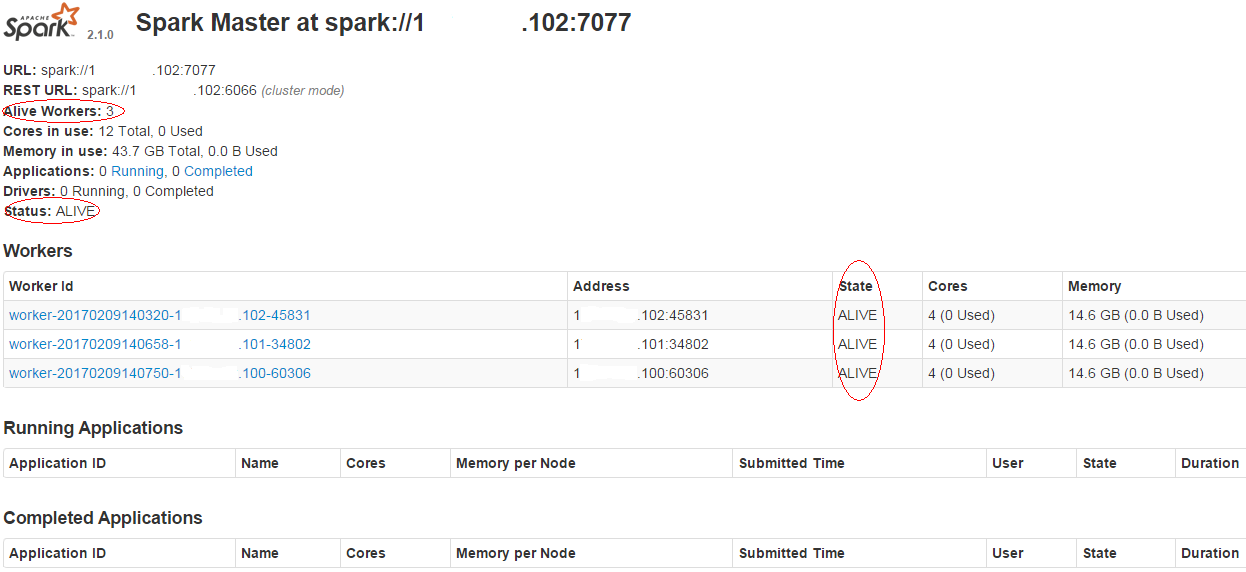
访问http://masterip:8080/ 可以查看各Worker的状态,masterip是Master节点的ip
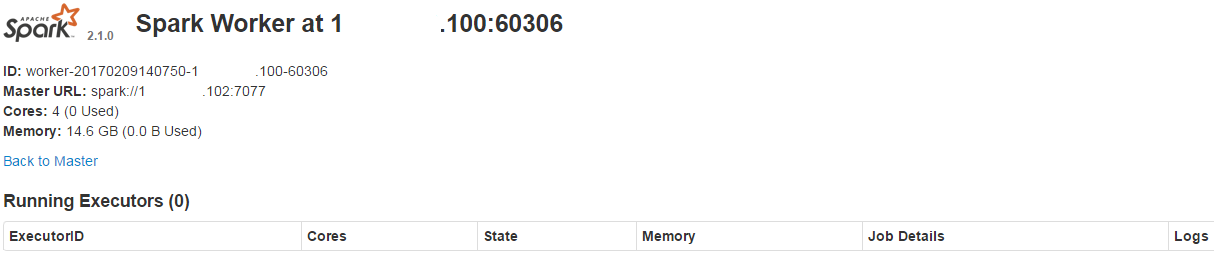
访问http://workip:8081/ 可以查看对应Worker的状态,workip是对应Worker节点的ip
6.测试提交一个Spark的Job
6.1 执行下面命令提交一个计算Pi的任务
- $ su - spark
- $ export SPARK_HOME=/xxx/spark-2.1.0-bin-hadoop2.7
- $ ./bin/spark-submit \
- --class org.apache.spark.examples.SparkPi \
- --master spark://masterip:7077 \
- $SPARK_HOME/examples/jars/spark-examples_2.11-2.1.0.jar \
- 1000
$ su - spark
$ export SPARK_HOME=/xxx/spark-2.1.0-bin-hadoop2.7
$ ./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://masterip:7077 \
$SPARK_HOME/examples/jars/spark-examples_2.11-2.1.0.jar \
1000* masterip是对应的Master节点ip
屏幕最后类似输出下面的结果
- ..........
- 17/02/09 14:27:03 INFO DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 18.632662 s
- Pi is roughly 3.141567911415679
- ..........
..........
17/02/09 14:27:03 INFO DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 18.632662 s
Pi is roughly 3.141567911415679
..........6.2 访问http://masterip:8080/ 可以查看完成任务的情况,masterip是Master节点的ip

点击Application ID的连接可以查看参与计算的Worker和各自的执行日志

点击stderr的连接查看对应worker的运行日志

7. 停止Master和所有Worker节点
7.1 分别在各Worker节点执行下面命令停止Worker
- $ su - spark
- $ sbin/stop-slave.sh
- stopping org.apache.spark.deploy.worker.Worker
$ su - spark
$ sbin/stop-slave.sh
stopping org.apache.spark.deploy.worker.Worker7.2 访问http://masterip:8080/ 可以查看各Worker的状态,masterip是Master节点的ip,这时应该是DEAD状态

