








 超级会员免费看
超级会员免费看

在上一篇文章中使用了梯度下降算法来实现了自适应线性神经元。我们在更新权重的时候都有使用到学习率,并且默认的将学习率设置为了0.01,那么我们将学习率设置成0.01合适吗?在使用梯度下降算法,我们是直接将花的特征和花所对应的标签作为输入和输出,而没有进行数据的预处理操作,这对训练的模型会有什么影响呢?这篇文章中,我们主要讨论一下,学习率以及数据的预处理对于模型的影响。
一、学习率对于模型的影响
学习率过大或者过小对于模型的收敛都会有一定的影响,如果学习率设置的过大可能会导致模型无法收敛,如果当迭代的次数足够大的时候,还可能会导致因为代价函数的损失值太大造成内存溢出。如果,学习率设置的过小会导致,模型的收敛速度太慢,从而我们需要提高模型的迭代次数,才能使模型收敛,这样会造成对硬件资源和时间的浪费。下面,通过使用梯度下降算法对鸢尾花进行分类,使用学习率为0.01和学习率为0.0001,迭代次数设置为10
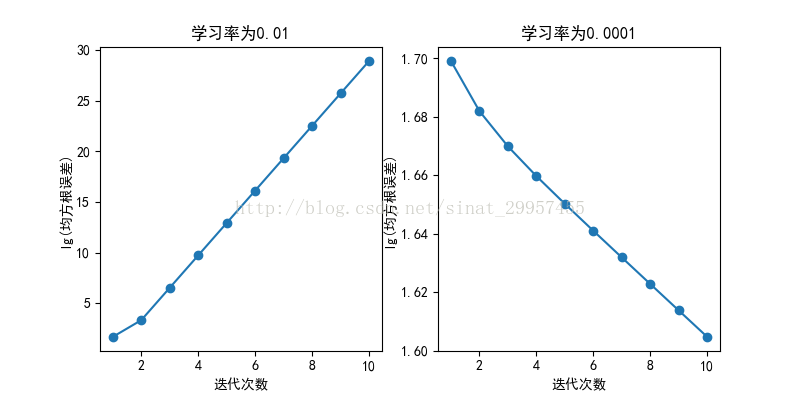
x轴是迭代的

 订阅专栏 解锁全文
订阅专栏 解锁全文
















 579
579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











