







论文原文:Learning Paraphrastic Sentence Embeddings from Back-Translated Bitext
引言
这篇文章的目的是学习句子表示,在产生模型的训练集时作者所采用的方法很有意思,作者利用训练好的机器翻译模型将原数据集中非英语的句子翻译成英语,从而和原数据集的英语句子组成意义相近的句子对,得到大量的训练数据,通过这些训练数据训练学习句子表示的模型,作者的实验表明,使用这些数据训练得到的模型能取得不错的效果。另外,由于通过这样的方式得到的训练集数量很大,作者还设计了一些过滤方法来挑选训练集。
Neural Machine Translation models
作者使用了Groundhog框架训练了3个encoder-decoder NMT模型:
Czech->English
French->English
German->English
使用的训练数据如下:
| 数据集名称 | Czech | French | German |
|---|---|---|---|
| Europarl | 650000 | 2000000 | 2000000 |
| Common Crawl | 160000 | 3000000 | 2000000 |
| News Commentary | 150000 | 200000 | 200000 |
| UN | - | 12000000 | - |
| 109 French→English | - | 22000000 | - |
| CzEng | 14700000 | - | - |
训练好的NMT模型的BLEU分数(WMT2015测试集)如下:
| Language | %BLEU |
|---|---|
| Czech→English | 19.7 |
| French→English | 20.1 |
| German→English | 28.2 |
在完成NMT模型的训练后,作者将模型训练所用句子对中非英语的那个句子,直接使用模型翻译成英语,从而形成了意思相近的英语句子对,以此作为后续句子表示模型训练的数据集。
作者展示了一些通过上述过程产生的英语句子对:
| References(R) | Back-translations(T) |
|---|---|
| We understand that has already commenced, but there is a long way to go. | This situation has already commenced, but much still needs to be done. |
| The restaurant is closed on Sundays. No breakfast is available on Sunday mornings. | The restaurant stays closed Sundays so no breakfast is served these days. |
| Improved central bank policy is another huge factor. | Another crucial factor is the improved policy of the central banks. |
其中R表示原句,T表示通过X-English NMT模型翻译的结果,可以看到效果是不错。这让我想到本科查重,有同学说的方法是把中文用Google翻译成英文再翻译回中文。: )
模型
通过上一节,作者得到了茫茫多的句子对数据集,在这部分将介绍如何训练学习句子表示的模型。作者的目标是把上一节得到是数据集与其他数据集进行比较,看看哪个数据集训练出的模型能学习得到更好的句子表示。
作者选择了2个模型进行训练,分别是AVG和GRAN。
AVG
AVG模型就是讲句子s中每个单词对应的词向量进行加和平均得到句子表示。
AVG(s)=1|s|∑xi∈sW(xi)
GRAN
GRAN模型也是本文作者今年的一个工作,模型的全称是GATED RECURRENT AVERAGING NETWORK,可以关注一下,不再赘述。
训练
训练数据是有茫茫多相似句子对的集合。
训练采用的损失函数如下:
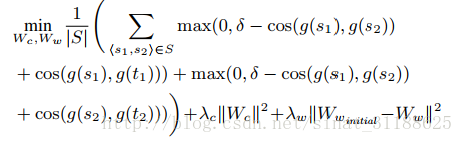
实验
1 评估用的数据集
a. 2012-2015 SemEval semantic textual similarity (STS) tasks
b. the SemEval 2015 Twitter task
c. the SemEval 2014 SICK Semantic Relatedness task
在计算句子相似度时,作者直接计算了句子向量的余弦相似度。
2 实验结果
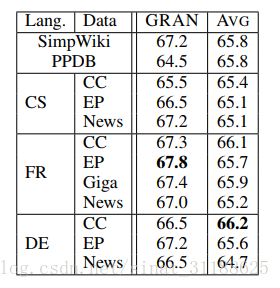
作者从每个语料库中挑选了24000个句子对作为训练集,表中展示的是在22个STS句子相似性任务中的平均pearson相关系数。
Filtering Methods
这部分没有仔细看,就不写了。
总结
之前看过这个作者的其他文章,确实很有意思。这篇文章的想法让人眼前一亮。外国人是厉害呀。
2017.10.11于上海。














 6818
6818











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