7.3 在Master节点执行下面命令停止Master
- $ su - spark
- $ sbin/stop-master.sh
- stopping org.apache.spark.deploy.master.Master
$ su - spark
$ sbin/stop-master.sh
stopping org.apache.spark.deploy.master.Master8. 使用集群脚本启动和停止Master和所有Worker
8.1 可用的脚本有
- sbin/start-all.sh 启动master和所有worker节点
- sbin/start-slaves.sh 启动所有worker节点
- sbin/stop-all.sh 停止master和所有worker节点
- sbin/stop-slaves.sh 停止所有worker节点
8.2 配置SSH无密码登录验证
8.2.1 在Master节点切换到spark用户
- $ su - spark
- $ pwd
- /home/spark
$ su - spark
$ pwd
/home/spark8.2.2 执行以下命令在spark用户的主文件夹生成密钥和加入授权
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 600 ~/.ssh/authorized_keys
- $ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
- Generating public/private rsa key pair.
- Your identification has been saved in /home/spark/.ssh/id_rsa.
- Your public key has been saved in /home/spark/.ssh/id_rsa.pub.
- The key fingerprint is:
- SHA256: xxxxxx spark@node3
- The key's randomart image is:
- +--[ RSA 2048]----+
- | xxx |
- +-----------------+
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
Generating public/private rsa key pair.
Your identification has been saved in /home/spark/.ssh/id_rsa.
Your public key has been saved in /home/spark/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256: xxxxxx spark@node3
The key's randomart image is:
+--[ RSA 2048]----+
| xxx |
+-----------------+8.2.3 把生成的授权文件复制到其余的Worker节点服务器,用于在Master可以通过start-all.sh或start-slaves.sh启动所有Worker节点
$ scp ~/.ssh/authorized_keys spark@xxx.101:/home/spark/.ssh/
$ scp ~/.ssh/authorized_keys spark@xxx.102:/home/spark/.ssh/
注意,如果目标服务器的authorized_keys文件是非空的,需要复制生成的授权文件文本追加到目标服务器的authorized_keys文件,否则原文件会被覆盖
- $ scp ~/.ssh/authorized_keys spark@xxx.101:/home/spark/.ssh/
- The authenticity of host 'xxx (xxx)' can't be established.
- RSA key fingerprint is xxxxxx.
- Are you sure you want to continue connecting (yes/no)? yes
- Warning: Permanently added 'xxx' (RSA) to the list of known hosts.
- spark@node2's password: (此处输入被访问服务器的密码)
- authorized_keys 100% 397 0.4KB/s 00:00
$ scp ~/.ssh/authorized_keys spark@xxx.101:/home/spark/.ssh/
The authenticity of host 'xxx (xxx)' can't be established.
RSA key fingerprint is xxxxxx.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'xxx' (RSA) to the list of known hosts.
spark@node2's password: (此处输入被访问服务器的密码)
authorized_keys 100% 397 0.4KB/s 00:008.3 在Master节点修改$SPARK_HOME/conf/slaves文件,添加所有worker的ip
xxx.100
xxx.101
xxx.102
8.4 执行下面命令启动Master和所有Worker
$ sbin/start-all.sh
- starting org.apache.spark.deploy.master.Master, logging to /xxx/spark-2.1.0-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.master.Master-1-x.out
- xxx.100: starting org.apache.spark.deploy.worker.Worker, logging to /xxx/spark-2.1.0-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.worker.Worker-1-x.out
- xxx.101: starting org.apache.spark.deploy.worker.Worker, logging to /xxx/spark-2.1.0-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.worker.Worker-1-x.out
- xxx.102: starting org.apache.spark.deploy.worker.Worker, logging to /xxx/spark-2.1.0-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.worker.Worker-1-x.out
starting org.apache.spark.deploy.master.Master, logging to /xxx/spark-2.1.0-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.master.Master-1-x.out
xxx.100: starting org.apache.spark.deploy.worker.Worker, logging to /xxx/spark-2.1.0-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.worker.Worker-1-x.out
xxx.101: starting org.apache.spark.deploy.worker.Worker, logging to /xxx/spark-2.1.0-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.worker.Worker-1-x.out
xxx.102: starting org.apache.spark.deploy.worker.Worker, logging to /xxx/spark-2.1.0-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.worker.Worker-1-x.out访问http://masterip:8080/ 可以查看Master和各Worker的状态,masterip是Master节点ip
8.5 执行下面命令停止Master和所有Worker
$ sbin/stop-all.sh
- xxx.100: stopping org.apache.spark.deploy.worker.Worker
- xxx.101: stopping org.apache.spark.deploy.worker.Worker
- xxx.102: stopping org.apache.spark.deploy.worker.Worker
- stopping org.apache.spark.deploy.master.Master
xxx.100: stopping org.apache.spark.deploy.worker.Worker
xxx.101: stopping org.apache.spark.deploy.worker.Worker
xxx.102: stopping org.apache.spark.deploy.worker.Worker
stopping org.apache.spark.deploy.master.MasterEND...O(∩_∩)O















 1726
1726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









